Bag of Tricks for Image Classification w/ CNN.
Introduction
- 이미지 분류 영역에서는 2012년 Alexnet을 시작으로 CNN 방식이 표준 방식으로 자리잡음
- 이후로 새로운 아키텍쳐들이 쏟아져 나왔다.
- VGG, NiN, Inception, ResNet, DenseNet, NASNet
- 모두 ImageNet의 정확도를 계속 올려놓았다.
- 그런데 이러한 품질 성능 개선이 단지 모델만 바꾸는 과정으로 이루어진 것인가? => “No”
- 학습 방법을 변화시켜 얻어진 결과도 많다.
- Loss 함수를 변경해서.
- 데이터 입력 전처리를 변경해서.
- 최적화(optimazation) 방법을 변경해서.
- 지난 십여년간 이러한 방향으로 엄청나게 많은 기법들이 제안되었지만… 사실 그렇게 많은 주목을 받지는 못했다.
- 게다가 정리도 잘 안되어 있어서 그냥 소스 코드 상에서만 존재하는 trick 도 많았다.
- 여기서는 이런걸 모아본다. (trick 모으기 정도로 해두자)
- 이후에 살펴보겠지만 이런 꼼수(trick)를 적용하면 성능이 올라간다.
- 하지만 여러 꼼수를 다양한 모델에서 비교하기 어려우니 ResNet-50 모델을 기준으로 이를 적용해보고 성능을 비교해본다.
- 물론 이런 방식이 Inception.V3 와 MobileNet 에서도 동일하게 적용됨을 확인하였다.
Outline
- 평가를 시작하기 앞서 가장 먼저 baseline 을 구성한다. (Section.2)
- 다음으로 논의된 trick 들을 이 모델에 적용해본다. (Section.3)
- 3개의 minor한 모델 변화를 시도하고 품질을 확인해본다. (Section.4)
- 4개의 추가적인 정제 작업을 시도해보고 이를 논의한다. (Section.5)
- 더 효율적인 방법은 없을지 고민해본다. (Section.6)
학습 방법 (Training Procedures)
- 기본적인 학습 방법은 Alogrithm.1 에 정리해 두었다.

- 뭐, 특별한 것은 없다. (전형적인 CNN 학습 구조)
- 사실 이러한 알고리즘을 구현하는데 있서 다양한 hyper-parameter가 활용될 수 있다.
- 즉, 서로 다른 방식으로 구현될 수 있다는 이야기이다.
- Section.1 에서는 Algorithm.1 에 대한 실제 구현 방식을 서술한다.
Baseline Training Procedure
- 여기서는 다음의 방식으로 ResNet을 구현하고 이를 baseline으로 삼는다.
- 참고로 학습(training)과 평가(validation)를 위한 전처리(preprocessing)는 서로 다르게 처리된다.
- 학습(tranining) 과정은 매 스탭대로 진행된다.
-
- 랜덤 샘플링을 통해 이미지를 추출하고 이를 32bit float 타입 객체로 변환한다. (\([0, 255]\)
-
- 다음 과정을 거쳐 직사각형의 이미지를 얻는다.
- 영역 크기는 \([8\%, 100\%]\) 범위 내에서 Aspect-ratio 를 \([3/4, 4/3]\) 사이 값으로 랜덤 샘플링한 영역을 크롭(crop).
- 그 다음에 224x224 크기의 이미지로 resize_and_crop 작업을 수행.
-
- 50% 확률로 flip. (이미지 좌우 회전)
-
- hue, saturation, brightness 조절 값을 \([0.6, 1.4]\) 사이의 값을 랜덤하게 하나 뽑아 적용.
-
- \(N(0, 0.1)\) 분포에서 값을 하나 샘플링하여 PCA noise 를 추가함.
-
- RBG 채널에 대해 \((123.68, 116.779, 103.939)\) 값을 빼준다. (평균값 보정)
- 위의 과정을 진행하는 과정에서 Aspect-ratio 를 적용할 때 짧은 축을 256 으로 만들어 resize 하고 224x224 는 center crop 으로 수행한다.
- 설명이 길었지만 VGG 이미지 전처리 방식과 거의 유사하다.
- 모든 conv 레이어에는 Xavier 초기화를 사용한다.
- 모두 Nesterov Accelerated Gradient (NAG) 가 적용되었고 120 epoch 까지 학습힌다.
- 8개의 v100 GPU 장비에서 테스트 되었다. batch size 는 128이다.
- lr 은 0.1 로 초기화시키고 (30, 60, 90) 번째 epoch 마다 10.0 으로 나누어준다.
