11.1.1 표준 분포 (Standard distributions)
- 이제 비균등 분포에서 난수를 생성하는 방법을 살펴보자.
- 비균등 분포로부터 난수를 발생시키는 경우에도 기본적으로 균등 분포로부터 시작하는 경우가 많다.
- 따라서 일단 균등 분포(uniform distribution)를 이용하여 난수 발생기를 먼저 고려해보자.
- 그리고 이를 통해 생성된 \(0\) ~ \(1\) 사이의 값을 \(z\) 라고 하자.
- 우리는 어떤 변환 함수 \(f\) 를 이용하여 이 \(z\) 값을 적절히 변환할 것이다.
- 따라서 이에 대한 변환식으로 \(y=f(z)\) 인 어떤 식을 고려할 수 있다.
- 그리고 \(y\) 에 대한 확률식을 고려한다. (변환식 또한 확률 분포이기 때문에. 앞에서 많이 나온 식이다.)
- 당연히 \(p(z)\) 는 균등 분포이다. 따라서 \(p(z) = 1\)이 성립한다.
- 균등분포인데다가 출력 범위가 \(0\) ~ \(1\) 이기 때문이다.
- 이제 여기서 확률식의 적분식을 고려할 것이다. (즉, \(CDF\))
- 이는 특정 지점 \(y\) 까지의 \(CDF\) 값이고 이 식을 새로운 함수 \(h\) 로 정의힌다.
- 이를 \(y\) 에 대한 함수로 기술해보면 결국 \(y=h^{-1}(z)\) 가 된다.
- 무슨 말인지 잘 이해가 가지 않는다면 아래 그림을 보자.
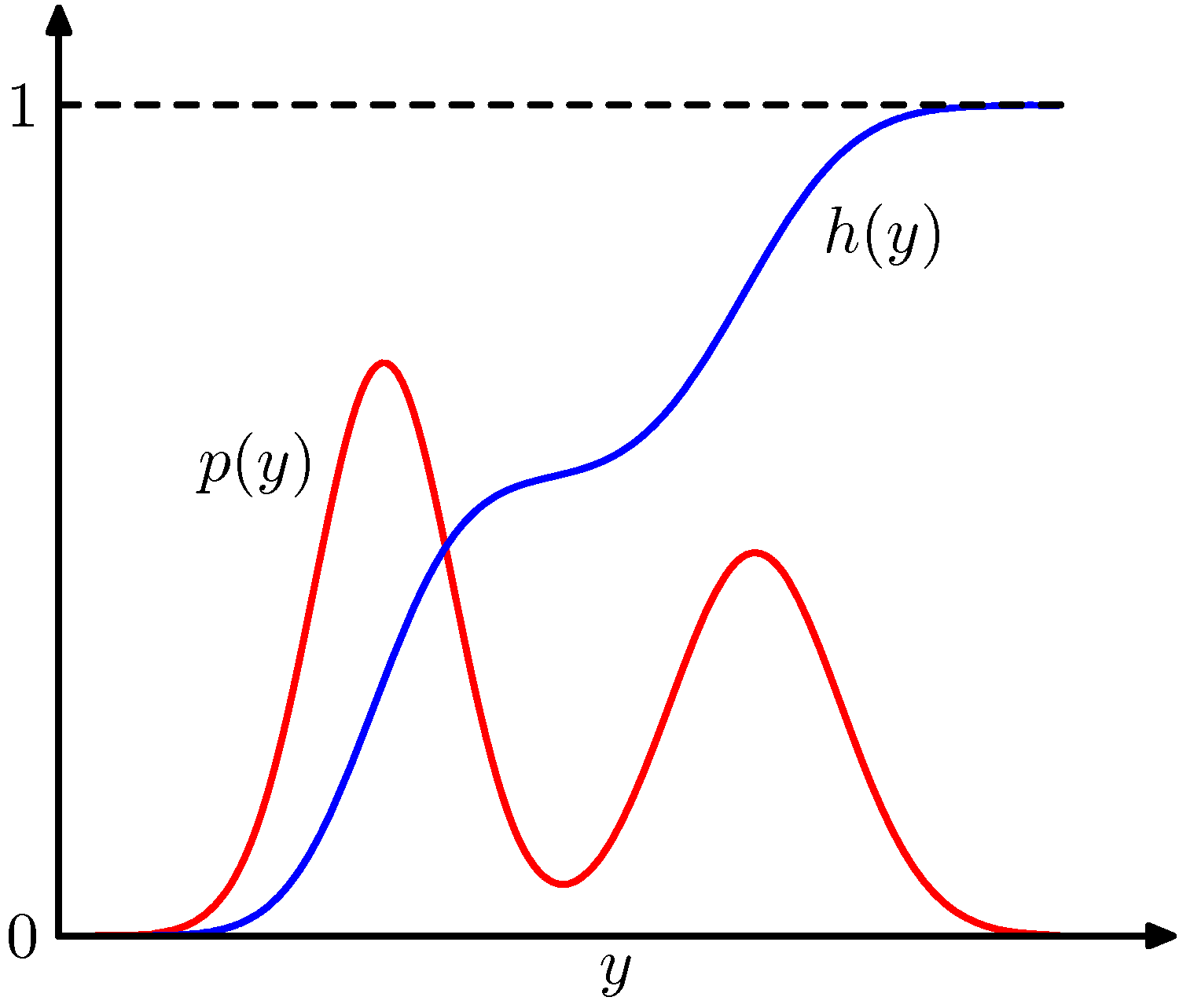
- 쉽게 생각해보자면 균등(uniform) 분포를 통해 세로 축의 값을 임의로 생성하는 것이다.
- 그러기 위해 구하고자 하는 함수 \(p(y)\) 에 대해 \(CDF\) 함수 \(h(y)\) 를 구한다.
- \(h(y)\) 의 역함수가 균등 분포로 생성된 값이 될 것이므로 이에 대한 역함수 값을 구해 가로 축의 값을 구한다.
-
이 값이 바로 \(p(y)\) 분포에서 생성된 샘플 \(y_0\) 가 될 것이다.
- 간단한 예를 살펴보도록 하자.
- 어떤 \(y\) 에 대한 확률 함수가 지수 분포(exponential distribution)를 따른다고 생각해보자.
