- 우리는 앞장에서 불확실성을 정량화시키고 일관된 수학적 프레임워크를 구성하는 과정을 살펴보았다.
- 이제 Decision 이론을 이용하여 확률 이론을 바탕으로 불확실성이 관여된 상황에서의 최적의 결정 과정을 살펴볼 것이다.
목표 : 입력 \( {\bf x} \) 와 이에 대한 타겟 \( {\bf t} \) 를 이용하여 새로운 변수 \( x_{new} \) 에 대응하는 타겟 값 \( t_{new} \) 를 예측할 수 있다.
- 앞선 예제와 다르게 \({\bf t}\) 가 벡터인 이유는 특정 클래스의 label을 의미하는 것으로 사용되었기 때문이다.
- 결합 확률(joint probabilty)을 이용하여 이에 대한 정보를 표현한다. : \( p({\bf x}, {\bf t}) \)
- 학습 데이터로부터 \( p({\bf x}, {\bf t}) \) 를 결정하는 것은 일종의 추론 과정인데 사실 쉽지 않은 문제이다.
- 이 책은 대부분 이 문제에 대한 해결방법을 다룬다.
- 추론의 문제, 즉 \( p({\bf x}, {\bf t}) \) 를 결정하는 문제는 불확실성에 대한 상황을 확률적 표현법으로 기술하는 과정을 포함한다.
- 그리고 이런 확률 정보를 바탕으로 최적의 결정을 만들어 내는 것이 바로 결정 이론(decision theory)의 주제.
- 보통 추론 과정이 끝나면 결정을 내리는 과정은 상대적으로 간단하다.
- 어쨌거나 여기는 1장이므로 간단한 개념만 살펴보고 실제적인 내용들은 4장 이후에 다시 다루게 된다.
- 확률값이 결정(decision) 과정에 어떤 영향을 주는지 살펴보자.
- 예를 들어 어떤 환자의 X-Ray 결과 \( x \) 가 주어졌을 때 \( t \) 는 환자의 암(cancer) 여부라 하자.
- 이 때 \( t \) 의 값이 \( C_1 \) 인 경우 암이고, \( C_2 \) 인 경우 암이 아님을 의미하게 된다.
- 따라서 관심있는 확률은 \( p(C_k | {\bf x}) \) 가 된다.
- 베이즈 룰에 기반한 모든 확률식은 결합(joint) 확률 \( p({\bf x}, C_k) \) 를 주변화(marginalize) 하거나 조건화(conditioning)시켜 얻을 수 있다.
- \( p(C_k) \) 는 클래스 \( C_k \) 의 사전(prior) 확률 함수, \( p(C_k|{\bf x}) \) 는 사후(posterior) 확률 함수.
- 우리의 목적은 잘못된 선택을 하게될 가능성을 줄이는 것 (암이 아닌데 암이라고 선택, 암인데 암이 아니라고 선택)
- 따라서 직관적으로 사후(posterior) 확률이 높은 클래스를 선택하는 문제로 귀결된다. (이런 직관은 꽤나 타당하다)
- 역시나 교재에서의 설명은 너무나 간략한 편인데 이에 대한 유사한 문제들은 다른 교재에서 많이 언급되므로 쉽게 이해 가능하긴 하다.
1.5.1. 오분류 최소화 (Minimizing the misclassification rate)
- 앞서 언급했듯 우리의 목적은 어찌보면 잘못된 분류 가능성을 최대한 줄이는 것
- 따라서 모든 \( x \) 에 대해서 특정 클래스로 할당시키는 규칙이 필요하게 된다.
- 이런 규칙은 결국 입력 공간을 각 클래스별로 나누게 되는 효과를 가지게 된다.
- 이렇게 나누어진 구역을 decision region 이라 하고 \( R_k \) 로 표기한다.
- 이 때 각 구역의 경계면을 decision boundaries 또는 decision surface 라고 부른다.
- 한국말로는 결정면, 결정경계 등으로 부르면 될 듯 하다.
- 다시 잘못 분류될 가능성을 생각해보면, 이것 또한 하나의 확률 식으로 표현 가능하다 하겠다.
- 위의 식은 오분류될 확률 값을 모두 합한 확률로, 이를 최소화하는 방향으로 모델을 설계해야 한다.
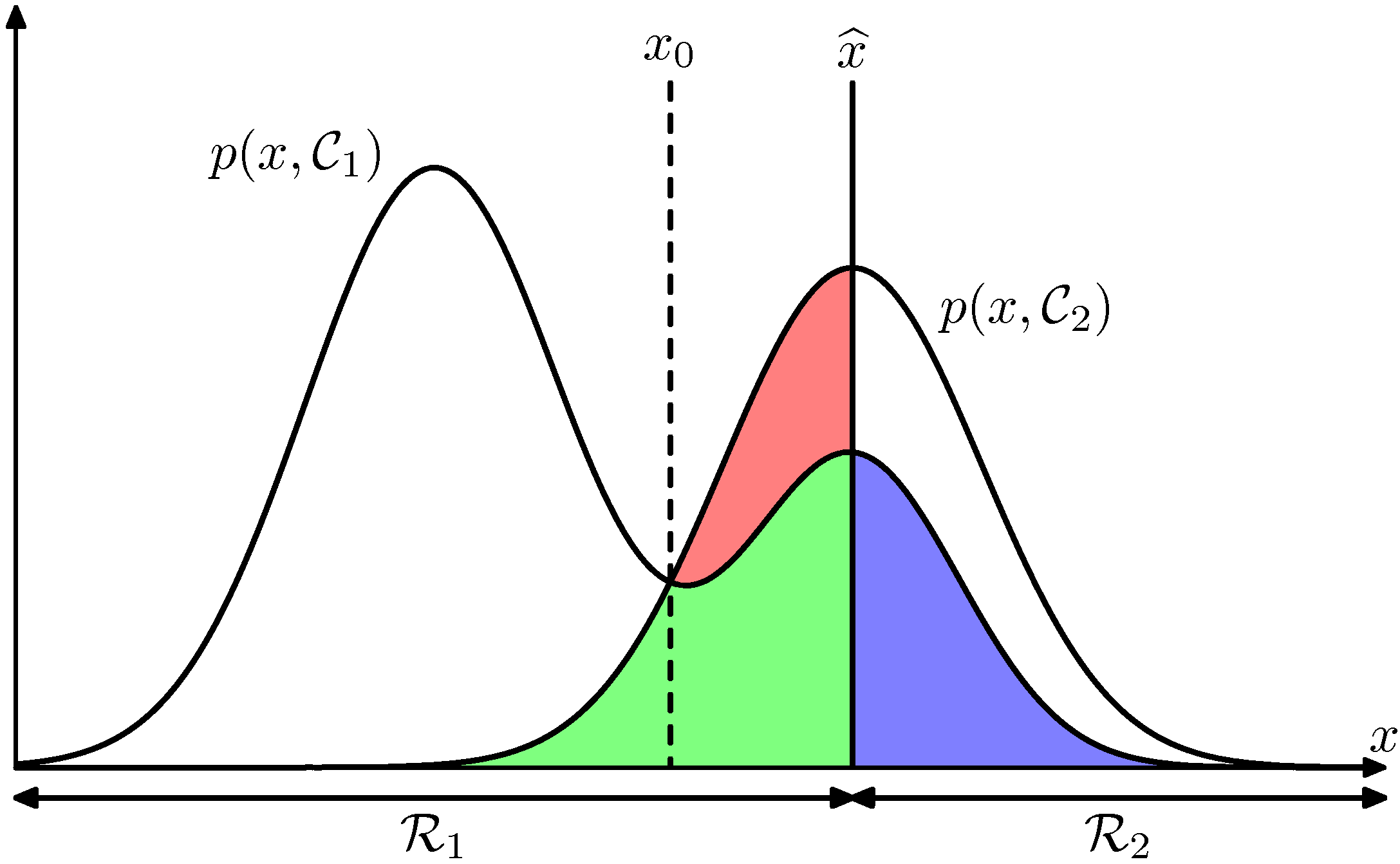
- 그림에서 우리는 현재 클래스의 구분선을 \( \widehat{x}\) 로 결정했다고 하자.