실험 결과
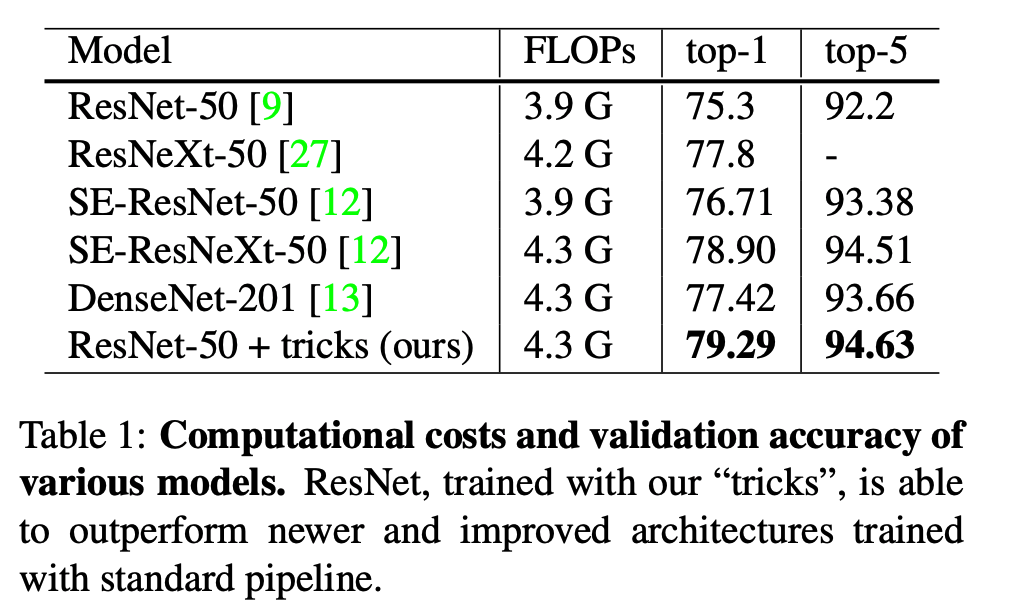
- 다음 모델에 대해 실험해본다.
- ResNet-50
- Inception-V3 (단, 입력이 299x299 이다.)
- Mobilenet
- 사용된 데이터는 ImageNet (ISLVRC2012-1000class) 데이터이다.
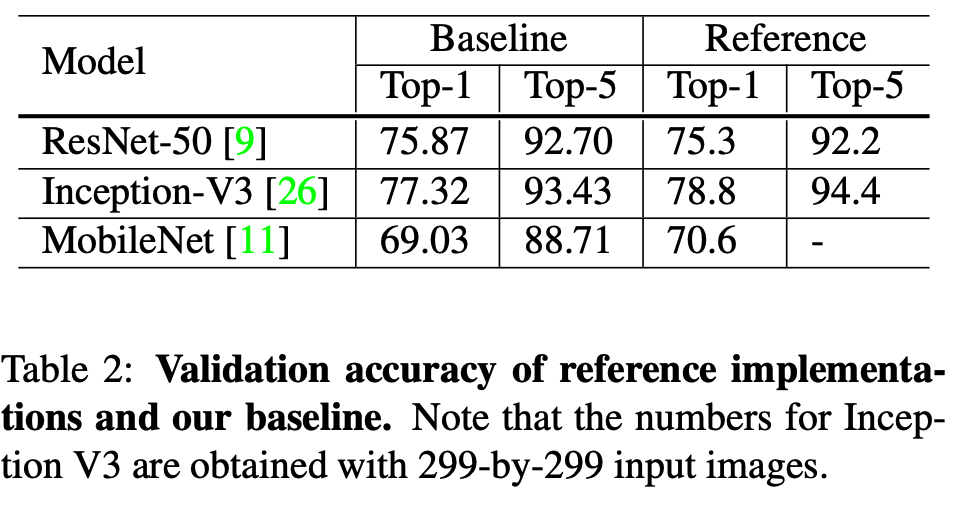
효율적인 학습 방법
- GPU 가 도입되면서 GPU 환경에 영향을 받는 기법들이 등장하고 있음.
- 더 낮은 정밀도를 가진 수치 연산 방법들
- 큰 배치 사이즈를 지원 등등.
- 여기서는 이와 관련된 몇가지 기법을 살펴본다.
큰 배치 사이즈를 이용한 학습
- Mini-batch SGD 는 여러개의 샘플을 묶어 업데이트하는 방식.
- 병렬화를 증가시키고 연산 비용을 감소시키는 효과가 있다.
- convex 문제에서는 배치 크기가 클수록 수렴 속도가 감소한다.
- 이건 신경망에서도 경험적으로 동일하다는 것이 알려져있다.
- 이 말은 동일한 epoch을 가지는 데이터를 학습할 때 더 큰 배치 크기를 사용하는 경우 validation 정확도가 작은 배치를 사용한 데이터보다 더 떨어진다는 의미이다.
- (물론 정해진 범위의 동일한 epoch 값 내에서의 비교이고 최종 품질은 알 수 없다.)
- 하지만 여러 기법들을 통해 이런 문제들을 해결한다.
Linear scaling learning rate
- 미니배치 SGD 에서 GD는 각 배치별로 랜덤하게 선택된 샘플로 업데이트되게 된다.
- 배치 크기를 키우더라도 각 미니배치들의 GD 값의 평균은 크게 달라지는 것은 없다.
- 다만 이에 대한 분산값은 배치 크기가 클 경우 줄어들게 된다.
- 이 말은 배치 크기를 키워야만 노이즈를 더 줄일수 있다는 의미가 된다.
- 결국 노이즈가 줄어든만큼의 안정성을 바탕으로 \(lr\) 을 더 크게 잡을 수 있다. (학습 속도가 빨라진다.)
- 예를 들어 Resnet-50 에서는 배치 크기가 256일때 \(lr\) 을 \(0.1\) 로 사용하고 더 큰 배치를 사용하는 경우 \(0.1 \times b/256\) 를 사용한다. (여기서 \(b\) 는 배치 크기)
Learning rate warmup
- 학습 초반에는 모든 파라미터라 랜덤 값으로 초기화된 상태이다.
- 그래서 실제 최종 결과값 과는 아주 먼 실수 값으로 구성된다.