- 즉, 우리는 이 분포로부터 임의의 샘플을 생성하고 싶은 것이다.
- 이 때의 입력 범위는 \(0 \le y \le \infty\) 이다.
- 일단 위의 방식을 적용하기 위해서는 이 식에 대한 \(CDF\) 를 구할 수 있어야 한다.
- 이에 대한 역변환을 구할 수 있으면 된다. 다음 식을 참고하자.
- 교재에는 생략이 되어 있지만 친철하게 한번 정리해 봤다.
- 바로 다음 예제 들어간다.
- 코쉬(Cauchy) 분포를 샘플링 하는 방법을 간단하게 살펴보자.
- 이 함수를 위의 방식대로 \(CDF\)를 구하고 역함수를 구하는 방식으로 전개하면 \(\tan(\dot)\) 함수를 얻게 된다.
- 마지막으로 이러한 변환식을 고차원으로도 일반화 가능한데, 다음의 식을 이용하면 된다.
Box-Muller Method
- 사실 잘 쓰지도 않을 분포들로부터 샘플을 생성하는 방법을 참 힘들게 살펴보았다.
- 이제 가우시안 분포로부터 샘플을 어떻게 생성할 것인지를 생각해야 한다. (이 분포가 가장 자주 사용되므로)
- 가우시안 분포도 위와 같은 방식으로 처리하면 뭐, 크게 무리 없게 전개가 가능하기는 하다.
- 하지만 여기서는 다변량 가우시안 분포를 고려할 것이다.
- 이 경우 \(N\) 차원의 데이터가 서로 상관 관계가 있기 때문에 단순한 방식으로는 생성이 쉽지 않다.
- 공분산의 의미를 생각해보자.
- 가장 먼저 난수 생성기의 생성 범위가 좀 다르다.
- \((-1, 1)\) 사이의 난수가 발생한다. (즉, \((0, 1)\) 이 아니다)
- 일단 문제를 간단하게 접근하기 위해 2차원의 데이터만을 고려하도록 하자.
- 발생되는 난수를 각각 \(z_1\) 와 \(z_2\) 라고 하자.
- \(-1\) 과 \(1\) 사이의 난수는 기존의 \((0, 1)\) 난수 발생기에 \(z_{new} = 2(z_{old})-1\) 을 적용하면 쉽게 생성할 수 있다.
- 그리고 이렇게 생성된 2개의 난수가 다음의 조건을 만족하는 경우에만 채택하도록 한다.
- 즉, 원 안의 점들에 포함되는 경우에만 채택하도록 한다.
- 균등 분포로 발생되었으므로 내부 원 안에서 발생될 확률은 모두 동일하게 된다.
- 실제 확률 값은 \(p(z_1, z_2) = 1 / \pi\) 가 된다.
- 혹시나 이게 왜 그런지 모르는 분들을 위해 간단히 정리해보자면,
- 현재 원의 면적은 \(\pi\) 이므로 한 점의 확률 값은 당연히 \(1 / \pi\) 가 된다.
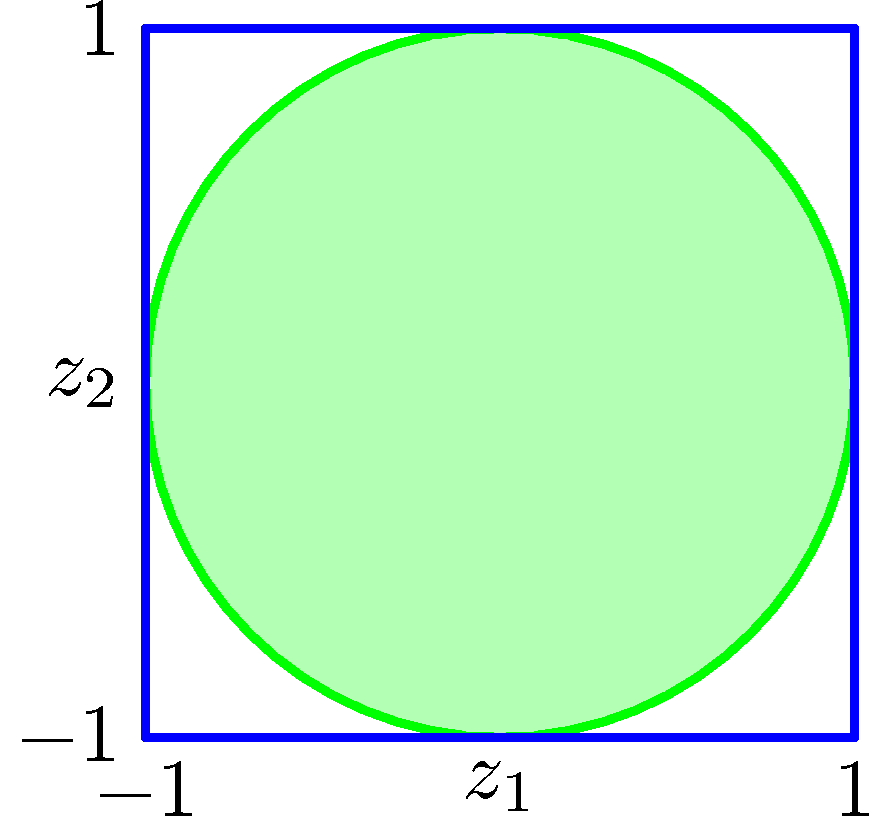
- 이로부터 변환된 좌표를 만들어보자.
- 위의 식은 원 내에 균등 분포로 생성된 샘플을 표준 가우시안 분포로 변환해주는 식이다.
- 어떻게 이런 식으로 전개되는지 찾아보다가 지쳐서 포기했다.
- 극좌표 전환을 적절히 하다보면 나오는 것 같다.
- 관심이 생긴다면 위키피디아를 참고하도록 하자. ( 링크 )
- 이를 이용하여 \(p(y1, y2)\) 의 확률을 정의할 수 있다.
- 이렇게 해서 끝나는 것은 아닌데 이것으로 얻을 수 있는 분포는 평균이 \(0\)이고 공분산이 \(I\) 인 단위 가우시안 분포이다.
- 따라서 \(y_1\) 와 \(y_2\) 는 서로 독립적이다.