- 그러면 \( x\ge\widehat{x} \) 인 영역에서는 해당 클래스가 \( C_2 \) 로 결정된다. (반대인 경우 \( C_1 \) 으로 할당됨)
- 이렇게 하면 에러의 합은 청색, 녹색, 적색이 된다.
- 이를 최소화하는 영역으로 기준 선이 변경되어야 한다.
- 만약 \( \widehat{x} \) 를 왼쪽으로 이동하면 녹색 + 청색의 면적은 그대로 유지되지만 적색의 영역은 변화된다.
-
따라서 면적을 최소화하는 방법은 \( \widehat{x}=x_0 \) 인 지점이다.
- 오분류될 확률값을 최소화하는 방향으로 식을 전개해도 되지만,
- 반대로 제대로 분류될 확률값을 최대화하는 형태로 식을 전개해도 문제는 없다.
1.5.2. 기대 손실 최소화 (Minimizing the expected loss)
- 앞서 설명한 내용이 문제가 되는 점은 없지만 현실적으로 오분류(misclassification)의 수를 줄이는 것만으로는 뭔가 부족하다.
- 예를 들어 암(cancer) 진단 예제에서의 오분류 경우를 생각해보자.
- case.1 : 암이 아닌데 암인 것으로 진단
- case.2 : 암이 맞는데 암이 아닌 것으로 진단
- 첫번째 경우보단 두번째 경우가 더 심각한 것인데, 따라서 모델에 이러한 정보도 좀 반영이 되면 좋겠다 싶다.
- 예를 들면 두번째 경우에 패널티를 한 1000배 쯤 주고싶다고 할 수도 있겠다.
-
이제 새로운 개념이 등장한다. 바로,
- Loss function (known as Cost function)
- 단순히 오분류 개수만 세는 것이 아니라 Loss라는 개념을 정의하고 이를 최소화하는 방법을 생각하자.
- 이를 통해 가능한 결정이나 행동들을 조금 더 능동적으로 조절할 수 있다.
- 어떤 사람들은 utility function 이라는 것을 도입해서 이 값을 최대화하는 문제로 처리하곤 하는데, 사실 이것은 loss 함수에 음수를 붙여 처리하는 것과 다를 바 없다.
- 개념은 간단하다. 하나의 샘플 \( x \) 가 실제로는 특정 클래스 \( C_k \) 에 속하지만 우리가 이 샘플의 클래스를 \( C_j \) 로 선택할 때 (즉, 잘못된 선택을 할 경우) 들어가는 비용을 정의한다.
- 모든 경우에 대한 Loss 값을 정의한 행렬을 Loss 행렬이라고 한다.
- 실제 Loss 함수를 최소화하는 방법은 Loss 함수에 대한 평균값을 최소화하는 방법을 사용한다.
- 이 식 자체를 그냥 에러 함수로 정의해서 사용하면 된다. (앞절에서는 최소제곱합을 에러 함수로 사용했다.)
- 여기서 \( x \) 는 반드시 하나의 \( R_j \) 에 포함되게 된다.
- 따라서 우리는 에러 값이 최소가 되는 \( R_j \) 를 선택하여야 한다.
- 결국 \( x \) 에 대해 \( \sum_{k}L_{kj}p({\bf x}, C_k) \) 를 최소화하는 클래스를 찾으면 된다.
- \( p({\bf x}, C_k) = p(C_k | {\bf x})p({\bf x}) \) 로 치환 가능하고, \( p({\bf x}) \) 는 클래스마다 동일하다고 생각하고 생략한다.
- 새로운 \( x_{new} \) 가 들어왔을 때, 이 식을 이용하면 된다.
1.5.3. 리젝트 옵션 (The reject option)
- 본문에 자세히 언급된 부분은 아니므로 간단하게만 정리하자.
- 사후 확률 \( p(C_k | {\bf x}) \) 또는 결합 확률 \( p({\bf x}, C_k) \) 가 1에 가까운 값이 아니라 클래스별로 비슷한 경우 이 \( x \) 에 대해 분류에 대한 에러는 커지기 마련이다.
- 이러한 범위에 존재하는 \( x \) 에 대해 특정한 클래스로 할당을 하는 것이 부담이 될 수도 있는데, 이런 경우 결정을 회피하는 기능을 reject option 이라고 한다.
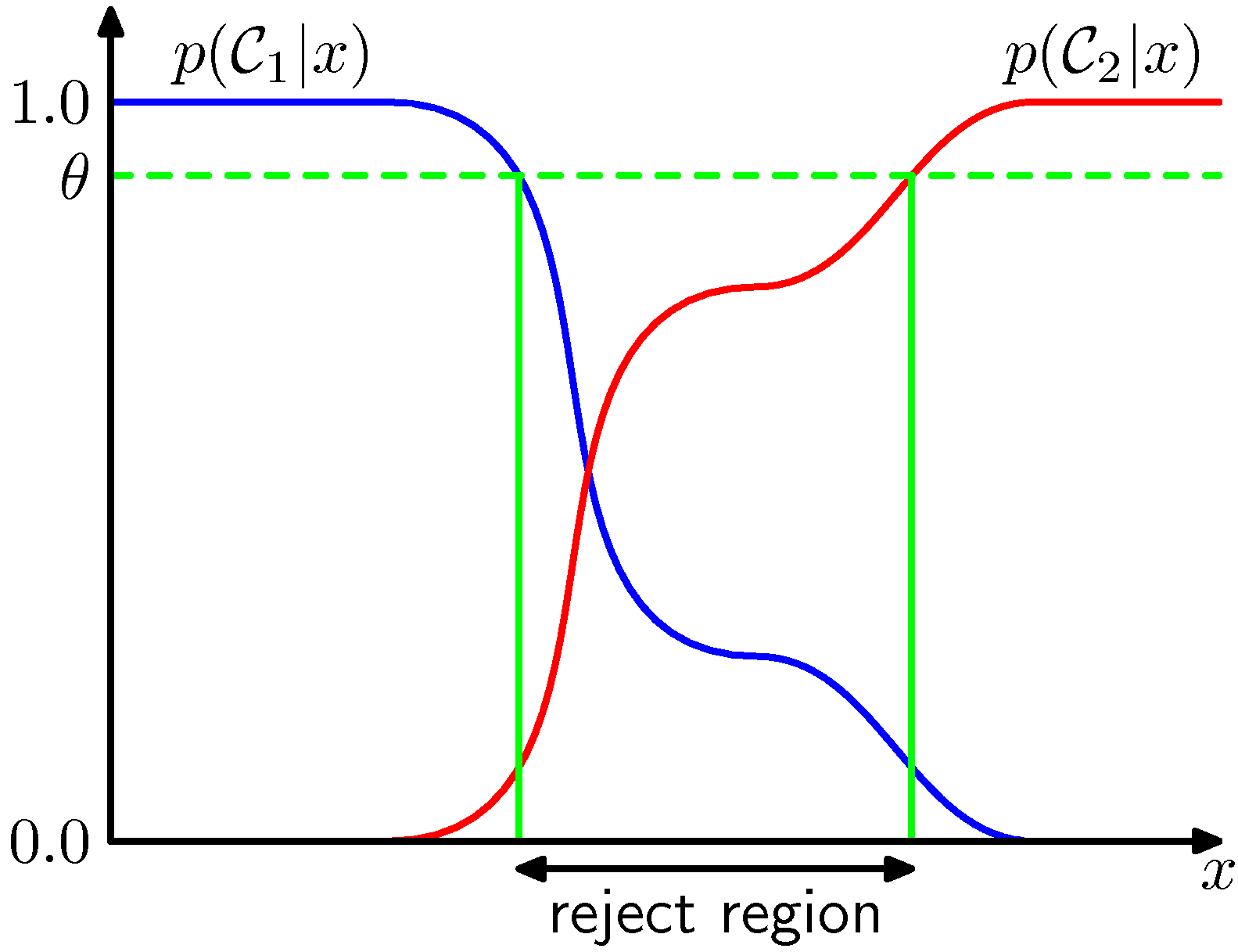
- 그림을 보면 쉽게 이해가 되는데, 사후 확률 값이 특정 수준(threshold)에 미치지 못하면 클래스 분류를 보류하는 것이다.