- 보통 너무 큰 \(lr\) 값을 사용하게 되면 수치적으로 매우 불안정한 상태에 머물게 된다.
- 이 때 사용하는 것이 warmup 기법이다. (휴리스틱 기법이다.)
- 시작시에 매우 작은 \(lr\) 로 출발해서 특정 시점까지 초기(initial) \(lr\) 값에 도달하도록 구성한다.
- 즉, weight 가 어느정도 안정화될 때 까지는 정말 작은 \(lr\) 값으로 학습을 수행한다는 것.
- 이런 방식을 사용하면 초기 학습이 안정적으로 수행된다는 것이 확인되었다.
- Goyal 이 제안한 방법으로 \(lr\) 을 0.0 에서 시작하여 초기값 \(lr\) 까지 선형으로 증가시키는 방법을 사용한다.
- 보통 5 epoch 까지 wamp-up 을 적용한다.
- \(lr = \frac{i \times \eta}{m}\) , 배치 : \(i\) (\(1 \le i \le m\) ), 초기 \(lr\) : \(\eta\)
Zero \(\gamma\)
- ResNet 은 여러 개의 residual block 을 가지고 있다.
- 입력을 \(x\) 라 하면 출력을 \(x+block(x)\) 로 정의할 수 있다.
- 마지막에는 batch-normalization (BN) 레이어를 사용한다.
- 입력값 \(x\) 에 정규화를 적용한 결과를 \(\hat{x}\) 라고 표기하고 이에 대해 \(\gamma \hat{x} + \beta\) 를 적용한다.
- 여기서 \(\gamma\) 와 \(\beta\) 는 학습되는 파라미터이다.
- 여기에 휴리스틱한 기법을 적용해서 \(gamma\) 값을 시작시 0으로 초기화한다. (\(\gamma=0\))
- 이렇게 되면 학습 초기에는 \(block(x\) 영역에서 넘어오는 값이 없고 오로지 skip connection 결과만 흘러가게 된다.
- 초기에는 망이 짧아져 학습이 빨라지는 현상이 생김.
No bias decay
- weight decay 는 보통 학습 weight, bias 에 적용된다.
- L2 정규화와 동일한 개념으로 파라미터가 0의 값에 가깝도록 제약을 둔다.
- 이 방법은 오버피팅 방지를 위해 권장된다.
- No bias decay 는 다음과 같은 경우에만 권장하는 휴리스틱한 기법이다.
- 오로지 convolution 과 FC 레이어에만 적용한다.
- BN 내의 \(\gamma\), \(\beta\) 등에는 적용하지 않는다.
