- 이 논문의 소스는 바로 여기에 있습니다.
- 자, 이 글을 읽으시는 모든 분들은 들어가셔서
구독과 좋아요STAR 버튼이라도 한번 눌러주세요. :-)
- 자, 이 글을 읽으시는 모든 분들은 들어가셔서
Abstract
이미지 분류와 관련한 최근의 연구들은 CNN 모델의 성능을 올리기 위해 다양한 기법(technique)들을 제안하고 있다. 그러나 제안된 기법들을 잘 조합하여 실무에서 활용할 수 있는 모델에 대한 연구는 아직 부족한 실정이다. 이 논문에서는 기존의 다른 연구에서 제안한 다양한 기법들을 적절하게 조합(assembling)하여 기본적인 CNN에 적용을 해보고 많은 실험을 통해 이러한 방식이 모델의 정확도(accuray), 강건성(robustness)를 크게 향상시킬 수 있음을 확인한다. 이와 더불어 이러한 기법들을 조합할 때 최대한 모델의 처리량(throughput) 손실이 최소화되는 방향으로 조합을 구성한다. 이 논문에서는 ResNet-50 모델을 바탕으로 ImageNet-2012 Validation 데이터의 top-1 정확도(accuracy)를 76.3% 에서 82.78%까지 향상시켰다. 강건성(robustness)을 나타내는 지표 중 하나인 mCE 도 77.0%에서 48.9%까지 크게 향상시켰다. (낮을수록 좋다.) 이 때의 inference 처리량(throughput)은 초당 536개에서 312개 정도까지만 하락하였다. 또한 이 방법이 Transfer learning에서도 잘 적용되는지를 확인하기 위해 FGVC(fine-grained visual classification) Task와 유사이미지 검색(IR) Task를 통해 확인한다. 다양한 공개 데이터를 이용하여 백본(backbone) 네트워크의 성능 향상이 transfer learning에서도 확실한 효과를 얻을 수 있음을 확인하였다. 논문에 소개된 기법을 토대로 CVPR 2019 iFood 분류 대회에서 1등을 기록하였다 (링크). 코드는 모두 Github에 공개되어 있다.
Introduction
AlexNet이 소개된 이후 이미지 분류 문제에서 정확도를 올리기 위한 방법들은 대부분 새로운 네크워크 구조를 디자인하는 것에 초점이 맞추어져 있다. 예를 들어 Inception, ResNet, DenseNet, NASNet, MNASNet, EfficientNet 등이 제안되었다. Inception은 서로 다른 커널 크기를 가지는 convolution 레이어를 도입하였다. ResNet은 Skip-connection을 도입하였고 DenseNet은 dense-feature-connection을 추가하여 모델의 성능을 끌어올렸다. AutoML이 활용되면서 NASNet, MNASNet과 같이 자동으로 모델 구조를 생성하는 기법도 제안되었다. EfficientNet은 모델은 resolution, height, width 의 균형(balancing)을 고려한 효율적인 네트워크를 구성하였다. 그 결과 EfficientNet은 AlexNet에 비해 괄목할만한 성능의 향상을 이루었다.
이러한 연구 방식과는 다르게 Bag of Tricks와 같은 논문에서는 다른 접근 방식을 통해 모델의 성능을 끌어올린다. 이 논문에서는 모델 구조를 변경하는 방식 뿐만 아니라 데이터 전처리, learning rate decay, 파라미터 초기화 기법 등을 도입하여 모델의 성능을 향상시킨다. 또한 이러한 작은 기술(trick)들을 잘 조합하는 것이 실제 모델의 성능을 크게 증가시키는 주요한 영역임을 확인하였다. 이를 통해 ResNet-50 모델의 ImageNet-2012 top-1 성능을 75.3%에서 79.29%까지 향상시켰다. 이러한 성능 향상은 실로 엄청난 것이여서 여러 기법들을 조합하는 것이 새로운 모델 구조를 제안하는 것만큼이나 중요한 것임을 일깨워 주었다.
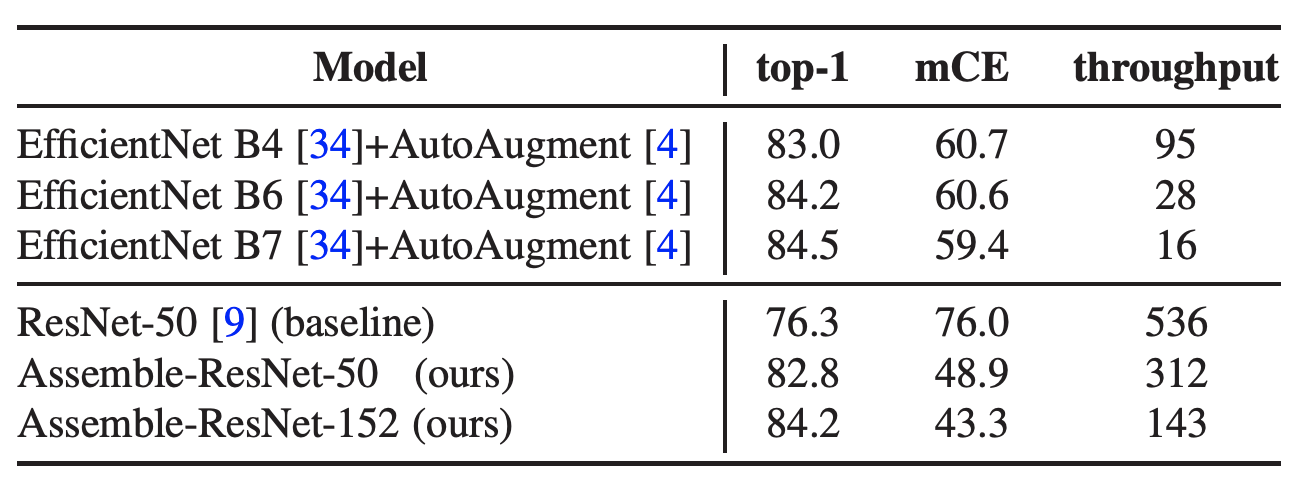
테이블 1. Summary of key result.
top-1은 ImageNet 정확도. mCE는 mean corruption error. throughput은 초당 이미지 처리량을 의미한다.
이 연구에 영감을 받아 우리는 하나의 단일 모델에 다양한 기법(technique)들을 최대한 잘 구성할 수 있는 방법들을 고려한다. 정말 많은 기법들이 존재하고 있지만 우선 우리는 이를 두개의 카테고리로 나누어 고려하였다. 하나는 Network tweak이고 다른 하나는 Regularization이다. Network tweak은 CNN 아키텍쳐를 좀 더 효율적으로 변경하는 기법들을 의미한다. 그 예로 SENet, SKNet 등을 들 수 있다. Regularizaion은 학습시 오버피팅(overfitting)을 막는 기법들로 AutoAugment, Mixup 와 같은 data augmentation 기법들과 Dropout, DropBlock 같이 CNN 모델 복잡도를 제한하는 기법들이 있다. 많은 실험을 통해 이 두가지 유형의 기법들을 조합하는 작업을 체계적으로 분석하여 이 방법이 상당한 성능 향상을 이끌어낼 수 있음을 확인한다.
우리는 top-1 과 mCE, throughput을 모두 성능의 주요 평가 지표로 삼고 이 평가를 기준으로 기법들을 조합한다. mCE는 mean corruption error로 입력 이미지의 corruption을 통해 모델의 강건성(robustness)을 측정하는 지표이다. 또한 우리는 일반적으로 사용하는 모델 성능 지표인 FLOPS (floating point operations per second) 대신 실제 GPU에서의 throughput (images/sec)을 주요 성능 지표로 삼는다. 이는 많은 실험을 통해 FLOPS가 실제 모델의 추론 응답 속도를 반영하지 못함을 확인했기 때문이다. 계산된 FLOPS와 실제 응답 속도의 비교는 Appendix.A에 더 기술하였다.
우리의 contribution은 다음과 같다.
- 이미 잘 알려진 CNN 관련 기법들을 구성하고 이를 단일 모델에 잘 조합(assembling)하였다. 이 모델이 비슷한 정확도를 가지는 SOTA 모델에 비해 훨씬 더 좋은 mCE와 throughput을 얻을 수 있음을 확인하였다.
- 다양한 실험 결과를 제공하고 실제 활용가능한 코드를 모두 공개하여 재현하기 쉽도록 하였다.
Preliminaries
우리가 제안한 기법들을 소개하기 전에 먼저 실험에 공통적으로 사용된 기본 설정 및 평가 지표를 기술한다.
Training Procedure
우리는 TensorFlow official ResNet 모델을 사용하였다. 데이터셋은 ImageNet ILSVRC-2012를 사용하였다. 이는 1.3M의 학습 데이터와 1,000개의 레이블로 구성된다. 모든 모델은 8개의 NVidia Tesla P40 GPU에서 실험하였다. 8개의 GPU는 단일 장비에 구성된다. CUDA-10, cuDNN-7.6 을 사용하였고 TensorFlow 버전은 1.14.0 버전을 사용하였다.
Bag of Tricks 논문에서 제안된 기본 설정들을 마찬가지로 사용하였다. 간단하게 정리하자면 다음과 같다. (이 논문을 안 읽었으면 꼭 읽도록 하자. 여기 정리된 페이지도 있다.)