- 위의 그림에서는 확률 값 \( \theta \) 를 기준으로 이것보다 더 낮은 확률 값을 가지는 사후 확률 범위들을 reject region 으로 지정한다.
- 여기서는 2-class 문제만을 다루고 있으며, K class 문제에서는 \( \theta \) 값을 보통 \( \frac{1}{K} <= \theta < 1 \) 로 고려한다. - 만약 \( \theta == 1 \) 인 경우에는 모든 데이터가 reject 된다. - K 클래스 문제에서는 \( \theta < \frac{1}{K} \) 인 경우 어떠한 데이터도 reject되지 않는다.
- reject option 은 기대 손실(expected loss)을 최소화하는 경우에도 쉽게 응용이 가능하다.
1.5.4. 추론과 판별 (Inference and decision)
- 우리는 지금까지 크게 2가지 영역으로 나누어 분류의 문제를 다루었다.
- 추론(inference) : 학습 데이터를 이용하여 \( p(C_k | {\bf x}) \) 에 대한 모델을 학습
- 판별 (decision) : 추론한 사수 확률 분포를 이용하여 실제 입력된 데이터의 클래스를 결정
- 클래스 판별 문제는 사실 크게 3가지 방법으로 나눌 수 있다. 복잡도가 높은 것부터 설명하자면,
(a) Generative Models
- 클래스-조건부 밀도(class-conditional density)인 \( p({\bf x}|C_k) \) 와 사전 확률 \( p(C_k) \) 를 각각 추론하여 사후 확률을 추론하거나,
- 결합 확률 \( p({\bf x}, C_k) \) 의 주변화(marginalizing) 과정을 통해 사후 확률을 얻게 된다.
- 이름이 Generative 모델인 이유는 추론된 분포로 부터 임의적으로 새로운 데이터를 만들어낼 수 있기 때문이다.
- 즉, 주어진 데이터를 통해 모델링된 분포로부터 완전히 새로운 샘플들을 재생성해 낼 수 있는 능력이 있다.
- 모델이 개떡같이 추론되었다면 재샘플링 데이터가 원래 데이터와 유사하지 않을 가능성은 당연히 높음
(b) Discriminative Models
- 사후 확률(posterior)를 직접 근사하는 모델이다.
- 앞서 설명한 Generative 모델은 사후 확률을 직접 구하는 것이 아니라 클래스-조건부 밀도와 사전 확률로 구분하여 간접적으로 추론을 하는 과정을 거쳤다.
- 여기서는 직접적인 방법으로 해당 확률을 모델링한다.
- 우선 이런게 있다고만 알고 이후에 4장을 참고하도록 한다.
(c) Discriminant Function
- 용어에 discriminant 가 들어가 있다고 해서 앞의 방식과 유사할 것이라 생각할 수도 있지만 전혀 그렇지 않다.
- 베이즈 확률 모델에 의존하지 않고 입력 공간을 바로 결정 모델에 대입하여 판별식을 찾아내는 방식이다.
- 즉, 확률을 다루지 않으므로 사후 확률 등을 따지지 않는다.
- 모두 다 4장에서 다시 자세하게 설명하고 있으니 걱정하지 않아도 된다.
-
그냥 넘기기에는 좀 아쉽기 때문에 아주 간단히만 살펴보자.
- (a). Generative model
- 입력 공간의 차원이 증가할 수록 좀 더 정확한 클래스-조건부 밀도를 구하기 위한 많은 샘플이 필요
- 클래스에 대한 사전 확률 값은 샘플 수를 세기만 하면 되므로 상대적으로 구하기 쉬움
- 새로운 데이터가 입력되었을 때 추정된 모델로부터 확률 값을 예측할 수 있으므로 낮은 확률값 등을 보고 이상치(outlier)를 확인할 수 있다.
- 명시적, 암묵적으로 \( p(x) \) 의 분포를 모델링하게 된다.
- (b). Discriminative model
- 사후 분포를 바로(direct) 추론한다.
- 아래 그림을 보면 왼 쪽에 표기된 클래스-조건부 밀도는 상대적으로 복잡한데, 오른쪽 사후 분포는 매우 간단하다.
- 즉, 클래스-조건부 밀도가 사후 분포에 그리 영향을 주지 않는다.
- 이 경우에는 바로 사후 분포를 찾는게 더 편할 수 있다.
- 클래스-조건부 밀도가 뭔지는 4장에 자세히 나온다.