- 실제 우리가 원하는 샘플은 특정 평균값과 특정 공분산을 가지는 가우시안 분포에서의 샘플이다.
- 그런데 사실 이와 관련된 내용은 이미 2장에서 조금 다루었다.
- 2개의 차원을 가지는 임의의 가우시안 분포를 서로 독립적인 가우시안 분포로 변환하는 방법을 2장에서 이미 다루었다.
- 따라서 적절한 변환으로 다른 가우시안 분포를 만들어 낼 수 있다는 의미
- 주어진 단위 분포로부터 평균이 \(\mu\) 이고 공분산이\(\Sigma\) 인 분포를 만들기 위해서는,
- \(y = \mu + Lz\) 로 변환하면 된다. 여기서 \(L\) 값은 \(\Sigma = LLT\) 로부터 촐레스키 분해(Cholesky decomposition) 를 통해 얻을 수 있다.
- 지금까지 살펴본 방식은 매우 유용한 방식이지만,
- 주어진 분포가 매우 간단하여 적분과 역변환기 가능한 분포에서만 사용할 수 있다.
- 따라서 이런 방식을 적용할 수 없는 분포에서는 좀 더 일반화된 방식을 사용해야 한다.
- 앞으로 다음의 방법들을 살펴볼 것이다.
- rejection sampling
- importance sampling
- 근데 이러한 방식도 사실 단일(univariant) 분포에서나 사용 가능한 방식이다.
11.1.2 Rejection Sampling
- 보통 채택-기각 샘플링이라고 하던데, 여기서는 그냥 기각 샘플링이라고 하자.
- 기각 샘플링은 복잡한 분포로부터 샘플을 추출할 수 있는 프레임워크이다.
- 여기서는 단일 분포에서의 샘플 추출만을 고려하도록 한다.
- 왜 그런지는 후반부에 설명되어 있다.
- 우리가 샘플링하고 싶은 분포 \(p(z)\) 가 주어졌다고 생각해보자.
- 그런데 이 분포는 좀 복잡한 형태를 취하고 있기 때문에 바로 샘플을 생성할 수는 없다.
- 좀 더 가정을 넣어보자.
- 주어진 \(p(z)\) 에서 샘플을 직접 생성하기는 매우 어렵지만, 반면 정규화되지 않은 \(p(z)\)의 식은 구하는게 가능하다고 생각해보자.
- 조금 억지같지만, 사실 지금까지 다룬 분포들이 이러한 형태가 많았다. (사후 분포의 형태가 사실 이런 식이다.)
- 여기서는 정규화 계수 \(Z\) 를 도입하여 정규화되지 않은 분포에 대해 다룰 수 있도록 한다.
- 물론 여기서 \(Z_p)\) 의 값은 알지 못한다. (알면 이런 짓을 하지 않았을 것이다.)
- 기각 샘플링 기법을 만들어내기 위해서는 새로운 분포 \(q(z)\) 를 도입해야 한다.
- 이런 분포를 Proposal 분포라고 한다. (한글로는 제안 분포라 해야하나?)
- 이 분포에 대한 가정은 이 분포에서 샘플 생성이 가능하다는 것이다.
- 앞절에서 살펴보았던 다양한 분포들을 떠올려보자.
- 이제 다음으로 상수 \(k\) 에 대해 알아보자.
- 앞서 이야기했지만 사용되는 실제 분포는 정규화되지 않은 분포이다.
- 이제 \(q(z)\) 에 상수 \(k\) 를 곱한 값을 사용한다.
- 이 때 \(k q(z) \ge \widehat{p}(z)\) 를 만족하는 가장 작은 \(k\) 를 사용할 것이다.
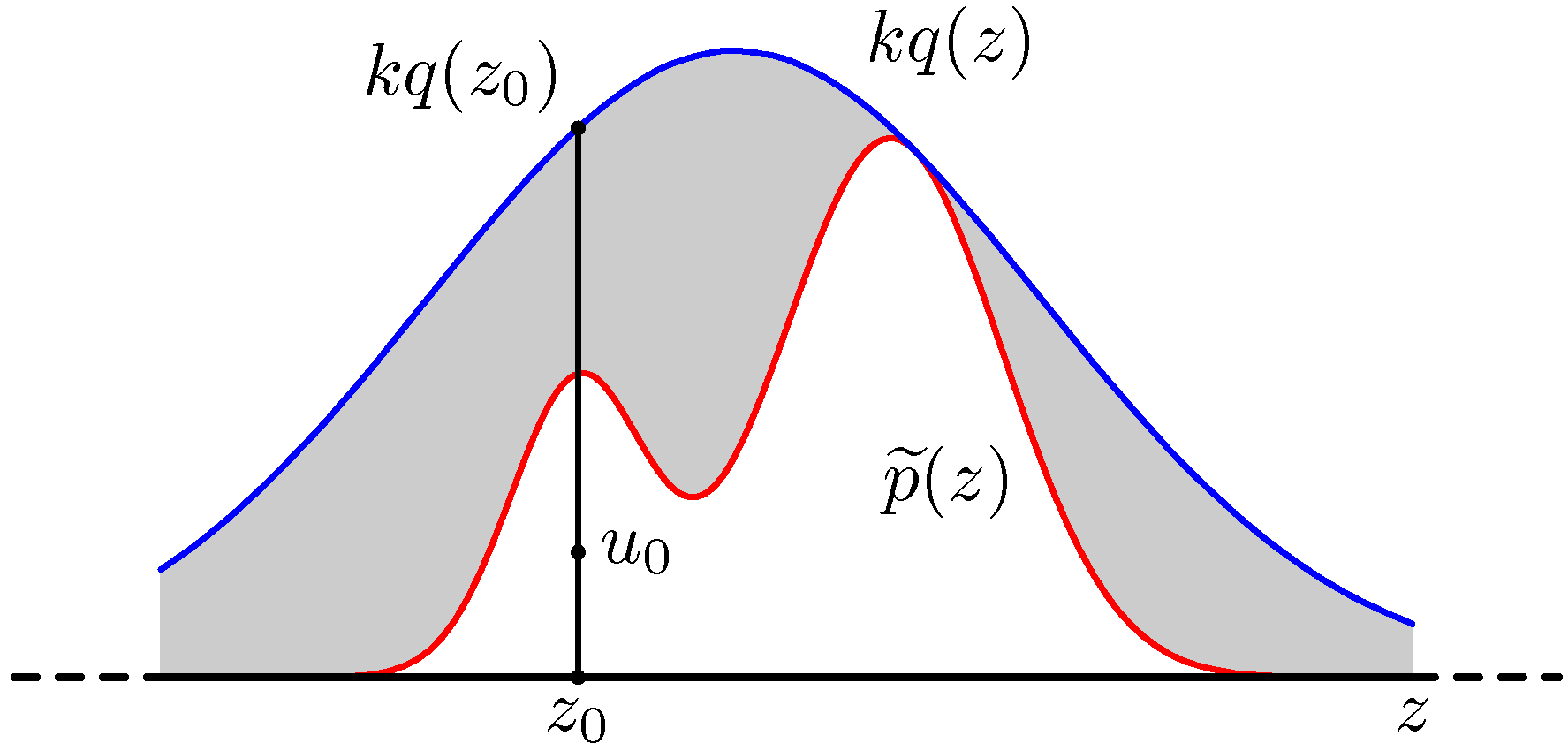
- 이제 위의 그림을 통해 샘플링을 수행하는 방식을 알아보자.