-
Preprocessing 학습 단계에서는 3/4~4/3 사이의 비율로 랜덤하게 샘플링된 aspect ratio 값을 이용하여 랜덤 크롭(random crop) 박스를 사용한다. 실제 크롭되는 영역은 전체 이미지의 크기의 5%~100% 비율 사이로 선택한다. 그런 다음 크롭된 이미지를 224x224 크기로 resize 한 뒤 0.5의 확률로 horizontal flip을 수행한다. 평가시(validation)에는 이미지의 높이와 넓이 중 짧은 쪽에 대해 256 크기로 resize 한 뒤 중앙 크롭을 224x224 크기로 수행한다. 마지막에는 RGB 값으로 nomalization을 수행한다. (복잡하게 적었는데 그냥 ImageNet 전처리 생각하면 된다.)
-
Hyperparameter 배치(batch) 크기는 1024를 사용한다. 이는 8개의 P40 GPU에 들어갈수 있는 최대 배치 크기에 가깝기 때문이다. (실제로는 더 들어가기는 한다.) 초기 learning rate 는 0.4를 사용하고 weight decay는 0.0001을 사용한다. 기본적인 epoch값은 120이지만 모델에 따라 다를 수 있기 때문에 이런 경우에는 epoch을 명시적으로 기술한다. 0.9 momentum 값을 가지는 SGD를 사용한다.
-
Learning rate warmup 큰 배치 크기를 가지는 학습에서 learning rate가 큰 경우 종종 학습이 잘 안되는 경우가 있다. Goyal은 warmup 전략을 제시하였는데 학습 초반에 learning rate 을 0에서 초기 설정된 learning rate까지 선형으로 증가시키는 기법을 의미한다. 우리는 초기 5 step을 warmup으로 사용한다.
-
Zero \(\gamma\) 학습 시작시 Residual block 맨 마지막에 있는 BN(batch normalization) 의 \(\gamma\) 값을 0으로 두는 것을 의미한다. 이렇게 되면 학습 초기에는 모든 residual block 의 출력값이 0이 되어 shortcut 영역만 전파가 되게 된다. 이런 경우 학습 초기에는 모델 망의 깊이가 짧아지는 효과가 생겨 초반 학습이 더 잘되도록 한다.
-
Mixed-precision floating point 학습시 mixed precision을 사용한다. 만약 GPU에서 이 기능을 제공한다면 학습 시간을 많이 단축시킬 수 있다. 우리의 실험 결과 P40 에서는 FP32에 비해 약 1.2배의 속도 향상을, V100에서는 약 2배의 학습 속도 향상을 얻을 수 있었다. 하지만 top-1 정확도는 오르지 않았다.
-
Cosine learning rate decay (cosine) cosine learning rate는 학습 초기에는 learning rate 가 작게, 중반에는 크게, 다시 종반에는 작게 변하는 모양을 가진다. 그래서 이름이 cosine이다.
Evaluation Metrics
이 섹션에서는 성능 측정을 위한 평가 지표를 다룬다. 어떤 평가 지표를 사용할 것인가는 매우 중요한데 모델을 발전시키는 방향을 이 평가 지표를 기준으로 결정하기 때문이다. 우리는 다음과 같은 세 개의 평가 지표를 사용한다.
- top-1
- top-1 은 ImageNet ILSVRC-2012 validation 데이터의 top-1 정확도(accuracy)를 의미한다. validation 데이터셋은 50,000개의 데이터와 1,000개의 레이블로 구성된다.
- throughput
- throughput은 실제 GPU 디바이스에서 초당 처리할 수 있는 이미지 갯수를 의미한다. 우리는 모두 Nvidia P40 GPU 1대에서 측정한 결과를 사용한다. 이 때 다른 모델과의 비교를 위해 FP16대신 FP32 결과를 throughput 값으로 사용한다. (실제 FP16이 더 높은 throughput 값을 가진다.) 이 때 사용된 배치 크기는 64이다.
- mCE
- mCE는 mean corruption error로 Hendrycks에 의해 제안되었다. corrupt 이미지를 이용하여 분류 분제를 수행한 뒤 결과를 측정한다. 강건성(robustness)을 나타내는 지표이며 변경된 입력 이미지에 대해 모델이 얼마나 강건한지를 측정한다. 낮을수록 좋다.
Method
이 섹션에서는 다양한 network tweak과 regularization 기법들을 설명한다. 또한 서로 다른 파라미터를 선택할 경우에 대한 효과도 기술한다.
Model tweaks
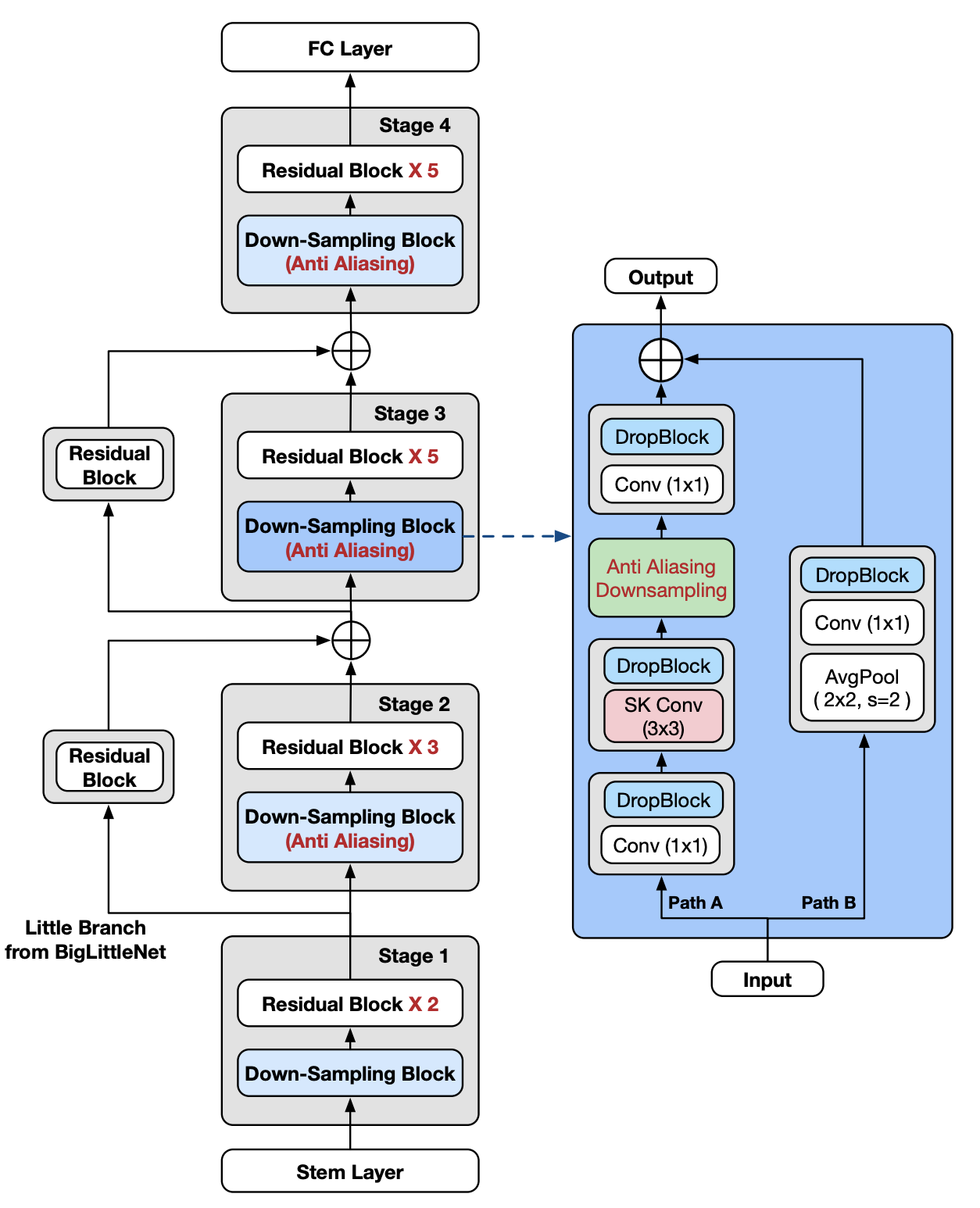
그림 1. Assembling techniques into ResNet-50.
우리는 ResNet-D, SK, Anti-alias, DropBlock, BigLittleNet과 같은 model tweak들을 ResNet-50에 적용하였다.
anti-aliasing 기법은 Stage 2 에서 Stage 4 까지 Downsample block에만 적용한다. DropBlock은 오로지 Stage 3과 Stage 4에서만 사용된다.
BigLittleNet의 Little-Branch 영역은 하나의 residual block을 사용하여 이 때 더 작은 width 크기를 가지게 된다.
그림 1은 우리의 최종 ResNet-50 모델을 기술한다. 다양한 network tweak들이 ResNet-50 모델에 적용되었다. 적용된 network tweak들은 다음과 같다.
ResNet-D
ResNet-D는 기본 ResNet 모델의 아주 일부분만 변경한 기법(trick)이다. 이 방식은 매우 실용적이고 연산 비용도 기존과 큰 차이가 없다. 기본 모델에서 총 3개의 영역이 변경되었으며 이에 대한 내용은 그림 2에 기술되어 있다. 우선 residual 영역의 첫번째, 두번째 convolution 블록의 stride size가 변경되었다 (그림2 파란색 영역). 두번째로 skip 영역에 사용되는 다음으로 convolution의 stride를 1로 변경하고 그 앞에 2x2 average pooling 레이어를 추가하였다 (그림2 녹색 영역). 마지막으로 step 레이어의 7x7 convolution을 3개의 3x3 convolution으로 대체한다 (그림2 붉은색 영역).