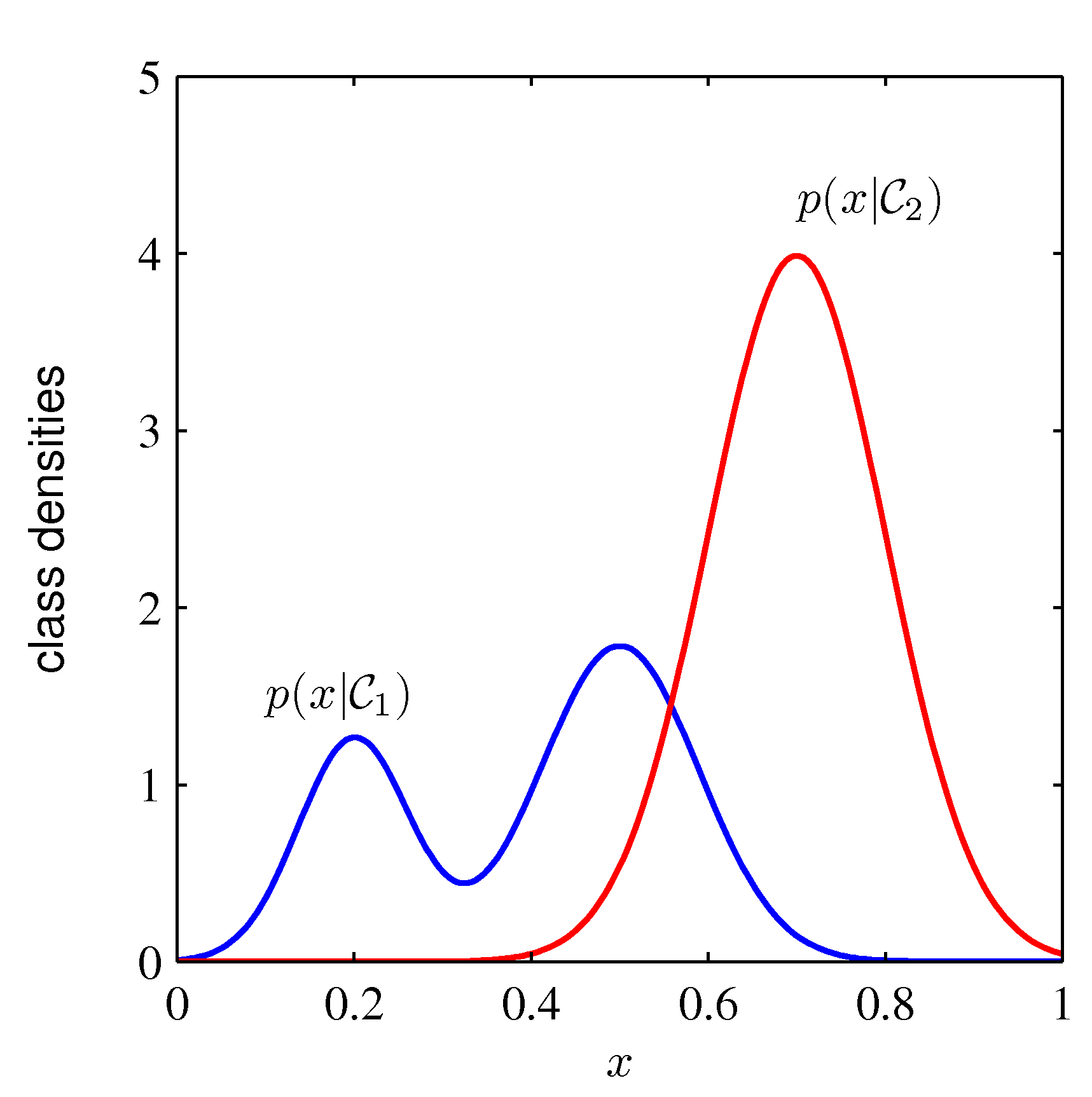
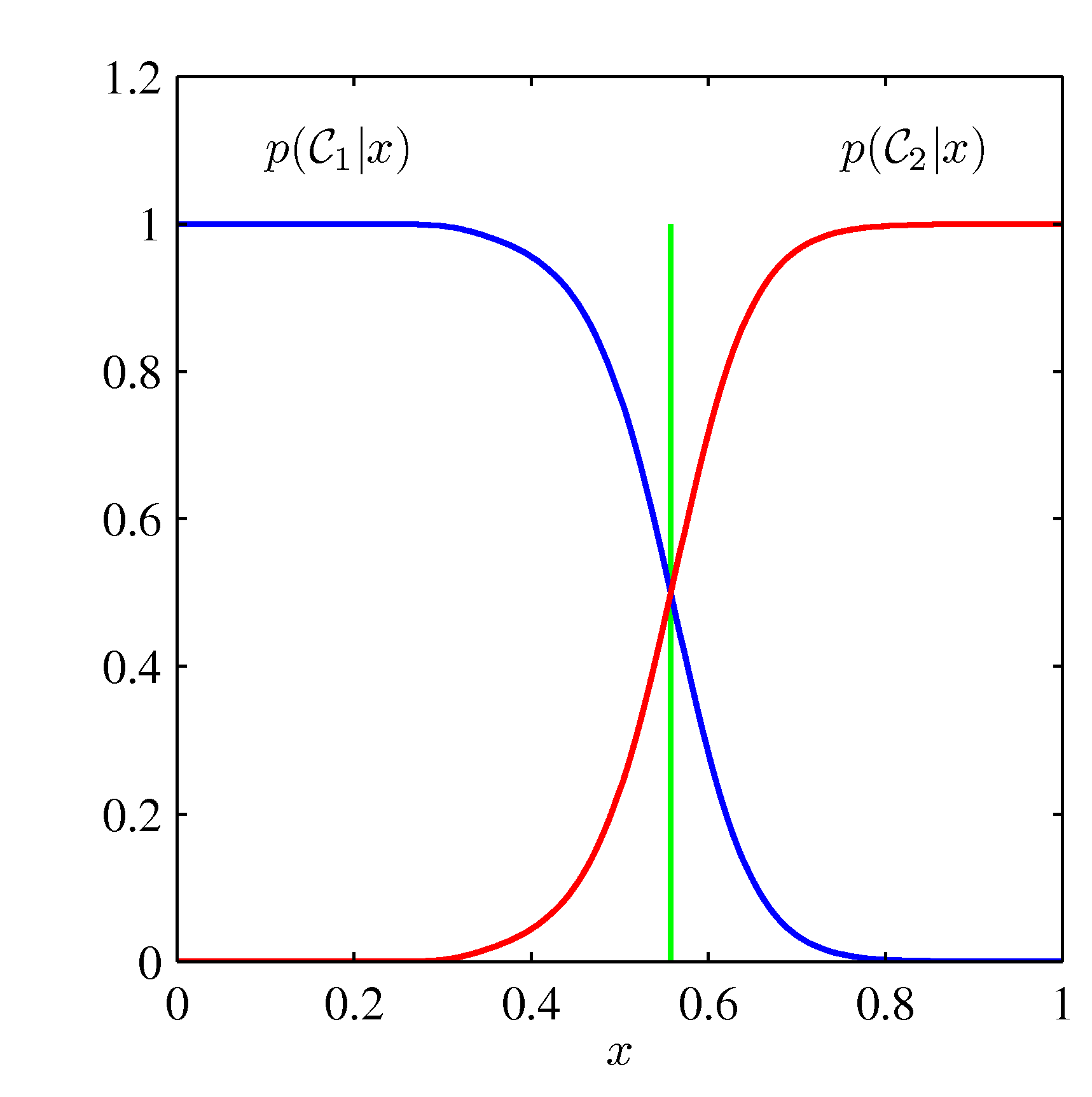
- (c). Discriminant function
- 입력 공간을 결정 공간에 바로 매핑시키는 방식이다.
- 위의 그림에서 녹색 선에 해당하는 방식이다. (이걸 바로 찾는다)
- 확률을 다루지 않으므로 사후 확률 등을 추정하지 않는다.
- (a)와 (b) 에서는 사후 확률을 주요하게 다루고 있으나 (c)는 그렇지 않다.
- 하지만 (c) 와 같은 방식을 사용하더라도 여전히 사후 확률을 예측하는 것은 큰 의미가 있다.
- 사후 확률 분포를 활용하는 벙법에 대해서는 간단히 언급만 하고 넘어가도록 한다.