- 가장 먼저 \(z_0\) 를 생성해야 한다.
- 이 때의 샘플은 \(q(z)\) 분포를 따르는 샘플이다.
- 따라서 원래 의미를 따지자면 이 샘플은 \(p(z)\) 와는 상관이 없다.
- 다음으로 균등 분포를 이용하여 \([0, kq(z0)]\) 사이에서 난수 하나를 발생한다. 이 값을 \(u_0\) 로 둔다.
- 마지막으로 \(z_0\) 를 이용하여 \(\tilde{p}(z_0)\) 를 구한다.
- 이 때 만약 \(u_0 \le \tilde{p}(z_0)\) 이면 샘플을 취한다.
- 이 조건을 만족하지 못하면 샘플을 기각하고 처음부터 다시 샘플을 생성하도록 한다.
- 결국 이 식을 이용해서 구하고자 하는 것은 그림에서 어둡게 표현된 영역의 샘플을 얻게 되면 그 샘플을 버리는 것이다.
- 결국 어두운 부분이 최소로 존재해야 샘플이 기각될 확률이 줄어들 것이다.
-
난수는 최대한 빠른 시간 내에 생성되어야 좋은 생성기라 할 수 있으므로 가급적 이 면적을 없애는게 좋다.
- 이제 샘플의 채택률을 확률 함수를 통해 표현할 수 있다.
- 여기서 중요한 것은 채택률은 \(k\) 에 반비례한다는 사실이다.
- 따라서 채택률을 올리기 위해서는 최대한 \(k\) 가 작아야 한다는 것이다.
-
따라서 \(kq(z)\) 가 항상 \(p(z)\) 보다 크다는 조건을 만족하면서도 가장 작은 \(k\) 를 선택해야 한다.
- 기각 샘플링을 예제를 통해 살펴보도록 하자. 다음과 같은 감마 분포로부터 샘플을 추출하려고 한다.
- 이 때 \(a \gt 0\) 라면 감마 분포는 종 모양을 취하게 된다.
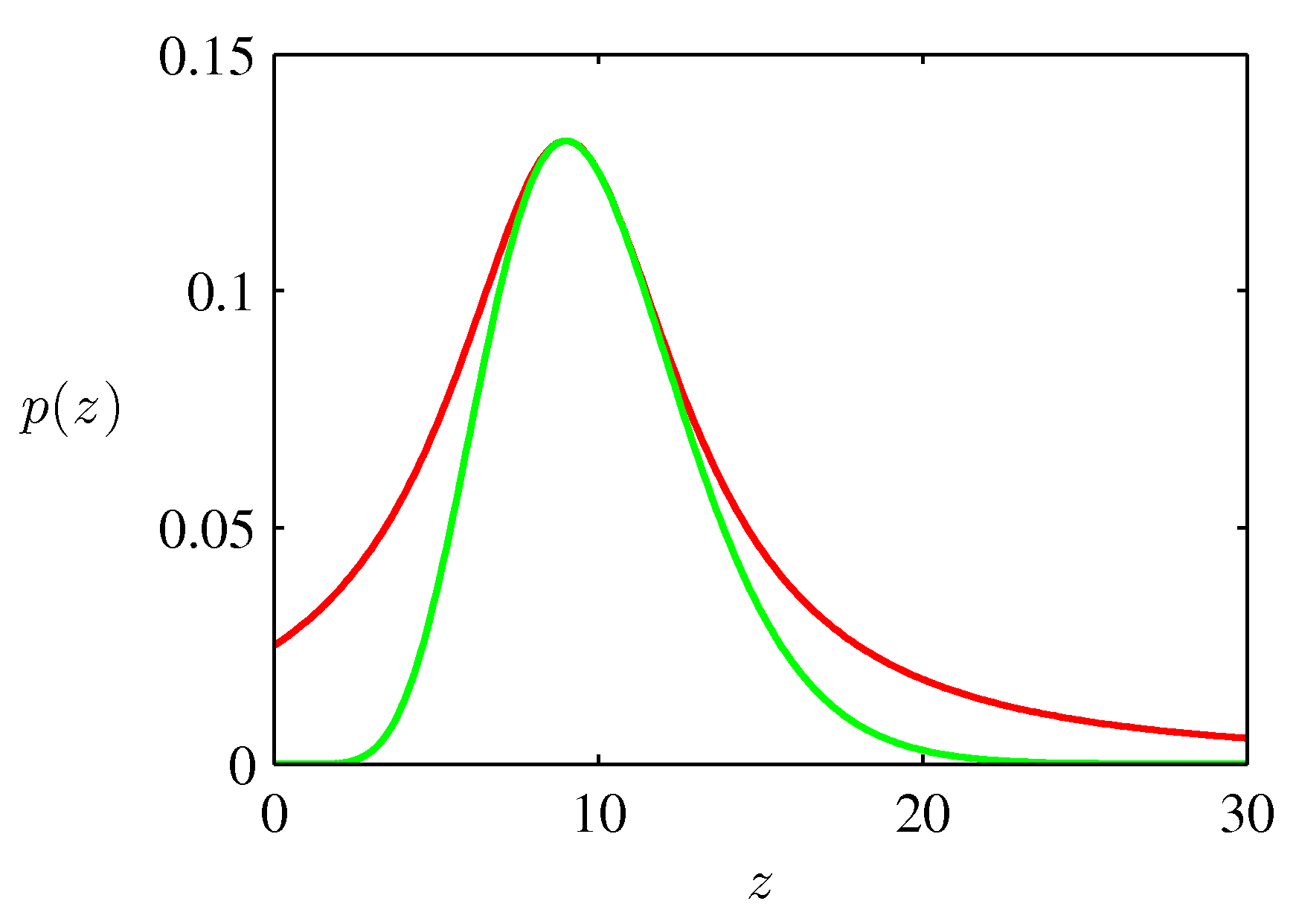
- 그림에서 감마 분포는 녹색 선이다. 그리고 당연히 붉은 색 선이 \(q(z)\) 함수이다.