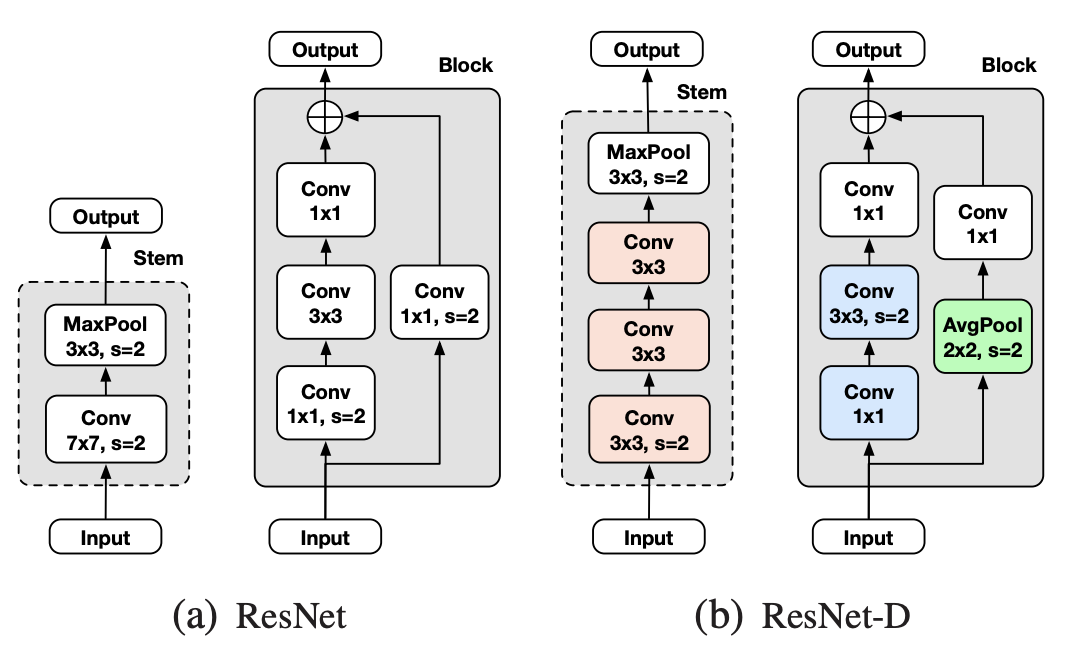
그림 2. ResNet-50과 ResNet-50D 변경된 영역의 비교
Channel Attention (SE, SK)
우리는 channel attention과 관련하여 두가지 tweak을 실험하였다. 먼저 SENet(Squeeze and Excitation Network)은 channel-wise 연결을 통해 표현력을 증가시킨다. SE는 global pooling을 사용하여 spatial 정보를 제거한 뒤 채널(channel) 정보만을 얻음 다음 2개의 FC 레이어를 사용하여 채널 사이의 correlation 을 학습한다. 두번째로 SKNet (Selective Kernel Network)은 인간의 시각 피질에서 뉴런의 수용 크기가 서로 다르다는 사실에서 영감을 받은 모델로 서로다른 커널 크기를 가지는 다중 브랜치(multiple branch)를 사용한다. 마지막으로 모든 브렌치는 softmax 레이어를 통해 합쳐진다(fuse).
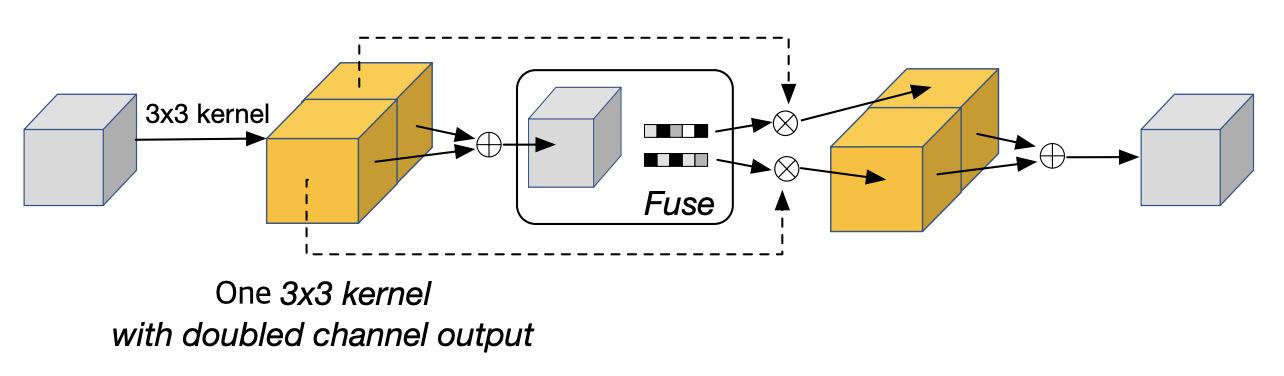
그림 3. 수정된 형태의 SK Unit.
원 논문에서는 3x3, 5x5 크기의 커널을 사용한 다중 브랜치 구조였으나 여기서는 두배의 출력 채널 크기를 가지는 하나의 3x3 커널을 사용한다.
SK 원 논문에서는 각각 3x3과 5x5 크기의 커널을 사용하는 다중 브랜치를 사용하지만 우리는 이를 두 개의 3x3 커널로 대체한다. 게다가 실제 구현에서는 하나의 3x3 커널을 사용하고 대신 출력 채널을 두 배로 키운 형태로 구현한다. 그림 3은 SK Unit을 하나의 3x3 convolution 연산으로 대체하는 것을 나타낸다.
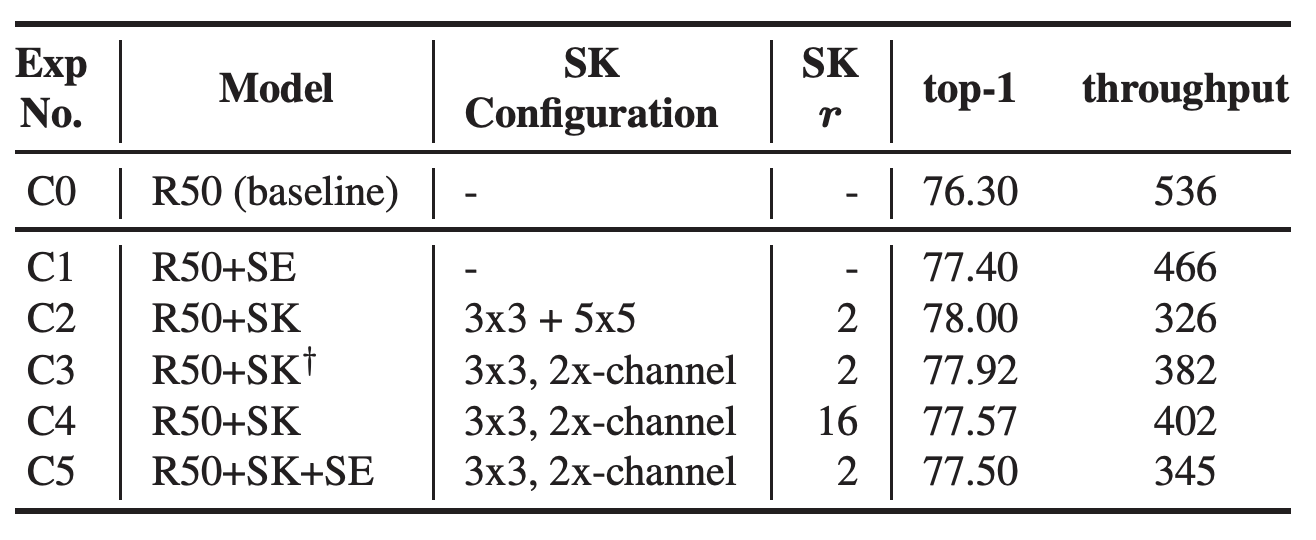
테이블 2.서로 다른 설정에 대한 channel attention 결과 요약. R50은 ResNet-50을 간단하게 표기한 것이다. lr은 0.4를 사용하고 총 120 epoch 학습 중 30,60,60 epoch 마다 0.1의 decay 비율을 사용한다. r는 SK 내의 Fuse 연산 영역에서 사용되는 reduction ratio를 의미한다.
테이블 2는 channel attention 관련하여 다양한 설정값에 따른 결과를 기술한다. SK와 SE 결과를 비교해보면 SE가 더 높은 throughput을 보이지만 accuracy는 더 낮음을 알 수 있다 (C1). C3는 C2와 비교해볼 때 accuracy가 0.08% 정도 낮지만 throughput의 차이는 크다. (326 vs. 382) accuracy와 throughput 사이의 트레이드 오프(trade-off)를 고려하여 우리는 하나의 3x3 커널을 사용하고 두 배의 채널 출력을 제공하는 C3 모델을 사용하기로 결정하였다. SK에는 \(\gamma\) 파라미터를 조절할 수 있는데 우리는 이를 2~16으로 변경해가면서 실험하였다. 모델 C3와 모델 C4를 비교해보면 \(\gamma\) 값이 커지면 throughput이 향상되지만 accuracy는 감소한다. 또한 SE와 SK를 모두 적용한 경우 오히려 accuracy와 throughput이 모두 감소함을 확인하였다 (C5). 따라서 최종 모델로 R50+SK\(^{\dagger}\) 모델을 사용한다.