- Minimizing Risk
- 앞서 살펴본 Loss 행렬이 고정된 값이 아니라 시간에 따라 바뀔 수 있다고 생각해보자.
- 만약 우리가 사후 확률을 알고 있다면 이를 쉽게 응용할 수 있다.
- Reject Option
- 분류 선택을 유보할 수 있는 영역을 만들 수 있다. 앞 절에서 살펴봤다.
- Compensating for class priors
- 보통 업데이트 방식의 확률 모델에서 베이지안 이론을 사용하는 경우, 얻어진 사후 확률을 다시 사전 확률로 가정하여 새로운 데이터에 대해 적용 가능함.
- 이런 방식은 이후 베이지안 방식에서 다루게 될 것이다.
- Combining models
- 보통 복잡한 문제는 좀 더 작은 문제로 나누어 해결하고 조합하는 방식이 선호됨
- 확률 모델에서도 좀 더 간단한 모델을 취하고 싶은 경우, 각각의 요소들을 독립적이라 가정하고 식을 전개하게 된다.
- 이런 모델을 조건부 독립이라고 한다.
- 사후 분포를 이용한 식도 이와 마찬가지로 전개가 가능하다.
- 하나의 어려운 결합 확률을 구하지 말고 모델링이 쉬운 두 개의 사후 확률을 구해 이를 결합하자는 것
- 아래 식을 참고하면 된다.
1.5.5. 회귀를 위한 손실 함수 (Loss functions for regression)
- 지금까지 분류(classification)를 위한 결정 이론을 살펴보았다.
- 이제 다시 맨 처음에 다루었던 회귀(regression) 문제로 돌아가보자.
- 회귀 문제는 분류를 하는 것이 아니라 실수인 타겟 값을 예측하는 것이다.
- 회귀 문제에서의 기대 손실 함수(expected loss function)도 한번 정의를 해보자.
- expected loss : 주어진 데이터로부터 얻어진 손실 함수의 평균값
- 뜬금없이 왜 기대 손실 함수가 설명되는가? (즉, 손실 함수의 평균)
- 이후 장부터 대부분 모델에 대한 모수 추정을 위해 에러 함수를 정의하게 되는데,
- 최소제곱합(sum-of-square) 에러 대신 손실 함수(Loss function)를 도입하여 에러 함수를 정의한 뒤 해결하는 방식이다.
- 앞서 설명했던 손실 함수의 도입 이유와 동일하다.
- 이후에 기대 손실과 관련된 이야기가 종종 언급될 일이 있는데, 매번 설명하기 귀찮으니 이번 절에 그냥 기술한 듯 하다.
- 따라서 이후에 이와 유사한 식이 나오게 된다. (9장, 10장)
- 사실 위의 \( L \) 함수는 범함수(functional)로 임의의 함수 \( y \) 를 파라미터로 취하는 함수이다.
- 이 때 이 값을 최소화하는 \( y \) 를 구하게 되는 것이므로 함수 \( y \) 에 대한 미분식이 사용되게 된다.
- 즉, 변분 추론(variational inference)의 한 형태임. 그냥 이런 것으로도 생각할 수 있구나 하고 넘어가자.
- 어쨌거나 결과를 만족하는 가장 좋은 함수를 추정하게 된다는 것.
- 물론 평균 값을 사용하므로 언제나 가장 좋은 결과를 내는 함수를 선택하는 것은 아니다.
- 어쨌거나 계속 논의를 진행해보자.
- 앞서 살펴 보았던 Loss 함수는 사용자가 대충 정해서 사용했었다.
- 여기서는 어떤 함수에 대한 근사 문제로 처리해야 하므로 최소제곱합 에러를 손실함수로 그냥 정의해서 사용한다.
- 어폐가 있어 보이지만 정리해보자면 손실 함수라는 큰 개념이 우선 존재하고 여기에 이 손실 함수로 최소 제곱합 방식을 도입하는 것이다.
- 굳이 이렇게 할 필요가 있는가 의문이 들기도 하겠지만 이후에 수식 전개를 해보면 얻을 수 있는 직관(insight)이 조금 다르다.
- 어쨌거나 이런 방식을 취해서 손실 함수의 평균 값을 계산함.
- 설명한 대로 손실함수를 \( L(t_y({\bf x})) = \{y({\bf x})-t\}^2 \) 로 정의한다.
- 이제 기대 손실을 보자.
- 우리의 목표는 \( E[L] \) 을 최소화하는 \( y(x) \) 를 찾는 것이다. 우선은 이걸로 미분해보자.
- 기대 손실 함수를 에러 함수로 놓았다고 생각하면 된다.
- 이 식은 조건부 \( x \) 에 대한 \( t \) 값의 평균으로 나오는데 이것은 회귀(regression)의 결과와 동일하다. (당연하겠지!!)
- 아래 그림을 보면 좀 더 명확하게 이해할 수 있을 것이다.
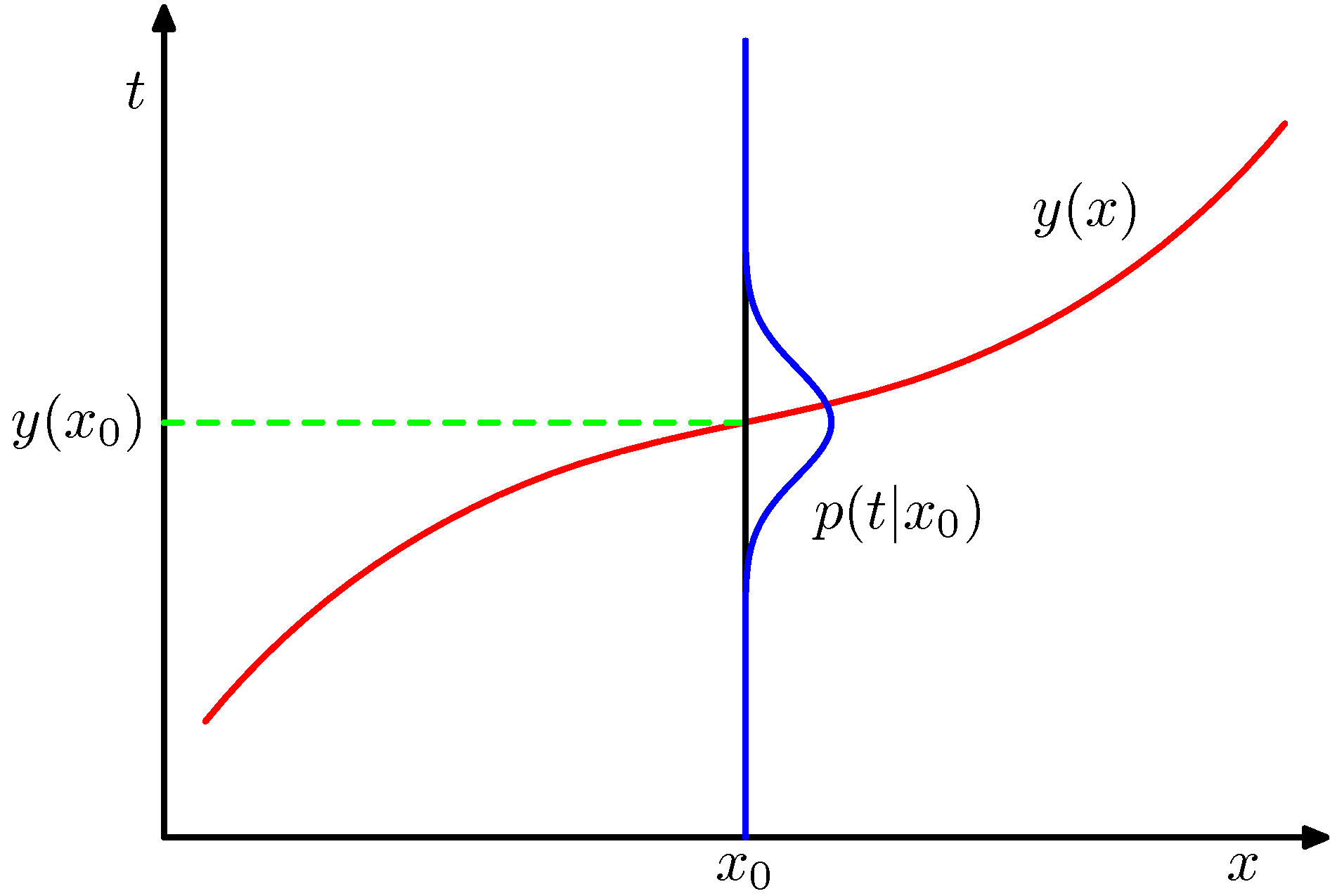
- 위의 그림은 \( t \) 가 1차원의 데이터이지만 \( N \) 차원 벡터로 출력되는 것도 가능하다. 이 경우 \( y({\bf x})=E_t[{\bf t}|{\bf x}] \) 가 될 것이다.