Low-precision training
- 신경망은 대부분 FP32(32bit floating point type) 로 학습한다.
- 마찬가지로 저장도 모두 FP32 로 하며 모든 연산도 FP32 기준으로 구현되어 있다.
- 하지만 더 작은 크기의 데이터 타입을 사용할 경우 수치 연산 향상을 얻을 수 있다.
- 최근 Nvidia V100 의 경우 FP16 에 대한 빠른 연산을 지원한다.
- 14 TFLOPS in FP32 vs. 100 TFLOPS in FP16
- 즉, 최신의 GPU와 FP16과 함께라면 2-3배의 성능 향상을 얻을 수 있다.
- 이러한 성능적 이득에도 불구하고 FP16을 바로 사용하는 것은 어려운데 학습시 어려움이 따르기 때문이다.
- FP16 이 실수를 표현할 수 있는 범위가 작다보니 GD 과정에서 문제가 생긴다.
- Micikevicius 는 모든 작업 과정을 FP16으로만 구현한 Net 을 만들고 업데이트 순간에 이 값을 모두 FP32 로 복사한 뒤 loss 를 계산하는 모델을 만들었다.
- 학습 시간이 2-3배 빨라짐. (V100 기준)
실험 결과
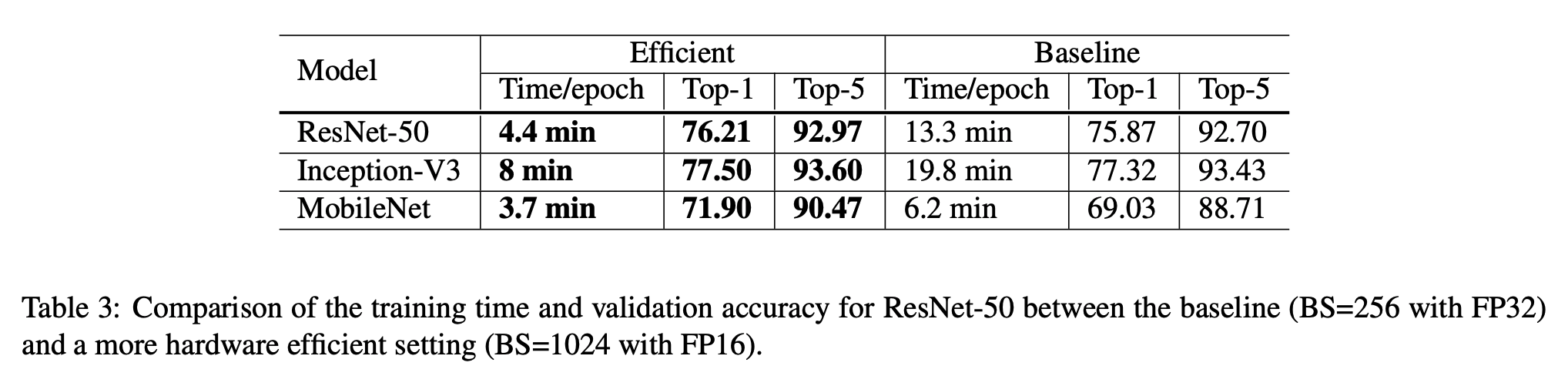
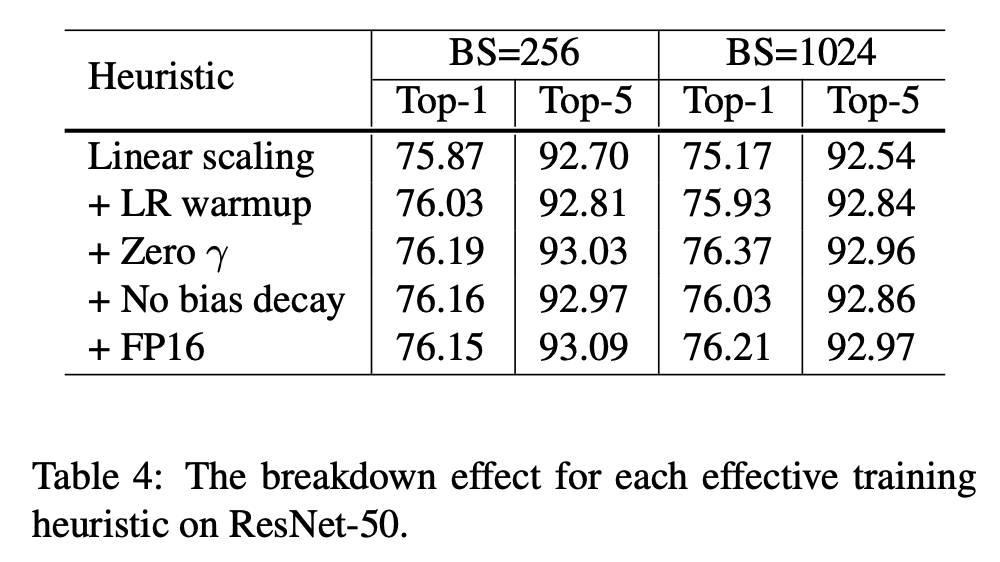
- 위의 경우에는 각각의 기법을 stacking 했을 때의 평가 결과를 의미한다.
Model Tweaks
- 모델 변경(tweak)은 convolution 레이어의 stride 등을 변경하는 작업같은 것을 의미한다.
- 모델 변경 작업은 기존 모델의 계산 복잡도를 바꾸기는 하지만 유의미한 성능 향상을 얻을 수도 있다.
- 여기서는 마찬가지로 ResNet 에 대한 모델 변경을 알아본다.
- ResNet 은 input stem 영역이 존재하고 4개의 stage 로 구성된 모듈을 지나 output 레이어로 구성된다.
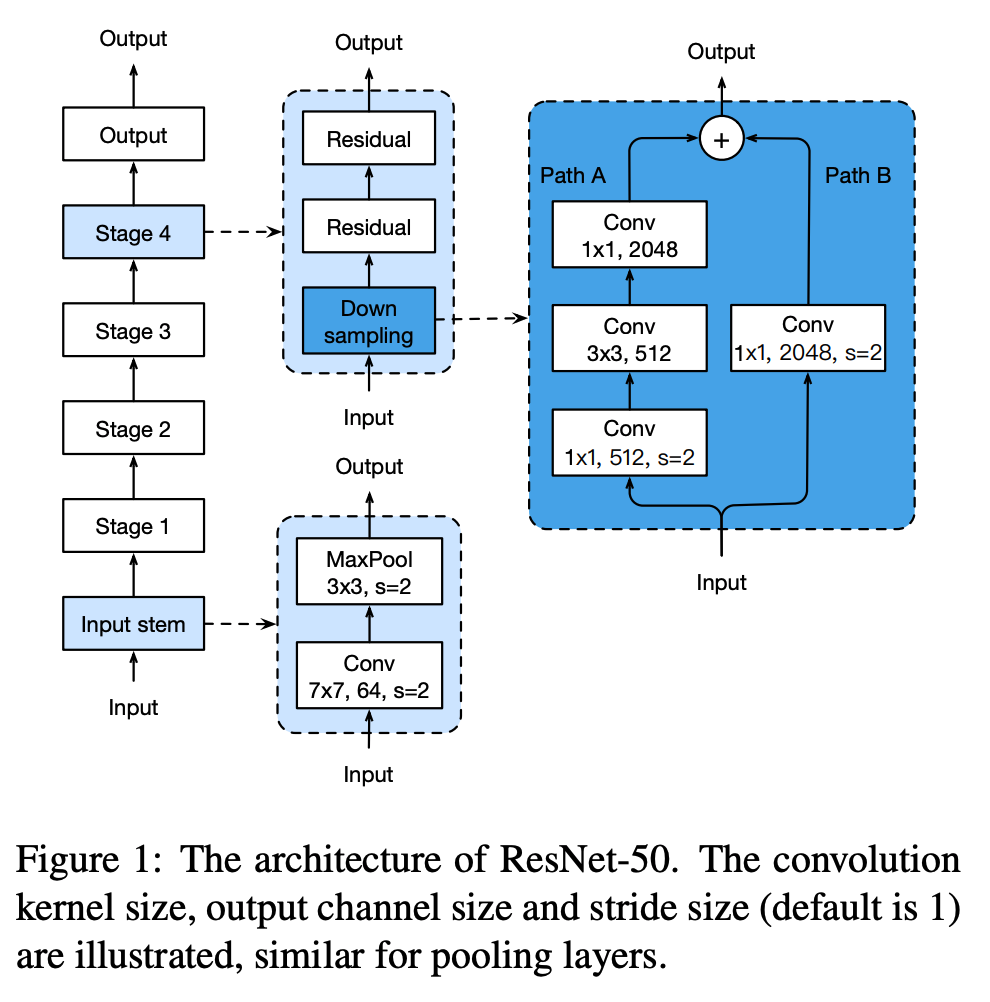
- Input stem
- \(7 \times 7\) convolution 을 사용하고 64 channel 을 출력한다. (stride는 2를 사용)
- 그 뒤로 \(3 \times 3\) max pooling 레이어가 온다. (stride는 2를 사용)
- 결국 input stem 영역에서 입력 크기를 4배 줄이는 대신 channel 크기를 64까지 키운다.