- 감마 분포에다가 \(CDF\) 를 구하고 역함수를 적용하는 것이 쉽지 않으므로 기각-샘플링을 사용한다.
- 여기서는 \(q(z)\) 함수로 코쉬(Cauchy) 분포를 사용할 것이다.
- 앞 절에서 아주 간단하게 언급했는데, 함수가 \(\tan\) 꼴로 나온다고 했었다.
- 그리고 코쉬 분포 또한 종 모양의 분포 형태를 가지고 있다.
- 따라서 코쉬 분포로 감마 분포를 덮으면서도 가장 작은 \(k\) 값을 찾는 과정이 필요하다.
- 코쉬 분포 또한 균등 분포에서 생성된다고 했다.
- 식은 \(z = b\tan(y) + c\) 로 놓고 전개하면 된다.
- 식이 좀 혼동되는데, 위의 식에서는 \(y\) 가 균등분포이고 \(z\) 가 코쉬 분포이다.
- 교재에서는 전개 과정이 나와있지 않다. 중요한 것이라 생각되지 않아서 그냥 결과만 적는다.
- 위의 식은 코쉬 분포의 \(pdf\) 값 중 일부 상수가 \(k\) 에 흡수된 형태로 기술된 모양이다.
- 이 함수를 감마 분포와 최소한의 갭으로 만들기 위해서는,
- \(c = a − 1\)
- \(b2 = 2a = 1\)
- 를 만족하는 식중 가장 작은 \(k\) 를 선택해야 한다.
11.1.3 개선된 기각 샘플링 (Adaptive rejection sampling, a.k.a ARS)
- 기각 샘플링은 매우 유용한 프레임워크이지만 많은 경우에 \(q(z)\) 자체를 만들어내는 경우가 쉽지 않을 때가 있다.
- 따라서 조금 색다른 방법으로 덮개 함수(envelope function) \(q(z)\) 를 생성해 보도록 하자.
- 일단 여기에는 조건이 필요한데…
- 먼저 \(\ln{p(z)}\) 가 \(concave\) 를 만족하는 함수여야 한다. ( \(z\) 의 전 영역에 걸쳐 만족해야 하는 조건이다. )
- 따라서 실제 사용 가능 여부를 확인하는 과정이 필요하다.
- 가장 먼저 \(k\) 개의 샘플 포인트를 선정한다.
- 보통 양 끝단을 결정한 뒤에 일정한 비율로 나누거나 여러 방법을 이용하여 샘플 포인트를 구한다.
- 왼쪽으로 unbound 한 경우에는 \(q’(x_1) \gt 0\) 중 한 점을 기준으로 잡고,
- 오른쪽으로 unbound 한 경우에도 \(q’(x_k) \lt 0\) 인 한 점을 기준으로 잡는다.
- 해당 위치에서의 함수의 접점을 구하고 그 때의 \(q(z)\) 함수를 구하면 된다.
- 사실 교재에 나오는 방법 말고 다양한 응용체가 존재하는 듯.
- 이제 예를 들어가면서 진행해보자.
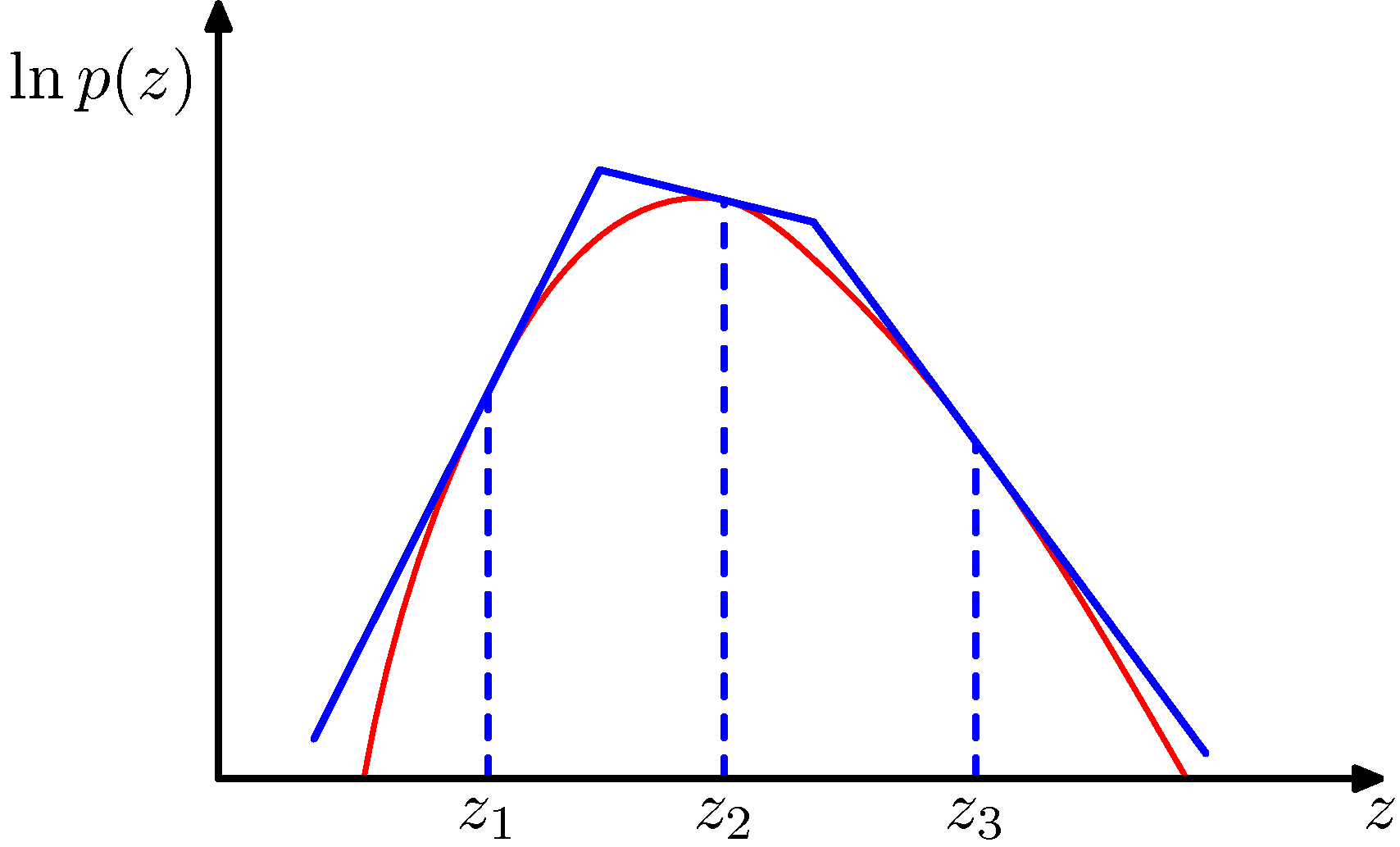
- 위의 그림은 입력값 \(z\) 에 대한 출력 \(\ln{p(z)}\) 를 나타내고 있다.