- 중요한 부분은 이렇게 얻어진 식은 수학적으로는 최적의 결과를 의미한다는 것이다.
- 하지만 현실적으로는 실제 가능한 모든 데이터 중 일부의 관찰 데이터만 얻는 것이므로 전체 데이터에 대한 실제 평균 값은 구하기 어렵다.
- 오로지 관찰 데이터의 평균 값만을 얻을 수 있음.
- 이것으로부터 직관(insight)을 좀 얻기위해 문제를 살짝 다른 관점에서 바라보도록 하자.
- 최초의 식에다가 \(E[t|{\bf x}] \) 값을 더하고 빼고 해서 식을 확장했다.
- 실제 같은 값을 더하고 빼기를 하면 0이 되므로 식에 영향을 주지는 못한다.
- 처음에는 이게 무슨 의미인지 혼동될 수도 있지만 천천히 생각해보면 그리 어렵지 않다.
- \( y({\bf x}) \) : 샘플 데이터로부터 만들어진 모델 함수로서 우리가 예측한 근사 식이라고 생각하면 된다.
- \( E[t|{\bf x}] \) : 앞서 언급하긴 했지만 이 값은 수학적으로 정답인 평균 값이다.
- 즉, 존재 가능한 모든 경우의 데이터를 확보하여 평균 값을 구하면 실제로 최적의 함수를 만들 수 있다.
- 하지만 현실적으로는 (전체 데이터의 일부인) 샘플 데이터만 주어지게 되고, 샘플 데이터만으로 수학적으로 정답인 값은 추정되기 어렵다.
- 만약 샘플 데이터로부터 추정된 \(y({\bf x}) \) 식이 \(E[t | {\bf x}] \) 와 동일하다면 매우 훌륭하게 식을 추정한 것이 된다.
- 자 이제 위의 수식을 좀 정리해보자. (헤쳐 모여!)
- 최초 수식을 정리하면 위와 같이 2개의 요소로 나누어 질 수 있다. (자세한 전개 방식은 생략하도록 한다.)
- 앞서 이야기한대로 샘플 데이터로부터 추정된 \( y({\bf x}) \) 가 \( E[t|{\bf x}] \) 와 동일한 결과를 가진다면 첫번째 텀은 사라지고 두번 째 텀만 남게 된다.
- 사실 우리는 에러를 최소화하는 방향으로 식을 근사하기를 원하므로 \( y({\bf x}) \) 를 최대한 \( E[t|{\bf x}] \) 와 동일하게 되도록 만들고 싶어할 것이다.
- 하지만 여기서는 에러 를 구성하는 요소를 파악해 보기 위해 이런 번잡한 작업들을 진행해보고 있는 것이다.
- 위의 수식대로 설명해보자면 기대 손실(expected loss) 값은 크게 2가지 요소로 나누어 볼 수 있다는 것이다.
- 즉, 첫번째 텀은 모델 \( y({\bf x}) \) 와 관련된 요소로 조건부 평균을 통해 최소 제곱 방식을 사용하는 방식을 이미 살펴보았다.
- 두번째 텀은 분산으로서 샘플이 포함하고 있는 노이즈(noise)를 의미한다.
- 앞서 살펴 본 분류 방식에서도 최적의 결정을 내리기 위한 방법들을 살펴보았는데, 마찬가지로 회귀(regression)와 관련된 문제들도 이런 접근법을 생각해 볼 수 있다.
- (a) 결합 확률 \( p({\bf x}, t) \) 를 추론하는 방법. 이 식을 정규화하기 위해 조건부 밀도 \( p(t|{\bf x}) \) 를 구하고 최종적으로 \( y({\bf x}) \) 를 구한다.
- (b) 조건부 밀도 \( p(t|{\bf x}) \) 를 바로 구하고 이를 이용하여 \( y({\bf x}) \) 를 구한다.
- (c) 학습 데이터로부터 회귀 함수 \( y(x) \) 를 바로 구한다.
- 사실 이러한 방식은 앞서 언급한 분류 방식과 동일한 절차를 이용하여 구해진다.
- 다음으로 넘어가서,
- 앞서 우리는 Loss 함수로 squared-loss 를 사용했다.
- 하지만 꼭 이걸 사용해야 한다는 법은 없다. Loss 함수는 적절하게 판단해서 사용하면 되는 것을 이미 알고 있다.
- 따라서 다른 함수를 도입해 본다.