- 4 stage
- stage-2 부터 시작해서 각각의 stage 에는 downsampling block 이 있다.
- downsampling block 에는 2개의 path (각각 \(A\), \(B\)) 가 존재한다.
- \(Path\;A\) 는 3개의 convolution 으로 구성되고 각 커널의 크기는 \(1 \times 1\), \(3 \times 3\), \(1 \times 1\) 이다.
- 첫 block 에서 stride 를 2로 하여 width, height의 크기를 반으로 줄인다.
- \(Path\;B\) 는 bottleneck 이라 부른다.
ResNet Tweaks
- ResNet 에는 2개의 인기있는 변경(tweak)이 존재한다.
- 이를 각각 ResNet-B, ResNet-C 라고 부른다. (당연히 오리지널을 ResNet-A 라 하겠지)
- 그리고 이 논문에서는 ResNet-D 를 제안한다.
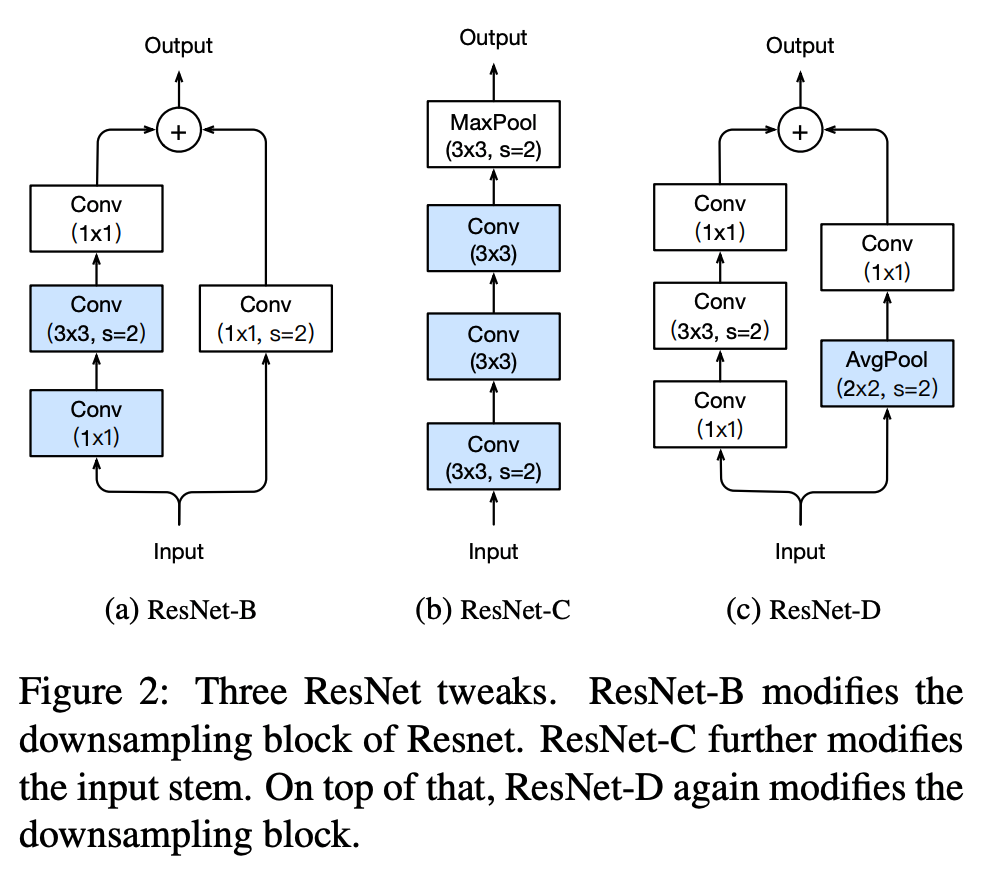
- ResNet-B
- 이 모델은 Torch 버전으로 처음 등장했다. 그리고 다양한 곳에서 ResNet 구현체로 사용되고 있다. (ex) TF official ResNet
- 이 모델은 downsampling block이 변경되었다.
- \(Path\;A\) 영역에서 정보의 손실량이 많는데 이는 stride 가 2인 \(1 \times 1\) conv 를 사용하기 때문이다.
- ResNet-B 는 첫번째와 두번째 conv의 stride 크기를 바꾸었다.
- ResNst-C
- 이 변형체는 원래 Inception-v2 에서 제안된 방법을 적용한 것이다.
- 그리고 이 방식은 이미 SENet, PSPNet, DeepLab.V3, ShuffletNet.V2 등에서 활용중이다.