- 총 3개의 포인트가 보이는데, 사실 그냥 임의의 지점을 선택할 수도 있고 일정한 간격으로 선택할 수도 있다. 혹은 다른 방식도 가능하다.
- 어쨌거나 포인트가 정해지면, 해당 점으로 부터 접선을 구한다.
- 이 때의 접선이 \(q(z)\) 함수가 되는 것이다.
- 즉, 위의 그림으로 보면 파란색 선이 \(q(z)\) 함수가 되는 것이다.
- 이 때의 직선은 지수 분포(exponential distribution)로 고려하는데, 이건 그냥 정한 것이 아니라 지수 분포에 로그를 취하면 직선 식이 나오기 때문이다.
- 따라서 이 분포를 구간 별로 사용하면 된다. 얻어지는 \(q(z)\) 함수는 다음과 같다.
- 여기서 \(\widehat{z}_{i-1, i}\) 은 각 포인터에서 접선이 만나는 지점을 의미한다.
- 그리고 \(\lambda_i\) 는 각 영역에서의 기울기를 나타낸다.
-
구간 별로 나누어 \(q(z)\) 를 정하고 이를 이용하여 기각-샘플링을 사용하는 방식이다.
- 장점
- 이러한 방식이 가지는 장점은 당연히 기각되는 영역이 최소화된다는 것이다.
- 이러면 더 빠른 속도로 샘플을 생성하는 것이 가능할 것이다.
- 다만 식이 복잡하기 때문에 계산 복잡도가 증가할 것이다.
- 단점
- 아쉽게도 이러한 방식에도 문제가 있는데, 차원의 저주 문제가 있다.
- 앞서도 잠깐 언급했는데, 차원이 증가하면 왜 문제가 되는지 알아보도록 하자.
차원의 저주
- 차원이 증가하면 왜 문제가 되는지를 예제를 통해 알아보도록 하자.
- 문제를 간단히 보기 위해서 가우시안 분포를 \(p(z)\) 라고 하고, 이에 대한 덮개 함수 \(q(z)\) 도 가우시안 분포라고 해보자.
- 이렇게 하면 함수의 모양은 거의 비슷하게 나오거나 같아질 것이다.
- 이 때 사용할 가우시안 분포는 평균이 0, 분산이 I 인 가우시안 분포이다.
- 가장 먼저 \(kq(z) \le p(z)\) 를 만족하기 위한 식을 세워야 한다. 결국 \(\sigma_q^2 \le \sigma_p^2\) 가 요구된다.
- 이를 전개하면 최종적으로 상수 \(k\) 는 \(k=(\sigma_q / \sigma_p)^D\) 가 됨을 알 수 있다.
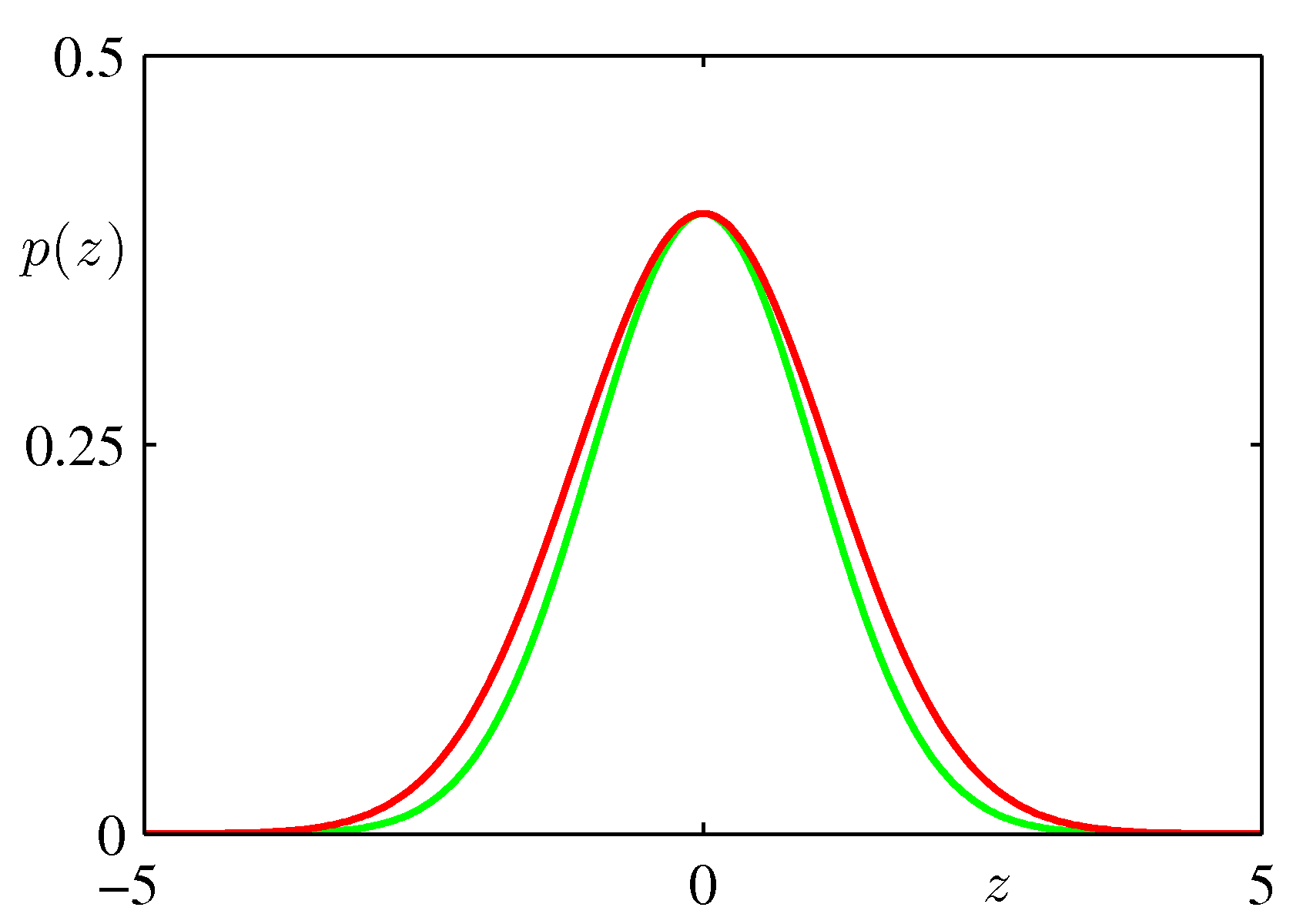
- 위의 그림은 가우시안 분포를 가우시안으로 덮은 함수에 대한 1차원 그림을 보여주고 있다.
- 이 때 차이가 나는 면적은 매우 작은 것을 알 수 있는데, 따라서 기각률은 매우 낮을 것이다.