Anti-Alias Downsampling (AA)
CNN 모델은 입력 이미지의 작은 변화에도 동일한 결과를 내어주는데 상당히 취약하다는 사실이 알려져있다. Zhang은 shift-equivariance 를 향상시키기 위해 AA를 제안하였다. max pooling 연산은 큰 관점에서 보면 경쟁적인 downsampling으로 간주될 수 있고 본질적으로 두 개의 연산으로 구성된다. 먼저 max 연산을 수행하고 다음으로 sampling을 수행한다. AA는 이 두 연산 사이의 low-pass filter처럼 동작하는 기법을 제안한다. 이 방식은 구조상 stride 값을 활용하는 어떠한 연산에도 적용될 수 있다. 원래의 논문에서는 AA는 ResNet 내부의 max-pooing, projection convolution, strided convolution에 적용된다. 추가적으로 smoothing factor를 사용하여 커널의 크기를 조절할 수 있게 한다. 이를 통해 blur 정도를 조절할 수 있으며, 더 큰 filter 크기를 사용하면 입력되는 데이터를 더욱 blur하게 만든다. 우리는 filter의 크기를 5에서 3까지 조절해가면서 accuracy의 변화를 확인해 보았다. (테이블 3 참고) 하지만 projection convolution 에서 AA를 제거해도 정확도에 큰 차이를 보이지 않았다 (A3). 또한 max-pooling에 이를 적용하는 것은 throughput을 크게 감소함을 확인하였다 (A1-3). 최종적으로 우리는 AA 를 strided convolution 영역에만 적용한다. (그림 1의 녹색 영역을 참고.)
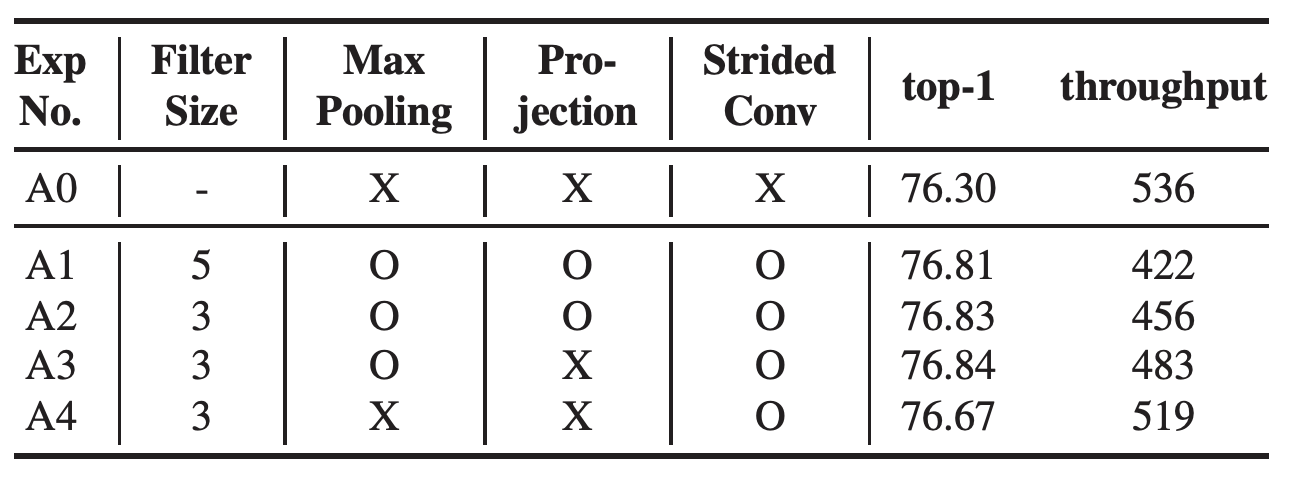
테이블 3.AA를 적용한 결과. 모든 실험을 ResNet-50에서 진행하였으며 최종적으로 A4 모델을 선택하였다. lr은 0.4로 시작하고 총 120 epoch 에 30,60,90마다 0.1의 decay 비율을 적용하였다.
Big Little Network (BL)
BigLittleNet은 서로 다른 크기의 resolution을 가지는 입력을 다중 브랜치에 입력하여 전체 연산량을 줄이는 대신 accuracy는 올리는 기법이다. Big-Branch 부분은 원래의 기본 모델을 그대로 사용하는 대신 입력 이미지의 크기(resolution)를 더 작게 사용한다. 대신 Little-Branch 영역은 원래 사용하던 이미지 입력 크기와 동일한 크기를 사용하되 사용하는 convolution 레이어의 개수를 줄인다. BigLittleNet에는 두개의 파라미터 \(\alpha\) 와 \(\beta\) 가 존재한다. 이는 각각 Little-Branch 영역의 width와 depth 를 조절하기 위한 파라미터이다. 우리는 ResNet-50 모델에서는 \(\alpha=2\), \(\beta=4\)를 사용하고, ResNet-152에서는 \(\alpha=1\), \(\beta=2\)를 사용한다. 그림 1에서 맨 왼쪽에 표현된 브렌치가 Little-Branch를 의미한다. Little-Branch에서는 하나의 residual block을 사용하고 더 작은 크기의 width 를 사용한다.
Regularization
AutoAugment (Autoaug)
AutoAugment는 데이터 augmentation 기법으로 데이터를 통해 augmentation 전략을 자동으로 구성하는 기법이다. 강화 학습 기법을 이용하여 입력 이미지의 augmentation 연산들의 순서를 결정한다. 우리는 이를 직접 생성하지 않고 논문에서 제공하는 ImageNet-ILSVRC-2012 용 AutoAugment 전략을 그대로 차용하여 사용한다. (링크)
Mixup
Mixup은 학습셋에 포함된 두 개의 이미지를 샘플링한 뒤 이를 interpolating 하여 새로운 이미지를 생성하는 방법이다. 신경망은 데이터로부터 정보를 생성하기보다는 그대로 기억을 해버리는 습성이 있다고 알려져있는데 그 결과 학습 데이터와는 다른 분포를 가진 이미지가 입력되었을 경우 예상하지 못한 출력값을 내어주는 경우가 존재한다. Mixup은 이러한 문제를 보정하기 위해 학습 데이터를 interpolation하여 모델의 feature 공간에 빈 곳이 생성되지 않도록 보정하는 기법이다. 실제 구현에는 2가지 방법이 존재한다. 첫번째는 두개의 mini-batch 를 섞어 mixup된 하나의 mini-batch 를 만드는 방법이다. 이는 원 논문에서 제안된 방식이다. 두번째로는 하나의 mini-batch 를 섞고 잘 셔플링하여 mixup된 하나의 mini-batch를 만드는 방법이다. 이 경우 실제 CPU 리소스를 더 적게 사용할 수 있다. 하지만 우리는 실험을 통해 첫번째 방식을 사용하기로 결정하였다. (테이블 4 참고) Mixup에 사용된 하이퍼파라미터 \(\alpha\) 는 0.2 를 사용하였다.

테이블 4.Mixup을 적용한 결과. 이후 실험에서는 type=1 방식을 사용하였다. E2, E3 표기는 테이블 7에 사용된 모델의 이름을 의미한다.
DropBlock
Dropout은 신경망의 regularization 기법으로 잘 알려진 기법이다. 이 방법은 학습 중 일부 뉴런을 의도적으로 제거하여 학습 데이터에 대해 overfitting을 방지하는 효과를 가져다 준다. 하지만 이 기법은 ResNet 과 같은 모델에서는 아주 훌륭하게 동작하는 것은 아니다. DropBlock은 실제 activation 의 연속적인 범위를 고려하여 제거(drop)하기 때문에 semantic 정보를 제거할 수 있게 해준다. 이 결과 좀 더 효율적인 regulrazation 효과를 가져다 준다. 우리는 원 논문에서 사용한 설정을 그대로 사용한다. ResNet-50 모델의 Stage 3 과 Stage 4 에 적용하고 학습시 \(keep\_prob\) 값은 0.9를 사용한다.
Label Smoothing (LS)
분류 문제를 푸는 경우에 클래스 레이블은 보통 one-hot 방식으로 표현된다. (정답인 경우 1, 아닌 경우 0) 만약 분류 문제에서 loss 로 cross-entropy를 사용하고 one-hot 방식을 사용하는 경우 마지막 FC 레이어에서의 logit 값이 무한대가 될 수도 있다. LS는 이러한 것을 방지해준다. (이와 관련하여 궁금하신 분들은 Bag of tricks에서 LS 영역을 살펴보아도 된다.) 우리는 smoothing factor \(\epsilon\) 을 0.1로 사용한다.
Knowledge Distillation (KD)
KD는 선생(teacher) 모델로부터 학생(student) 모델이 지식을 전수(?)받는 기법을 의미한다. Teacher 모델은 보통 더 크고 무거운 모델을 사용하고 (대신 accuracy는 더 좋은) Strudent 모델은 상대적으로 더 가벼운 모델을 사용한다. Teacher 모델의 정보를 받아들여 Student 모델의 accuracy를 좀 더 향상시킬 수 있다. 원래의 논문에서는 KD의 하이퍼파라메터인 \(T\) 를 2 또는 3으로 사용하기를 권장한다. (T는 온도를 의미하는 파라미터이다.) 하지만 우리는 \(T=1\) 을 사용하여 학습을 수행하였다. 우리의 모델에서는 Student 모델에 Mixup과 같은 regulration 기법을 적용하기 때문에 마찬가지로 Teacher 모델에도 Mixup을 적용해야 한다. Mixup에 의해 smoothing 되는 효과 있기 때문에 KD에서는 더 낮은 온도 T값을 사용하는 것이 더 좋은 결과를 얻을 수 있다. 우리는 Teacher 모델로 AmoebaNet-A 를 사용하였다. 이 모델의 ImageNet-2012 top-1 accuracy는 83.9% 이다. (ResNet-152의 경우 Teacher 모델로 EfficientNet-B7)을 사용한다.

테이블 5. KD 온도를 변화시켜가면서 확인한 결과. E6과 E7는 테이블 7에 기술된 모델을 의미한다. 최종적으로 T=1을 선택하였다.