- 망 맨 앞의 stem 영역의 \(7 \times 7\) conv 를 여러 개의 \(3 \times 3\) conv 로 대체하는 것이다.
- 그림 2에서(ResNet-C) 첫번째, 두번째 conv 의 출력 채널은 32이고 stride는 2를 사용한다. 최종 출력은 64채널이다.
- ResNet-D
- ResNet-B 에 영감을 받은 개선안이다
- \(Path\;B\)에 \(1 \times 1\) conv 로 인해 정보의 3/4 가 손실된다. 이를 최소화하도록 한다.
- (실험을 통해) 앞에 stride가 2인 \(2 \times 2\) avg-pooling 레이어를 추가하고 원래 conv 의 stride 는 1로 변경한다.
- 약간의 연산량만 증가하고 더 좋은 결과가 얻어지는 것이 확인되었다.
실험 결과
- 앞서 ResNet-50 에 대한 3가지 변형체를 살펴보았다.
- 여기에 먼저 설명했던 1024-batch-size 와 FP16 을 적용한 상태에서 3가지 변형체에 대한 결과를 살펴본다.
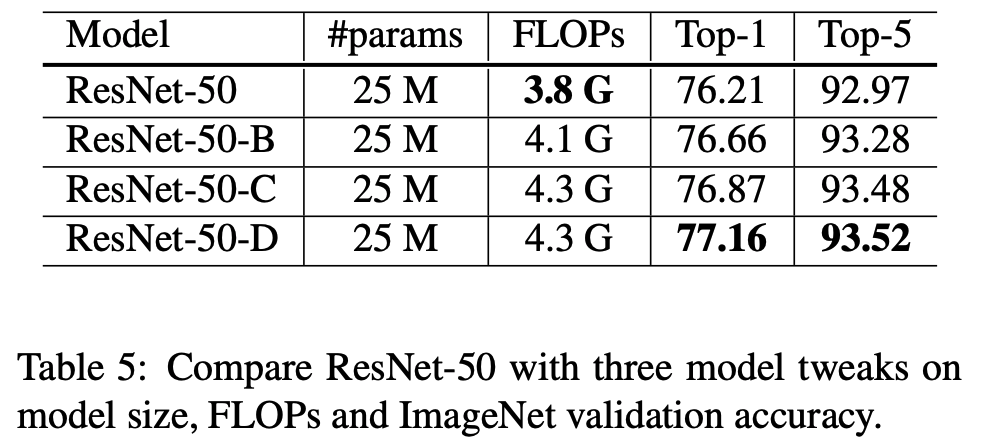
- 테이블.5를 보면 ResNet-B 모델은 downsampling block 을 개선하여 0.5% 의 성능 이득을 얻었다.
- ResNet-C는 여기에 stem 레이어에 있는 \(7 \times 7\) conv 를 3개의 \(3 \times 3\) conv 로 변환하여 0.2% 의 성능 이득을 얻었다.
- ResNet-D는 여기에 \(path\;B\) 의 downsampling block을 변경하여 0.3%의 성능 이득을 보였다.
- 최종 ResNet-D 는 ResNet-A 모델보다 약 1% 의 성능을 개선시켰다.
- ResNet-D 가 가장 연산량이 높은데 ResNet-A와는 15% 차이 이내이다.
- 실험결과 ResNet-D 가 ResNet-A 보다 약 3% 정도 느리게 학습되는 것을 확인했다.
Training Refinements
Cosine Learning Rate Decay
- lr 은 학습에 있어 가장 중요한 요소 중 하나.
- 앞서 설명한 warm-up 말고도 이 값을 초기치로부터 어떻게 감소시킬지에 따라 최종 성능이 달라지기도 한다.
- 가장 많이 쓰이는 방법은 exponetially decaying 기법이다. (He.)
- 0.1 로 시작하여 30 epoch 마다 특정 비율로 감소
- step decay 라는 것도 있는데 2 epoch 마다 0.94 비율로 감소시킨다.
- Loshchiov 는 cosine annealing 기법을 제안하였다.
- 초기치가 0인 lr 로부터 다음 cosine 함수의 결과값으로 lr 을 얻어내는 것이다.
- 전체 batch 수는 \(T\) 로 정의한다. (단, 여기서 warp-up 과정은 고려하지 않는다.)
- 임의의 batch \(t\) 에서 lr \(\eta_t\) 는 다음 식으로 계산한다.