- 하지만 이미 우리는 수식에서 채택률은 차원 D 에 반비례하는 것을 알 수 있다.
- 따라서 이 문제는 결국 \(k\) 가 입력 차원에 대해 지수로 증가되는 문제가 된다.
- 만약 샘플의 차원이 \(D=1000\) 이라고 하면 채택률은 \(1/20000\) 이 된다.
- 즉, 단일 차원에서의 기각률은 매우 작지만, 차원이 증가하면 채택률이 급격하게 내려감.
- 따라서 차원이 증가하는 경우 샘플을 얻기가 매우 어려워지는 상황이 발생하게 된다.
주표집 방식 (Importance sampling)
- Importance sampling 을 한국말로 주표집이라고 하더라.
- 어쨌거나 이번 장 맨 처음에 언급했던 식을 다시한번 떠올려보자.
- 이 식은 어떤 함수 \(f(z)\) 에 대한 기대값을 추정하는 식이다.
- 그리고 우리는 이 값을 구하기 위해 \(p(z)\) 근사하는 것을 살펴보았다.
- 결국 우리가 필요한 것은 이는 \(p(z)\) 에 기반하여 생성된 샘플이나,
- 현실적으로 이를 샘플링하기 쉽지 않으므로 근사 분포인 \(q(z)\) 로 샘플을 생성하는 방법을 살펴보았다.
- 최종적으로 기대값을 위해 다음의 근사식을 사용하되 샘플 자체는 근사된 확률 분포로부터 생성.
- 여기서는 식(11.1)을 통해 바로 기대값을 구할 수 있는 importance sampling 기법을 다룰 것이다.
- 그리고 여기서도 마찬가지로 당연히 \(p(z)\) 부터 샘플링을 바로 할 수는 없다.
- 간단하게 살펴보면 importance sampling 은 다음과 같은 일을 수행한다.
- 기각 샘플링과 마찬가지로 어떤 분포를 제안한다. (proposal distribution)
- 이 분포는 기각-샘플링때와는 다르게 모든 샘플을 저장하는 구조이다.
- 그리고 어떠한 \(z\) 에 대해서도 \(p(z)\) 가 평가 가능하다고 생각한다.
- 이 식의 문제는 당연히 \(z\) 의 차원이 증가하면 계산량이 지수로 증가한다는 것.
- 또 분포의 종류에 따라서 \(z\) 전체의 영역이 아닌 일부 영역에서만 확률값이 존재하여 균등 분포로는 제대로된 샘플링을 할 수 없다.
- 또한 균등 분포로는 차원이 증가했을 때 성능이 별로 좋지 못하다는 것을 이미 확인했었다.
- 따라서 이상적으로는 \(p(z)\) 의 확률이 \(z\) 공간에 충분히 크게 분포되어 있거나, 혹은 \(p(z)f(z)\) 가 충분히 커야 한다.