Experiment Results
Ablation Study
이번 섹션에서는 network tweak을 조립(assembling)하는 ablation 실험을 진행한다.
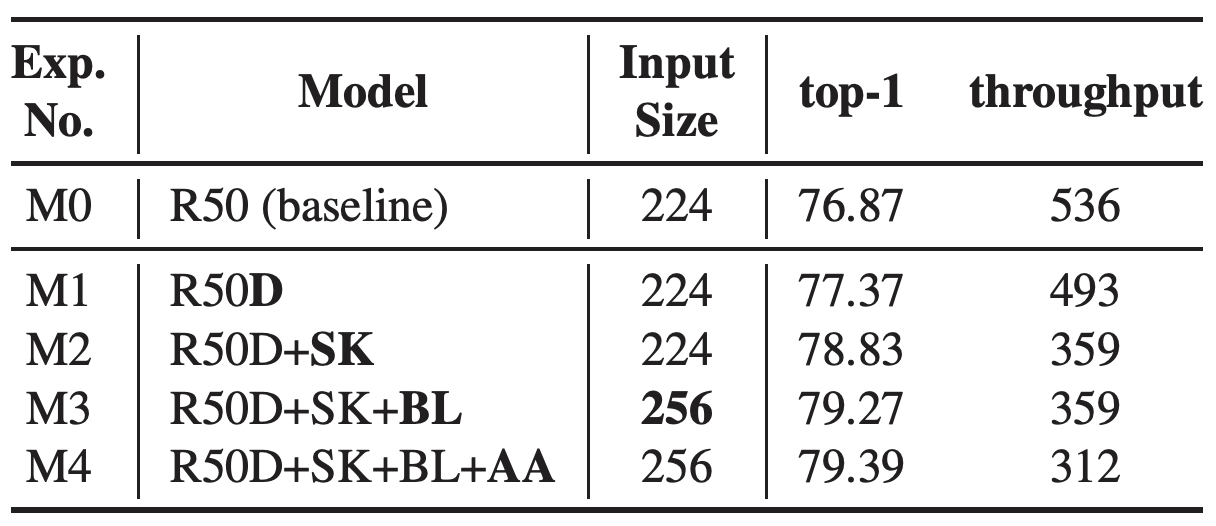
테이블 6. network tweak을 쌓아가면서 성능을 비교. ResNet-D, SK, BL, AA를 올려가면서 ResNet-50의 성능이 향상되는 것을 확인한다. 물론 throughput의 감소도 함께 일어난다. 각 모델별로 적용된 기법들은 볼드체를 사용하여 기술하였다. 모든 실험에서는 cosine lr decay가 사용되었다.
기본 모델에 ResNet-D를 추가하면 약 0.5%의 성능 향상이 있다 (M1). 여기에 SK를 추가하면 다시 1.46%의 성능 향상이 있다 (M2). 앞서 테이블 2에서는 SK를 단독으로 기본 ResNet에 적용하였을 경우 1.62%의 성능 향상이 있음을 확인하였다. ResNet-D 와 SK를 함께 추가한 경우 ResNet-D와 SK를 기본 모델에 각각 적용한 것을 더한만큼과 비슷한 성능 향상을 얻을 수 있다. 이 결과는 두 개의 tweak이 서로간의 영향을 최소화 하면서 독립적으로 성능 향상에 기여를 하고 있음을 확인할 수 있다. 여기에 다시 BL을 추가한 경우 accuracy가 0.44% 증가한다 (M3). 우리는 M3가 M2 모델과 최대한 비슷한 throughput을 유지하면서도 더 좋은 accuracy를 만들기 위해 inference시 M3의 입력 크기를 224x224 대신 256x256을 사용하였다. (학습시에는 기존대로 224x224를 입력으로 사용한다.) M3에 AA를 적용하는 것은 0.12%의 성능 향상을 가져온다. 대신 throughput은 47 하락한다 (M4). AA는 모델의 강건성(robustness)과 관련된 기법이기 때문에 top-1 accuracy에는 크게 영향을 미치지 못하였다. AA의 대한 효과는 mCE 결과를 설명하면서 더 다루도록 한다.
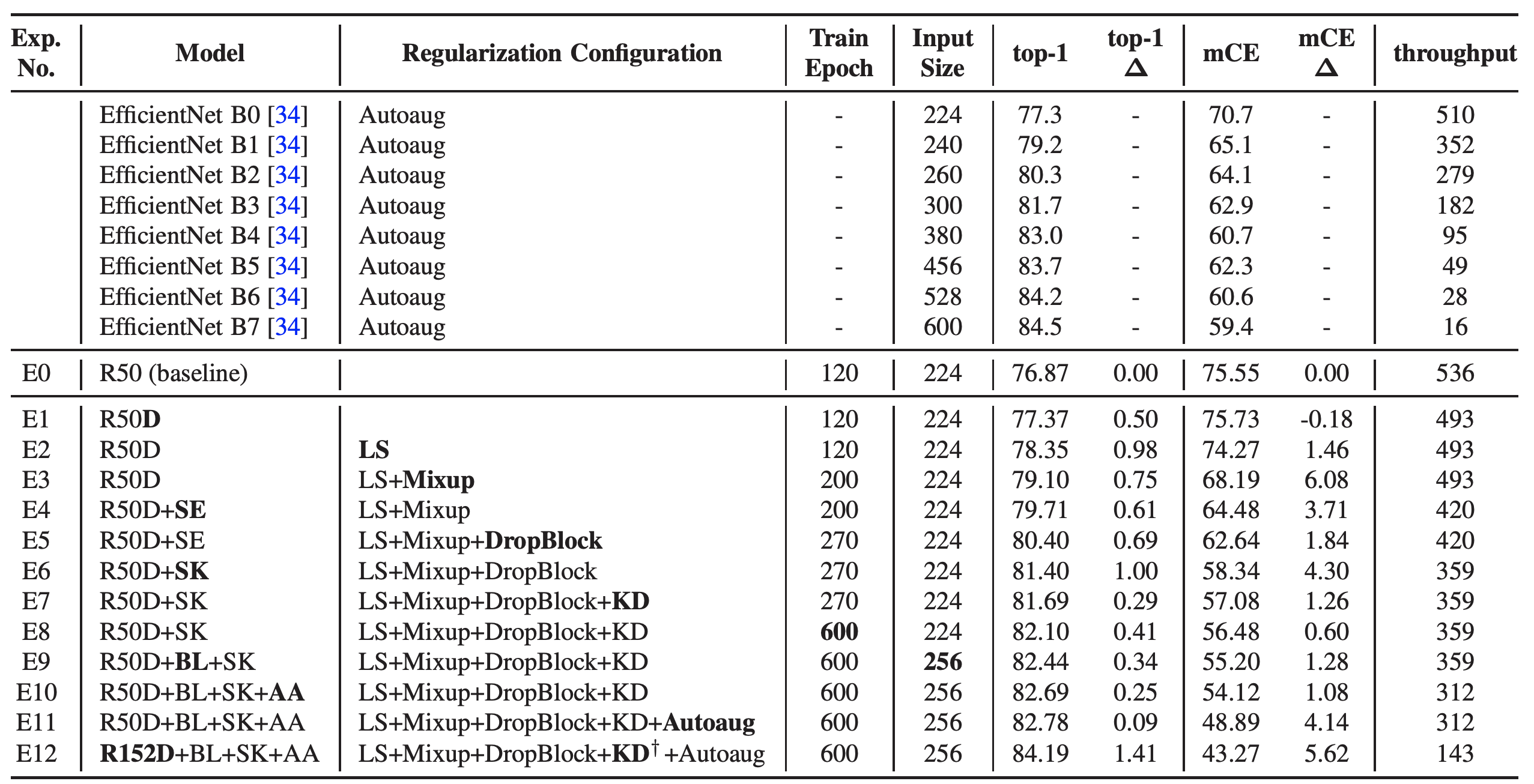
테이블 7. network tweak과 regularization을 ResNet-05 모델에 적용한 결과. ImageNet ILSVRC2012 데이터를 사용한다. 각 모델의 주요한 영역은 볼드체로 표기하였다. 모든 실험에서 cosine lr decay가 사용되었다. 비교를 위한 EfficientNet의 top-1 accuracy와 mCE 점수는 아래 링크된 경로로부터 얻어왔다. 모든 throughput은 1대의 NVIDIA P40 장비에서 측정되었다. EfficientNet는 official 코드를 사용한다. 최종 모델의 비교를 위해 ResNet-152 도 실험하였다. 이 때 ResNet-152에는 Teacher 모델로 EfficentNet-B7을 사용한다.
테이블 7은 섹션 3.2에서 서술한 기법들을 조립한 결과이다. 우리는 network tweak과 regularization을 교차로 쌓아가면서 성능의 밸런스를 맞추었다. regularization 기법들은 accuracy와 mCE의 성능을 모두 올리지만 accuracy 보다는 mCE의 성능 향상이 더 컸다. 예를 들어 Mixup, DropBlock, KD, Augoaug는 top-1 accuracy를 순차적으로 0.75% 0.69%, 0.29%, 0.09% 올리는 동안 mCE는 6.08%, 1.84%, 1.26%, 4.14% 만큼 향상시킨다. 이것은 regularization이 CNN을 이미지 distortion에 대해 더 강건한 모델로 만든다는 것을 보여준다.
SE를 추가하면 top-1 의 성능이 0.61% 상승하고 mCE는 3.71% 상승한다 (E4). SE는 mCE의 성능도 regularization 기법만큼이나 크게 올리는 것을 확인하였다. 우리는 channel attention 기법이 강건성(robustness)에도 많은 도움을 준다는 것을 확인하였다.