\[\eta_t = \frac{1}{2}\left(1+\cos{\left(\frac{t\pi}{T}\right)}\right)\eta\qquad{(1)}\]
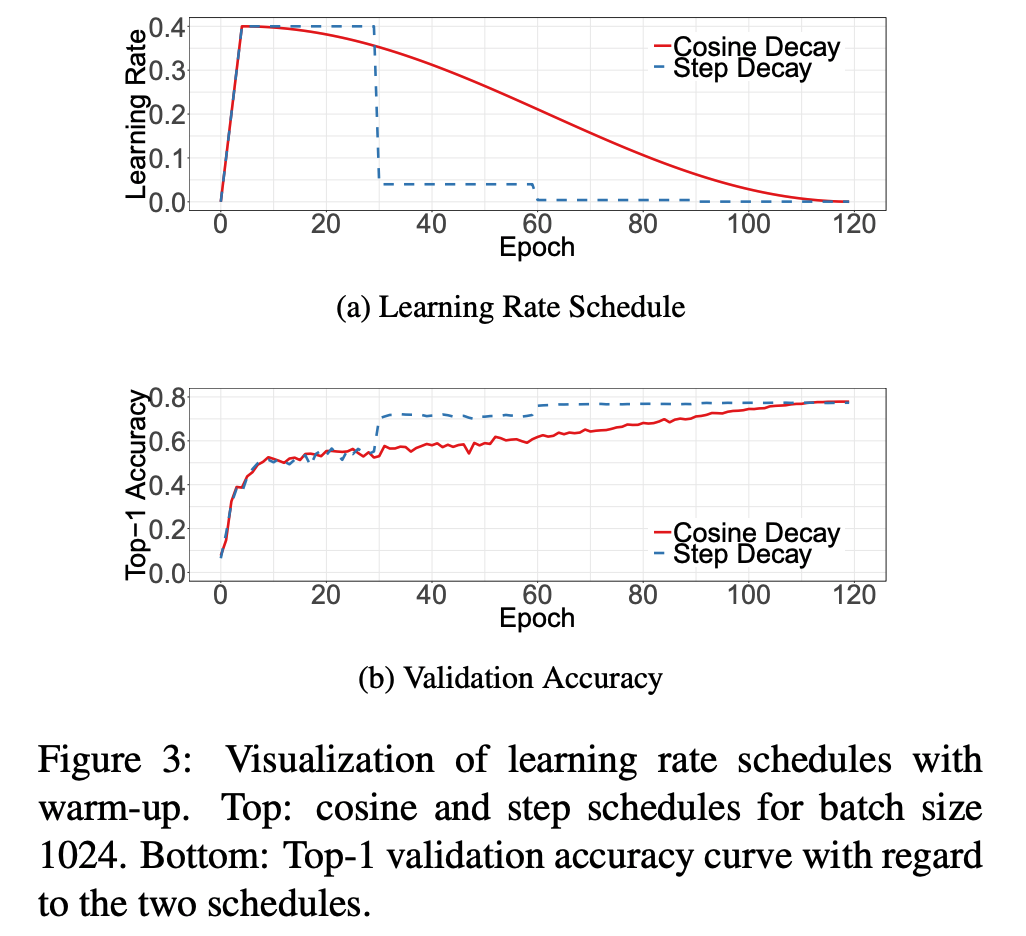
- 그림에서 알수 있듯, cosine decay 는 초기에는 lr이 매우 천천히 감소하다가 후반부에 급격하게 감소한다.
Label Smoothing
- 이미지 분류 문제에서 보통 맨 마지막 FC 레이어는 분류하고자 하는 이미지의 class 갯수와 동일하게 설정한다. (이를 \(K\)라 하자)
- 주어진 이미지가 \(z_i\) 라 할 때 어떤 클래스 \(i\) 에 속하는지 알기 위한 score 함수는 다음과 같이 정의된다.
- 이제는 누구나 알고 있는 softmax 함수를 의미한다. \(q = softmax(z)\) 로 표기한다.
\[q_i = \frac{\exp(z_i)}{\sum_{j=1}^{k}{\exp(z_j)}}\qquad{(2)}\]
- 여기서 \(q_i > 0\) 이고 \(\sum_{i=1}^{k} q_i = 1\) 을 만족한다.
- 한편 loss 함수는 negative cross entropy 를 많이 고려한다.
- 정답 레이블인 경우 \(p_i=1\) (즉, \(i=y\)), 아닌경우 \(p_i=0\) 으로 고려.
\[L(p, q) = - \sum_{i=1}^{K}{q_i \log{p_i}}\qquad{(3)}\]
- 이 둘의 분포를 비슷하게 하기 위해 (즉, 예측 분포와 정답 분포를 일치시키는 과정) 모델 업데이트 과정을 거친다.
\[L(p, q) = -\log{p_y} = - z_y + log{\left(\sum_{i=1}^{K}{\exp(z_i)}\right)}\]
- 이 때 최적의 솔루션은 \(z_y^* = \inf\) 가 되고 다른 값은 매우 작은 값이어야 한다.
- 이 말은 출력값들이 많은 차이를 내보여야 한다는 의미이고 잠재적으로 오버피팅이 될 가능성들 가지게 된다.
- Inception-V2 에서는 이 격차를 줄이기 위해 smoothing 이란 기법을 제안했다.
- 아이디어는 간단한데 정답 확률을 다음과 같이 정의한다.
\[q_i=
\begin{array}{cc}
\left\{
\begin{array}{cc}
1-\varepsilon & if\;i=y, \\
\frac{\varepsilon}{K-1} & oherwise,
\end{array}
\right.
\end{array}
\qquad{(4)}\]
- 여기서 \(\varepsilon\) 는 매우 작은 값의 상수이다.
- 이제 최적 값은 다음과 같이 쓸 수 있다.
\[z_i^*=
\begin{array}{cc}
\left\{
\begin{array}{cc}
\log{((K-1)(1-\varepsilon)/\varepsilon}) + \alpha & if\;i=y, \\
\alpha & oherwise,
\end{array}
\right.
\end{array}
\qquad{(5)}\]
- 예를 들어 \(K=1000\) 이고 \(\varepsilon=0.1\) 인 경우 \(9.1\) 정도의 값에 수렴된다.