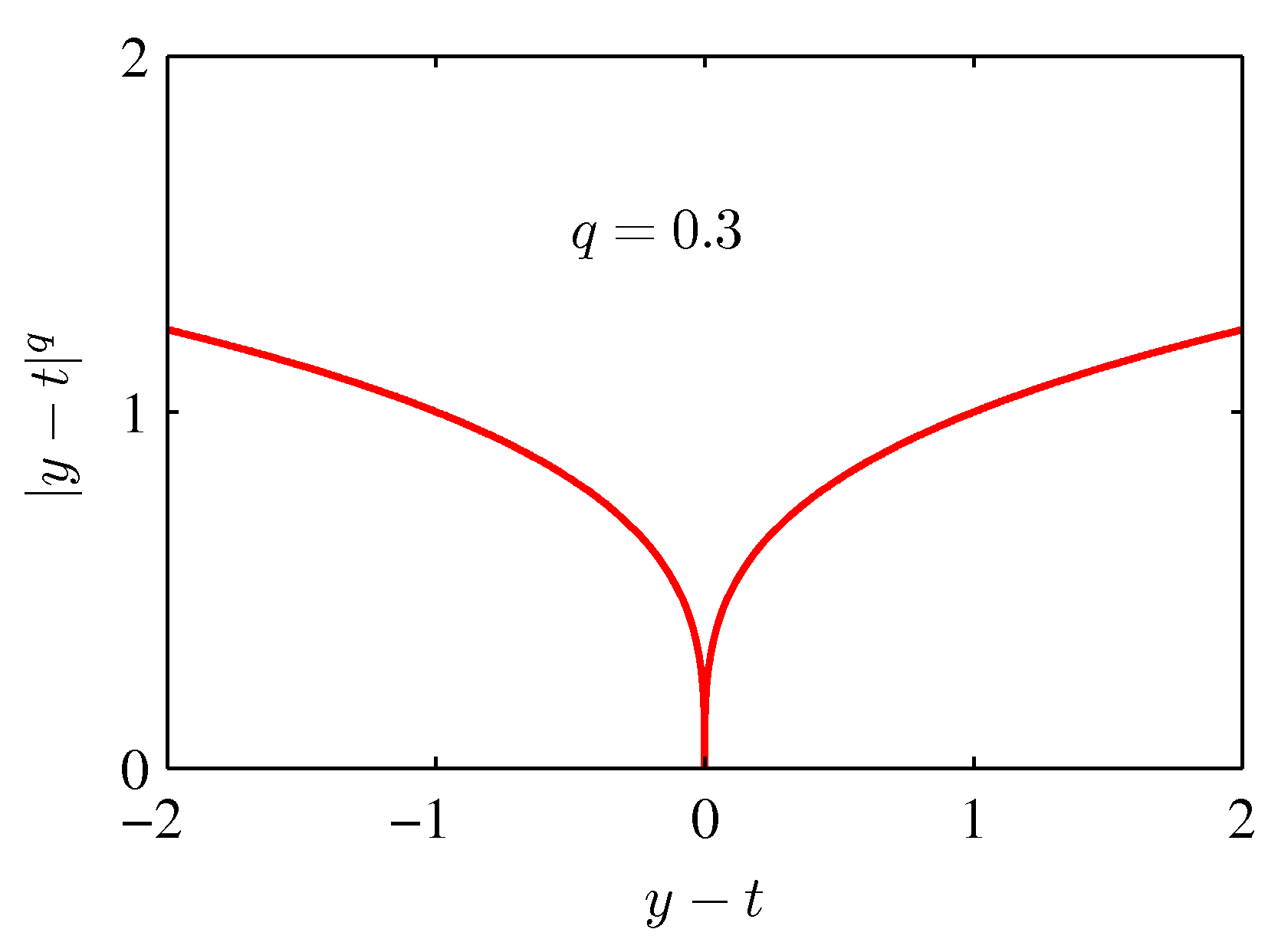
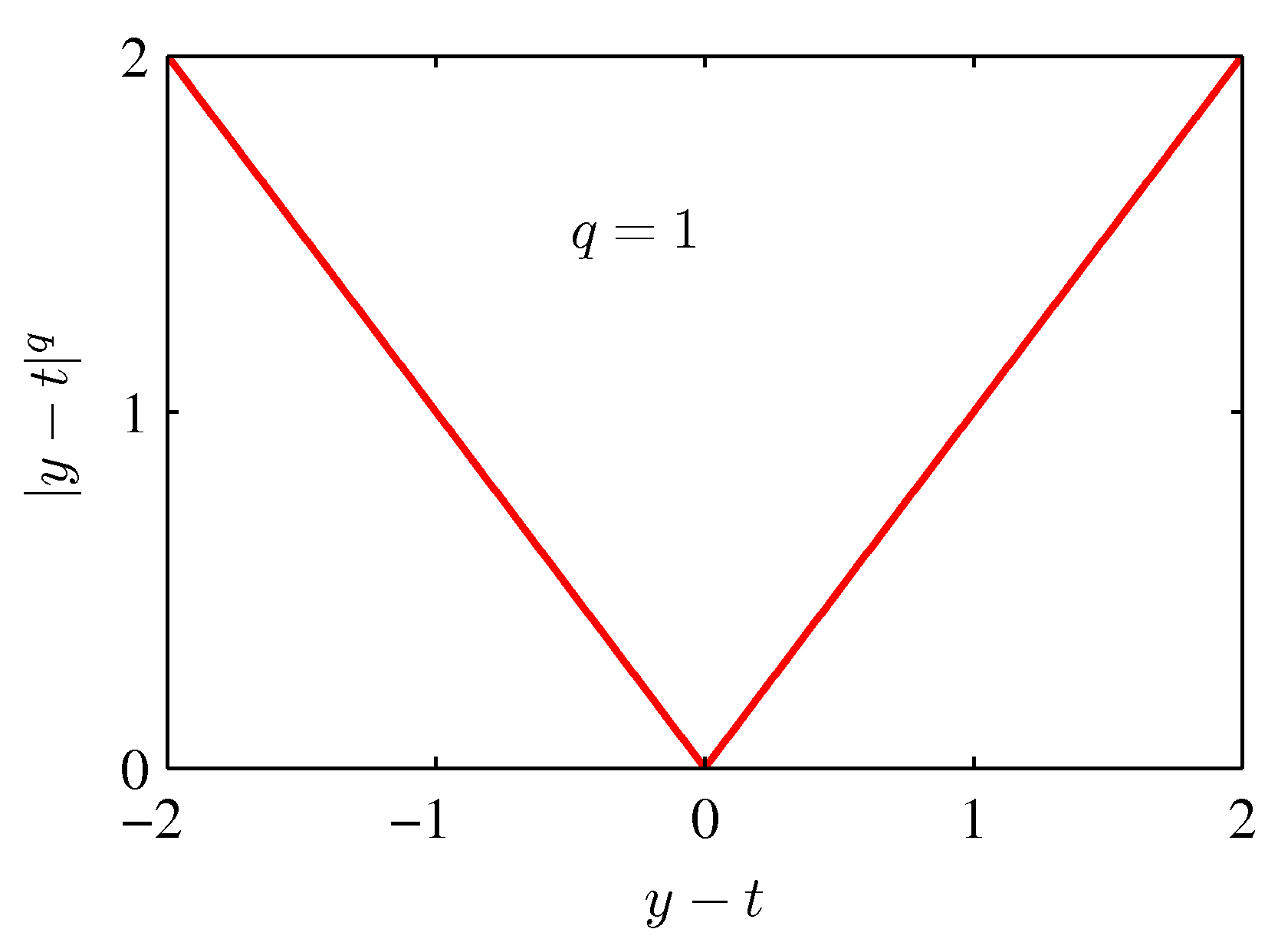
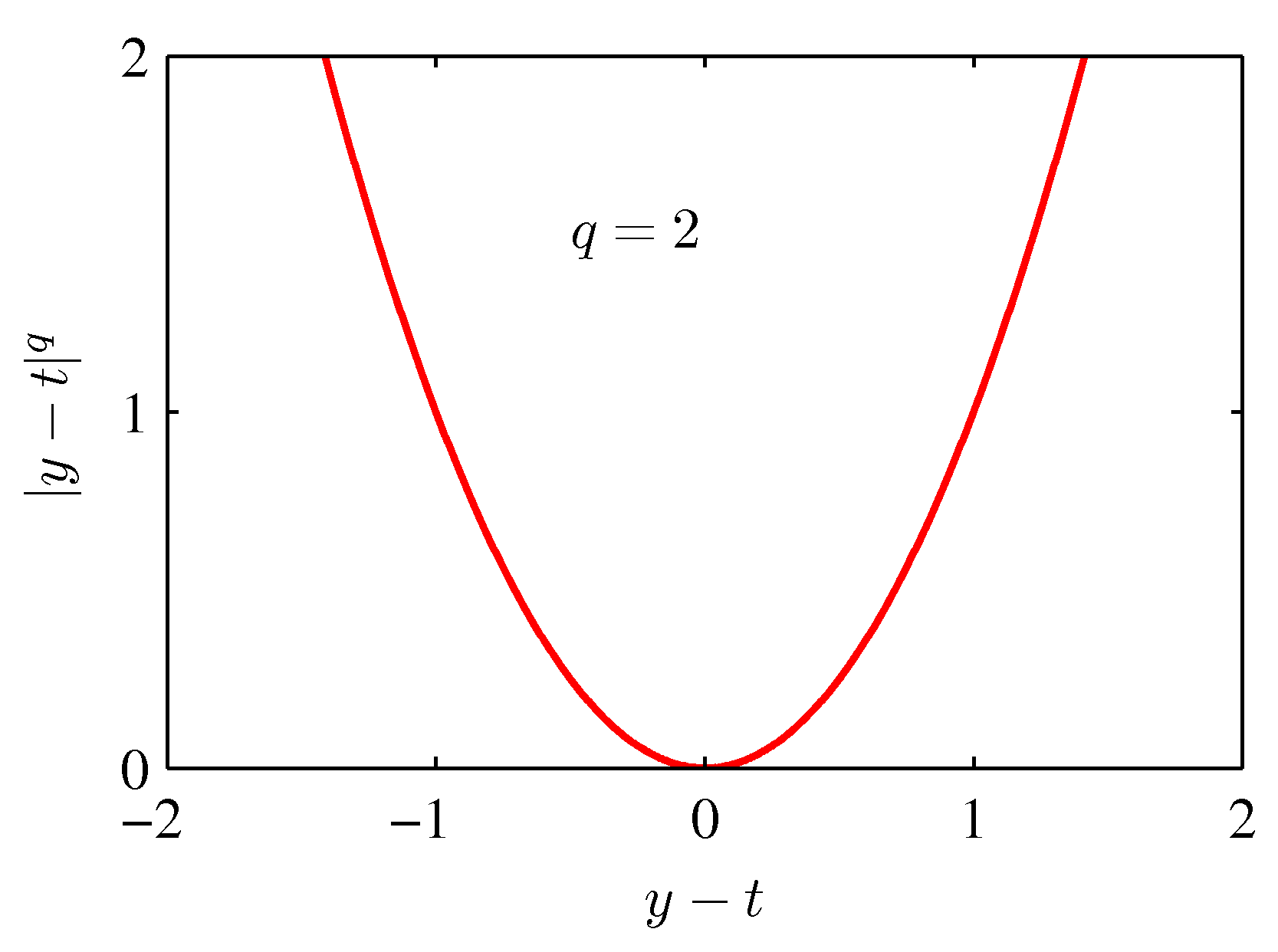
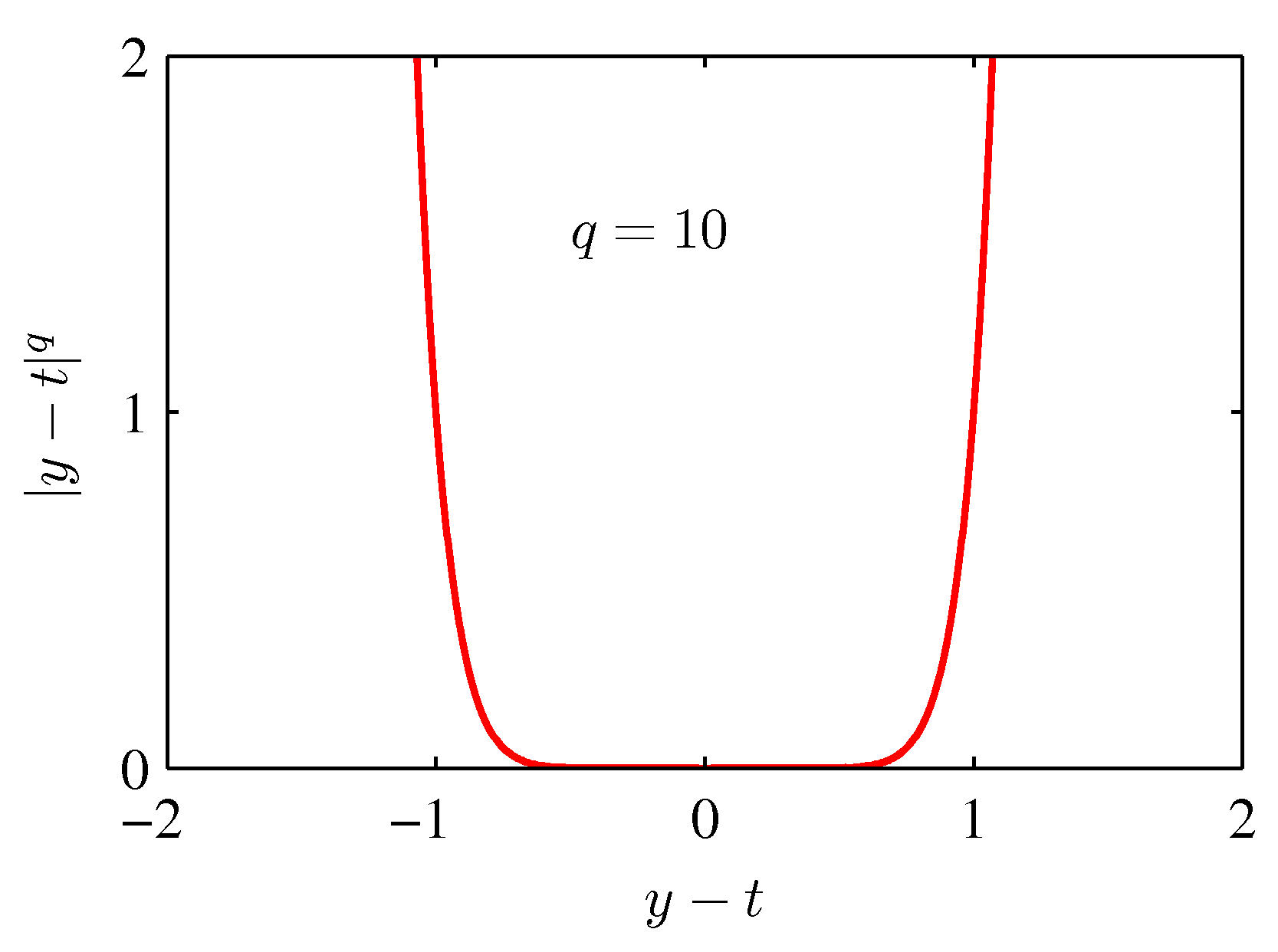
- 위의 식은 앞서 사용했던 squared-loss 함수의 확장판으로 좀 더 일반화시킨 모델이다
- 참고로 squared-loss 는 \( q \) 가 2일때의 함수이다.
- 이 때 \( q \) 값에 따른 함수의 변화 모양은 아래 그림과 같다.