SK를 SK로 대체하는 경우 accuracy는 1.0% 향상되고 mCE는 4.3% 향상된다 (E6). 테이블 2에서 기본 모델에 SE를 SK로 변경하는 경우 0.5%의 accuracy 향상이 있었다. regularization 없이 SE를 SK로 변경하는 것보다 약 2배의 성능 향상을 얻을 수 있음을 확인하였다. 이것은 SK가 SE 보다 regularization 기법과 더 보완적임을 확인할 수 있다.
학습 Epoch를 270에서 600으로 변경을 하면 성능이 향상된다 (E8). 이는 데이터 augmentation과 regularization을 쌓아 올렸기 때문에 더 긴 epoch을 요구하기 때문이다. BL은 top-1 accuracy 성능 향상 뿐만 아니라 mCE의 향상도 있는데 그럼에도 불구하고 throughput의 감소는 없었다 (E9). AA 또한 더 좋은 성능을 얻었다 (E10).
최종적으로 앞서 설명한 우리의 assemble 모델은 82.78%의 top-1 accuracy와 48.89%의 mCE를 얻었다. 테이블 7에 기술된 최종 모델 E11을 Assemble-ResNet-50 이라 부르기로 한다. 또한 비교를 위해 ResNet-152 모델도 실험하였는데 (E12) 이를 Assemble-ResNet-152 라 부른다.
Transfer Learning (FGVC)
이번 섹션에서는 tensfer learning 에 대해 다룬다. 우선 Food-101 공개 데이터에 대해 ablation 실험을 수행한다. 이 데이터는 FGVC task를 위한 유명 공개 데이터셋이다. 실험을 위해 다음과 같은 설정을 사용한다.
- 초기 lr 은 0.1 에서 0.01로 줄인다.
- weight decay 는 0.01 로 설정한다.
- Batch norm 의 momentum 은 \(\max(1-10/s, 0.9)\) 로 설정한다.
- DropBlock 의 keep_prob 는 0.9로 시작하여 학습 완료시 0.7까지 선형 감소한다.
- 데이터셋마다 다른 epoch를 사용한다. (Appendix.B를 참고)
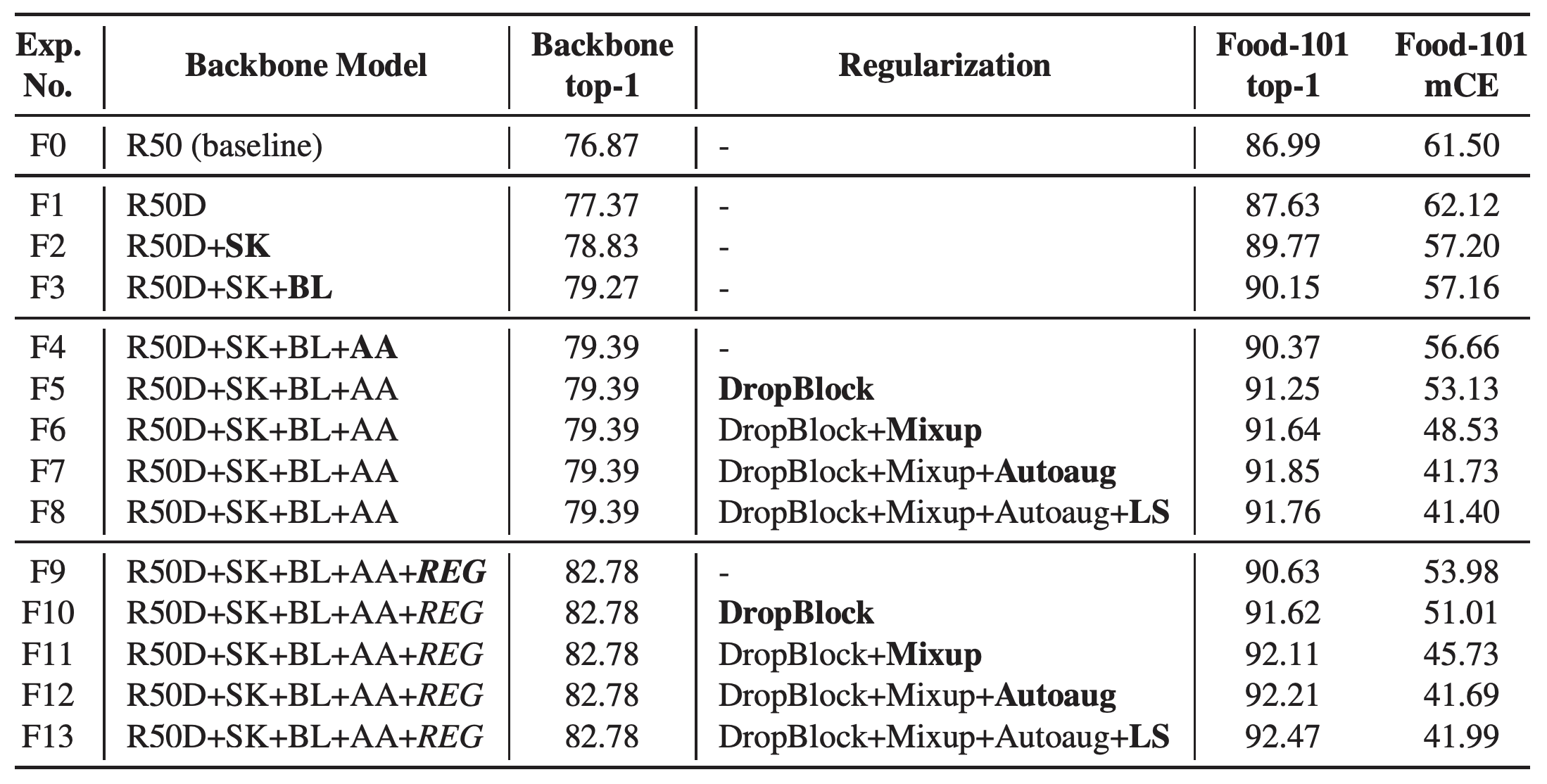
테이블 8. Food-101 데이터셋에 대한 Tansfer learning 실험. REG는 "LS+Mixup+DropBlock+KD+Autoaug"를 의미한다. Food-101 은 mCE를 계산할 때 AlexNet error 값으로 normalization 하지 않는다. Autoaug 적용시 사용한 전략은 CIFAR-10을 위해 만들어진 전략을 가져다 사용하였다.
테이블 8은 Food-101 데이터셋에 대해 network tweak과 regularization을 조립(assembling)하면서 accuracy와 mCE 값을 확인하는 ablation 실험 결과이다. 특히 백본에 regularization을 적용한 것(F9-13)과 하지 않은 것(F4-8)에 대한 결과를 확인할 수 있다. F4에서 F13까지 모두 동일한 모델을 사용하고 있지만 적용되는 regularization은 모두 다르다. 백본 모델에 regularization을 적용하는 것은 Food-101 의 top-1 accuracy 성능을 올리는데 도움을 준다. 반면 mCE 성능은 accuracy와 양상이 조금 다른데 F4, F9처럼 fine-tunning시에 regularization을 사용하지 않는 경우 백본에 regularization을 적용한 경우가 더 좋은 mCE 성능을 가진다. 하지만 fine-tunning시에 regularization을 적용하는 경우에는 mCE의 차이가 크지 않다. 편의를 위해 마지막 F13 모델을 Assemble-ResNet-FGVC-50 이라고 부른다.
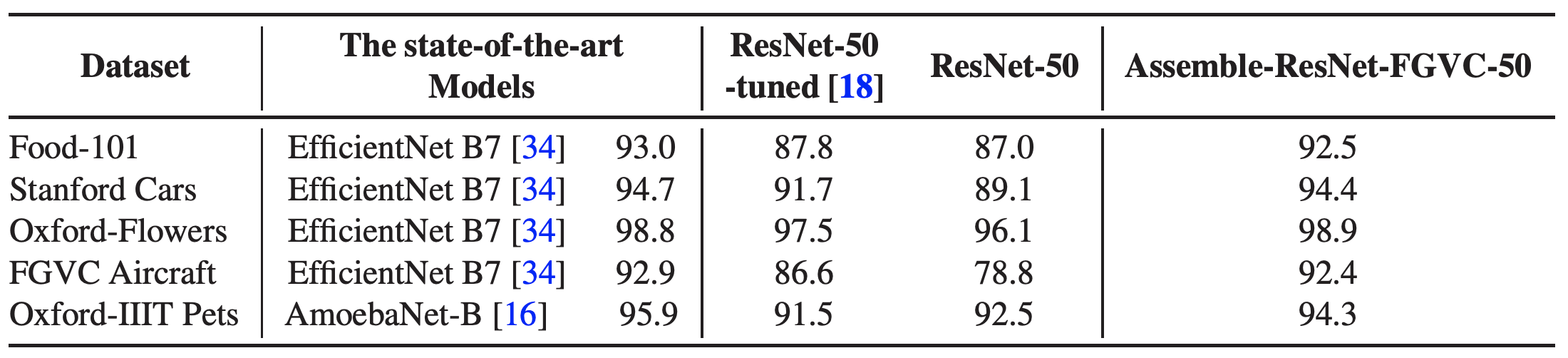
테이블 9. 제시한 모델과 다른 SOTA 모델과의 성능 비교. 다양한 FGVC 데이터셋으로 평가하였다. ImageNet 기반의 transfer learning은 single crop만을 사용하여 비교한다. Assemble-ResNet-FGVC-50은 테이블 8에서 기술된 F13 모델을 의미한다. ResNet-50-tuned 는 Kornblith 논문에서 발췌한 것으로 learning rate와 weight decay를 잘 조절하여 성능을 올렸을 때의 결과이다. 안타깝게도 해당 논문에는 사용된 하이퍼파라메터 값이 기술되어 있지 않다. 우리의 실험에서는 하이퍼파라미터에 대한 최적화 작업은 진행하지 않았는데 이 실험의 목표가 SOTA 모델 만큼 성능을 끌어올리는 것이 아니라 Assemble-ResNet-FGVC-50과 기본 ResNet-50 모델의 성능 비교를 하는 것이기 때문이다. Assemble-ResNet-FGVC-50은 ResNet-50보다 훨씬 좋은 성능을 낼 뿐만 아니라 모든 데이터셋에 대해 SOTA 모델과 견주어도 성능이 크게 차이가 나지 않는다.