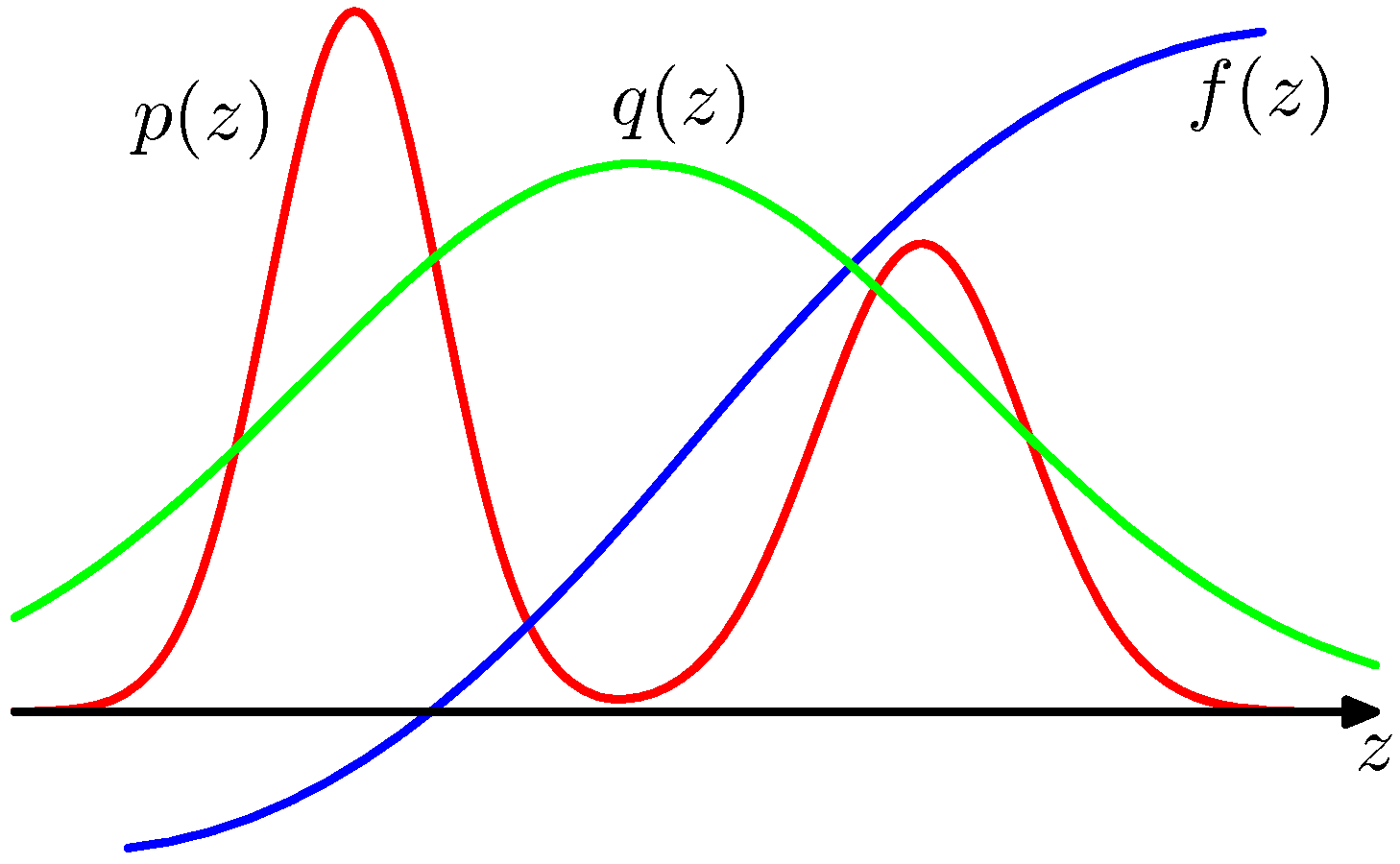
- 여깃도 마찬가지로 \(q(z)\) 함수를 확률 분포 함수로 사용할 것임
- 다만 원래 \(p(z)\) 와는 확실히 다른 분포이기 때문에 이에 대한 차이의 비율을 반영할 것이다.
- 단, 여기서 \(\tilde{r}_l = \tilde{p}(z^{(l)})\;/\;\tilde{q}(z^{(l)})\) 이다.
- 최종적으로 다음의 식을 얻는다.
- 기각-샘플링 방식과 마찬가지로 이러한 샘플링 방식이 좋은 결과를 가지기 위해서는 \(q(z)\) 함수가 최대한 \(p(z)\) 함수와 비슷해야 한다.
- 아주 흔한 일이기도 하지만, 만약 \(p(z)\) 가 변화무쌍한 모양을 가진데다가 \(z\) 의 공간 중 국소 지역에서만 값을 가지고 있다면,
- 주 가중치 \(r_i\) 의 영향은 일부 몇 개의 값에 의해 크게 좌우될 것이다.
- 결국 좋지 못한 결과를 얻게됨.
- 실제로 가장 효율적인 샘플 수는 주어진 샘플들보다 훨씬 작을 수 있다.
- 문제는 \(p(z)f(z)\) 값이 충분히 크더라도 \(q(z)\) 로 인해서 해당 영역에서의 샘플이 발현되지 않을 수 있다는 것.
-
이 경우에는 \(r_i\) 또는 \(r_i f(z^{(l)})\) 가 매우 작아져서 샘플링 결과가 별로 좋지 않게 된다.
- 그래프 모델에서 정의된 분포에 대해 우리는 다양한 방법으로 importance sampling 기법을 적용할 수 있다.
- 그래프 모덷의 노드가 이산 변수라고 해보자. 이러면 우리는 uniform sampling 기법을 이용하여 샘플링이 가능하다.
- 이 때의 결합 분포는 마코브 확률곱인 식(11.4)을 이용한다.
- 결합 분포로 생성되는 샘플에서 가장 먼저 설정되는 노드는 관찰된 데이터이다. (evidence set)
- 이 다음으로 관찰되지 않는 변수들은 균등 분포로 생성을 하게 된다.
- 한 샘플 \(z^{(l)}\) 에 대응되는 주 가중치 (importance weight)를 결정하기 위해 샘플 분포 \(\tilde{q}(z)\) 는 균등 분포로 고려한다.
- 실제 분포로 사용되는 \(\tilde{p}(z)\) 는 관찰된 데이터가 포함된 \(\tilde{p}(z|x)\) 로 생각하면 된다. (\(x\) 는 evidence set)
- 결국 생성되는 샘플은 모두 고정된 evidence 를 가지게 된다.
-
이러한 방식은 사후 분포가 균등 분포와 많이 다를 수록 정확도가 떨어지게 된다.
- 개선된 방식으로 likelihood weighted sampling 이라는 것도 있다.
- 이것은 ancestral sampling 기법에 기초를 둔다.
- 알다시피 이 방식은 그래프 모델에서 정해진 순서대로 노드를 방문하게 된다.
- 한 노드를 방문했을 때,
- 해당 노드가 관찰되어진 노드 (즉, evidence set에 포함된 노드) 인 경우라면 해당 값으로 샘플을 생성한다.
- 해당 노드가 관찰되어진 노드가 아니라면 조건부 분포 \(p(z_i|pa_i)\) 로부터 샘플을 생성한다.
- 이렇게 하는 경우 샘플 각각의 weight 는 다음과 같이 계산할 수 있다.