우리는 또한 다음과 같은 데이터셋에 대해 실험을 진행하였다.: Stanford Car196, CUB-200-2011, Oxford 102 flowers, Oxford-IIIT Pets, FGVC-Aircraft, Food-101. 이 데이터셋에 대한 기본적인 통계 정보는 Appendix.C에 기술하였다. 기본적인 파라미터 정보는 Kornblith 의 연구로부터 얻어와 사용하였다. 모든 백본은 앞서 실험한 Assemble-ResNet-50 모델을 사용한다. 테이블 9에서는 우리가 진행한 transfer learning 을 SOTA 모델인 EfficientNet 과 AmoebaNet-B 와 비교한다. Assemble-ResNet-FGVC-50의 경우 비슷한 정확도를 보이면서도 실제 inference throughput이 P40 GPU 장비에서 약 20배 정도 빠름을 확인하였다.
Transfer Learning (Image Retrieval)
우리는 3개의 데이터셋을 이용하여 IR (Image Retrieval) task를 실험하였다. : Stanford Online Products(SOP), CUB200, CARS196.
IR task를 평가하기 위해서는 zero-shot을 위한 데이터 분할이 필요한데 이에 대한 방법은 이 논문에서 가져왔다. 기본적인 하이퍼파라메터 설정은 다음과 같다.
- 이미지 전처리는 224x224 를 사용하되 0.5의 확률로 aspect ratio를 유지하지 않는다. 256x256으로 resize한 뒤 0.5의 확률로 224x224 크기를 random crop한다.
- 데이터 augmentation은 0.5의 확률로 random flip을 사용한다.
- Batch Norm에서 사용회는 momentum 은 \(\max(1-10/s,0.9)\)를 사용한다.
- weight decay는 0.0005를 사용한다.
- 학습 데이터에 따라 epoch, batch size, lr decay를 다르게 사용한다. (Appendix.D 참고)
IR 에서는 cosine-softmax loss 를 사용한다. 이중 SOP 데이터는 ArcFace loss 를 사용한다. 이 때 사용되는 margin은 0.3이다. 또한 GeM (generalized mean-pooling)을 사용하는데 이는 백본의 Stage 4 영역에 사용되는 pooling을 대체한다. IR task에서는 이런 방식이 더 좋은 성능을 얻었다.
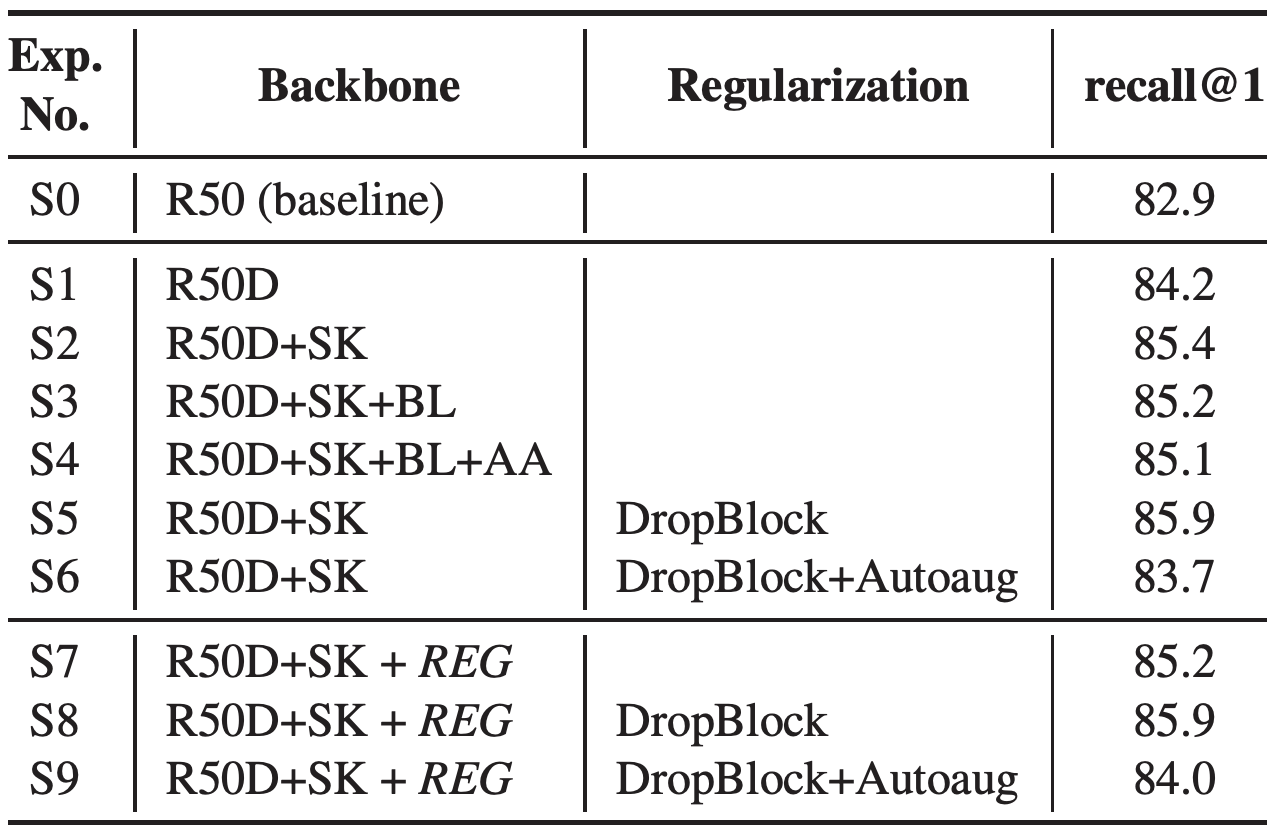
테이블 10. SOP 데이터로 IR task에 대한 transfer learning ablation 실험 결과. REG는 "LS+Mixup+DropBlock+KD"를 의미한다.
테이블 10은 SOP에 대한 ablation 실험 결과를 나타낸다. SOP 데이터셋의 경우 FGVC task와는 다르게 network tweak과 regularization을 다르게 조합하였을 때 더 좋은 성능을 보였다. S2-4 결과에서는 BL과 AA가 SOP 데이터에 대해 더 좋은 결과를 얻지 못하였다. regularization에서도 DropBlock은 잘 동작했지만 Augoaug는 recall@1의 성능을 증가시지키 못했다. 그럼에도 불구하고 ResNet-50 기본 모델과 비교할 때 최고 3% 정도의 성능 향상이 있었다. (S5, S8 모델)
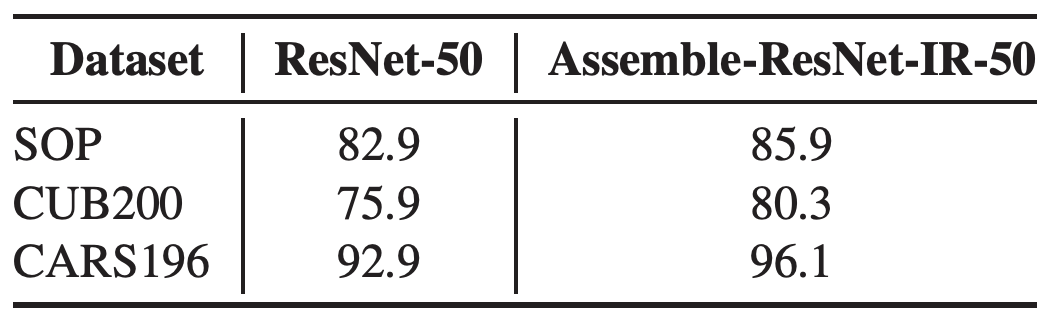
테이블 11. 여러 공개 데이터에 대한 IR transfer learning 결과. Assemble-ResNet-IR-50은 각 데이터에 대해 가장 높은 성능을 내는 백본 모델을 의미한다. 이에 대한 내용은 Appendix.D에 기술하였다. Assemble-ResNet-IR-50 의 결과가 기본 모델에 비해 확연한 성능 향상이 있음을 확인하였다.
다양한 데이터셋에 대한 실험 결과는 테이블 11에 기술되어 있다. CUB200과 CAR196에서도 더 좋은 성능을 보임을 확인하였다.
Conclusion
이 논문에서는 CNN 에 다양한 기법(technique)들을 적용하여 top-1 accuracy와 mCE가 향상되는 것을 확인하였다. 다양한 network tweak과 regulaization 기법을 하나의 네트워크에 통합하여 좋은 시너지 효과를 보임을 확인하였다. 또한 FGVC와 IR task를 통해 transfer learning 에서도 잘 동작하는 것을 확인하였다. 더 기대되는 것은 우리가 사용하는 모델이 이미 완성된 것이 아니라 여전히 변화하고 있다는 것이다. 우리는 현재 새롭게 추가된 여러 기법들을 적용하여 실험하는 것을 계획 중이다. 예를 들어 최근에 나온 AugMix, ECA-Net 등을 조합하는 실험을 계획하고 있다. 더 나아가 ResNet 외에도 예를 들면 EfficientNet과 같은 모델로 백본을 교체하여 실험을 한다면 더 좋은 결과를 얻을 수 있을 것이라 예상해본다.
Appendix
FLOPS & throughput
우리는 여러 실험을 통해 FLOPS와 throughput이 실제 GPU 장비에서 일치하지 않는다는 것을 확인하였다.
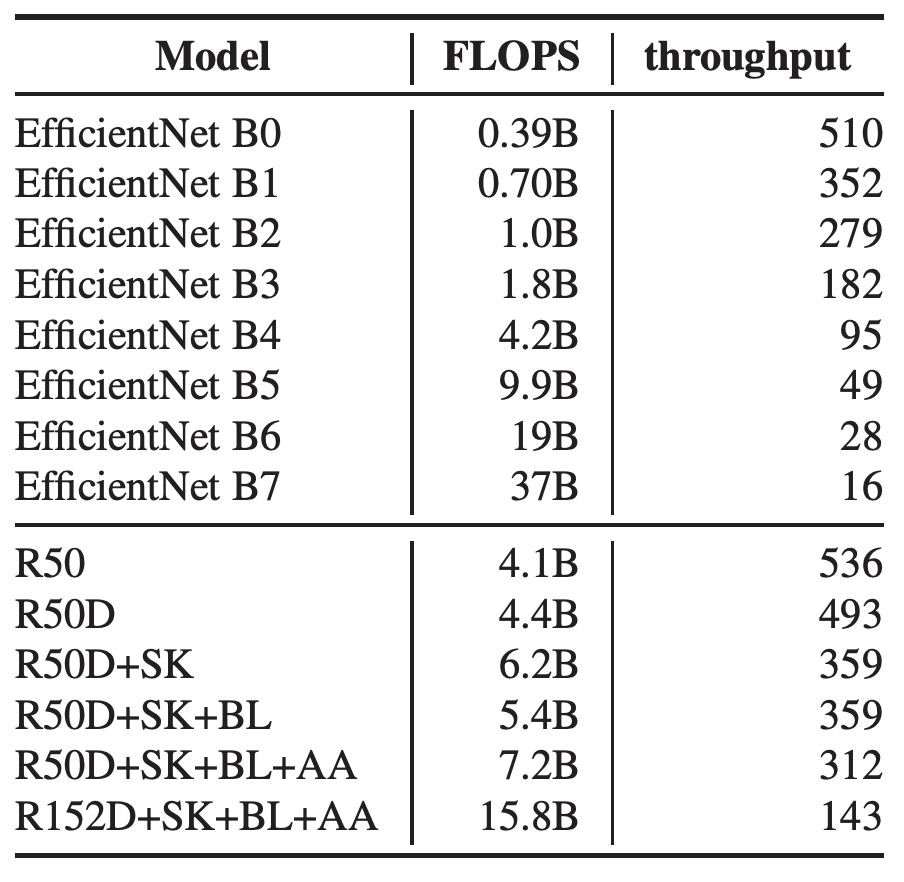
테이블 12. model tweak에 따른 FLOPS와 throughput의 변화. FLOPS는 TensorFlow official code에 포함되어 있는 profiler를 통해 측정하였다. EfficientNet의 FLOPS는 EfficientNet 논문으로부터 발췌하였다.
FGVC Configuration
우리는 tansfer learning시 최대한 동일한 하이퍼파라미터를 사용하려고 하였다. 테이블 13은 데이터셋마다 다른 하이퍼파라미터 설정을 나타낸다.
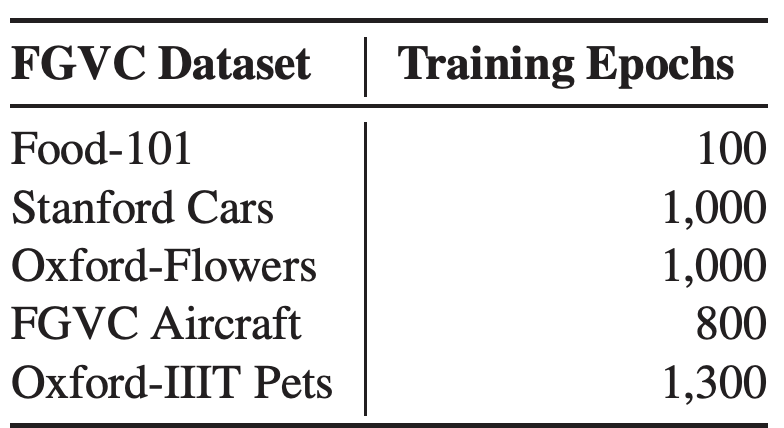
테이블 13.FGVC 데이터셋 학습 설정
FGVC Datasets
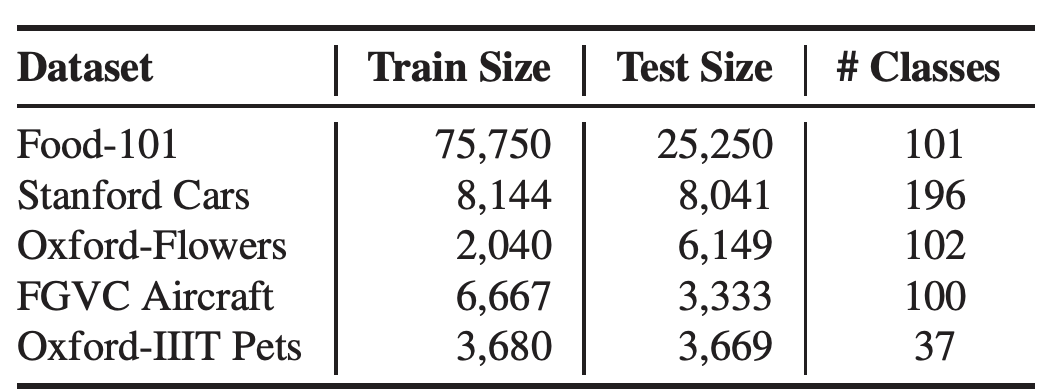
테이블 14.FGVC 데이터셋 통계 정보
IR Configuration
IR의 경우 각각의 데이터마다 다른 regularization을 사용하였다.
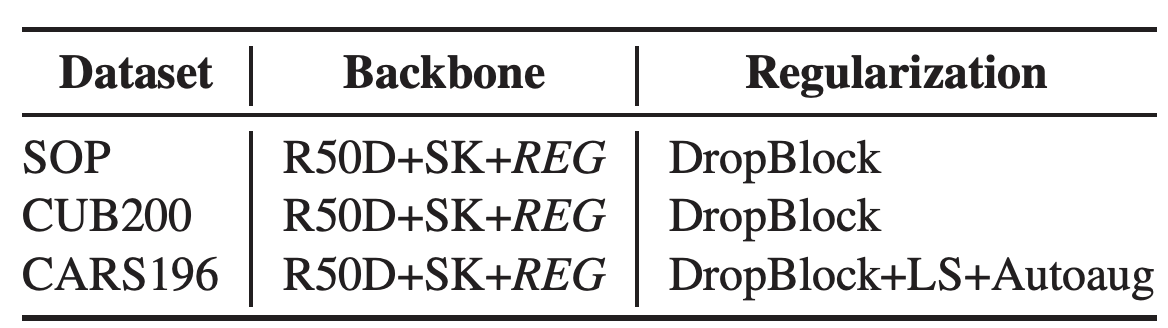
테이블 15.데이터셋에 따른 모델 설정. REG는 "LS+Mixup+DropBlock+KD"를 의미한다.
우리는 tansfer learning시 최대한 동일한 하이퍼파라미터를 사용하려고 하였다. 테이블 16은 데이터셋마다 다른 하이퍼파라미터 설정을 나타낸다.
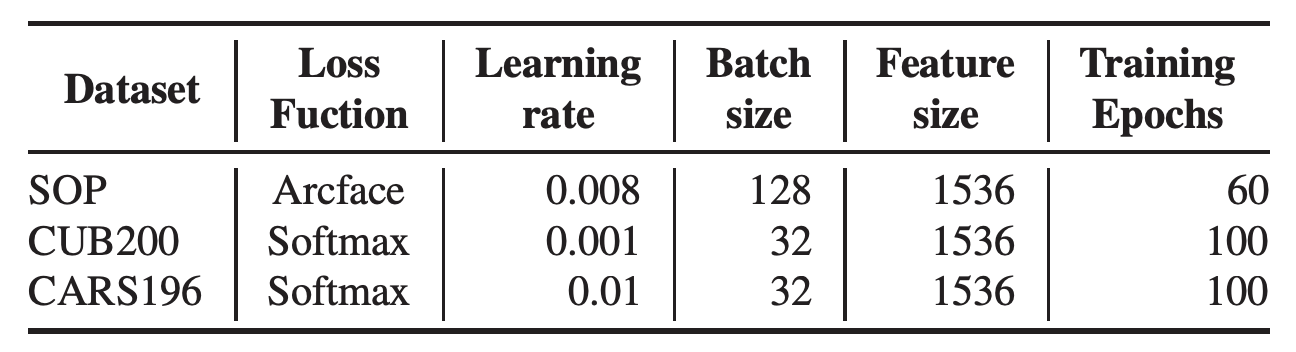
테이블 16.데이터셋에 따른 서로 다른 하이퍼파라미터 설정.