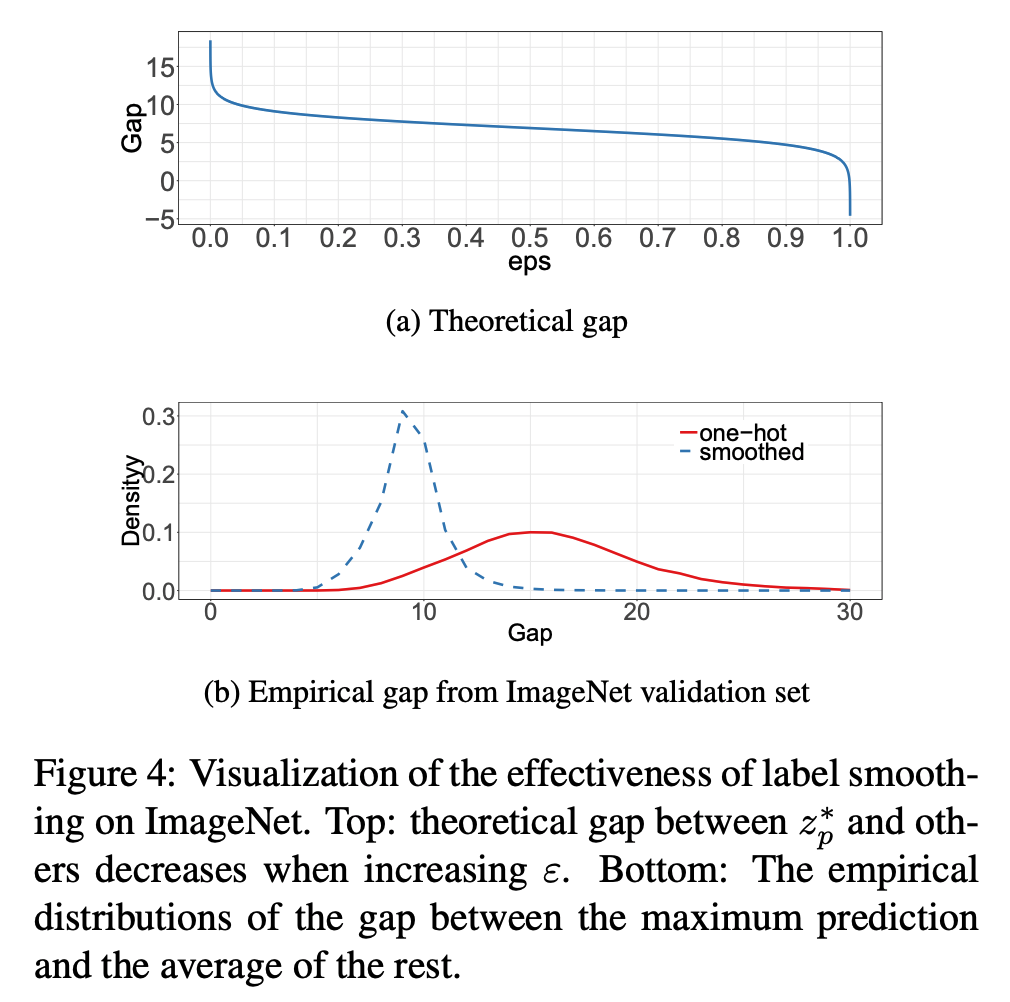
Knowledge Distillation
- “넌 학생이고, 난 선생이야” 모델.
- 먼저 학습된 모델의 결과를 새로 배울 모델에게 가르쳐주면 최종 성능이 더 올라감.
- 모델의 복잡도를 줄이는데 사용될 수 있다.
- 먼저 ResNet-152 으로 학습하고 이를 이용해서 ResNet-50을 distillation 학습.
- 학습시 distillation loss 를 추가한다. (teacher 와의 결과 차이를 줄이기 위한 loss)
- \(p\)는 정답 분포
- \(z, r\)은 각각 student와 teacher 의 FC 레이어 출력값이다.
- Loss 값은 다음과 같이 변경된다.
\[L(p, softmax(z)) + T^2L(softmax(r/T), softmax(z/T))\qquad{(6)}\]
- 여기서 \(T\) 는 temperature 를 의미하는 hyper-parameter 이다.
Mixup Training
- 앞서 학습시 이미지 전처리로 augmentation 작업을 간단히 설명했다.
- 여기서는 mixup 이라고 불리우는 이미지 augmentation 기법을 소개한다.
- 간단하게 학습에 사용되는 이미지 2개를 서로 섞는 기법이다.
- 두개의 샘플 \((x_i, y_i)\) 와 \((x_j, y_j)\) 가 있다고 하면,
\[\hat{x} = \lambda x_i + (1 - \lambda)x_j, \qquad{(7)}\]
\[\hat{y} = \lambda y_i + (1 - \lambda)y_j, \qquad{(8)}\]
- 여기서 \(\lambda \in [0, 1]\) 이고 \(Beta(\alpha, \alpha)\) 분포로부터 랜덤 추출된 상수이다.
실험 결과
- 총 4가지의 실험을 수행
- cosine lr decay 적용
- \(\varepsilon=0.1\) 을 설정한 label smoothing.
- distillation 을 위해 \(T=20\)이고 ResNet-D-152 가 teacher 인 모델.
- cosine decay, label smoothing 을 teacher 에 적용.
- mixup 모델은 \(Beta\) 분포의 파라미터 \(\alpha=0.2\) 이고 epoch를 120 에서 200으로 변경.
- mixup 모델은 더 긴 학습 시간을 요구한다. (실험)
- ResNet 모델 말고 다른 모델에도 적용을 해보았다.
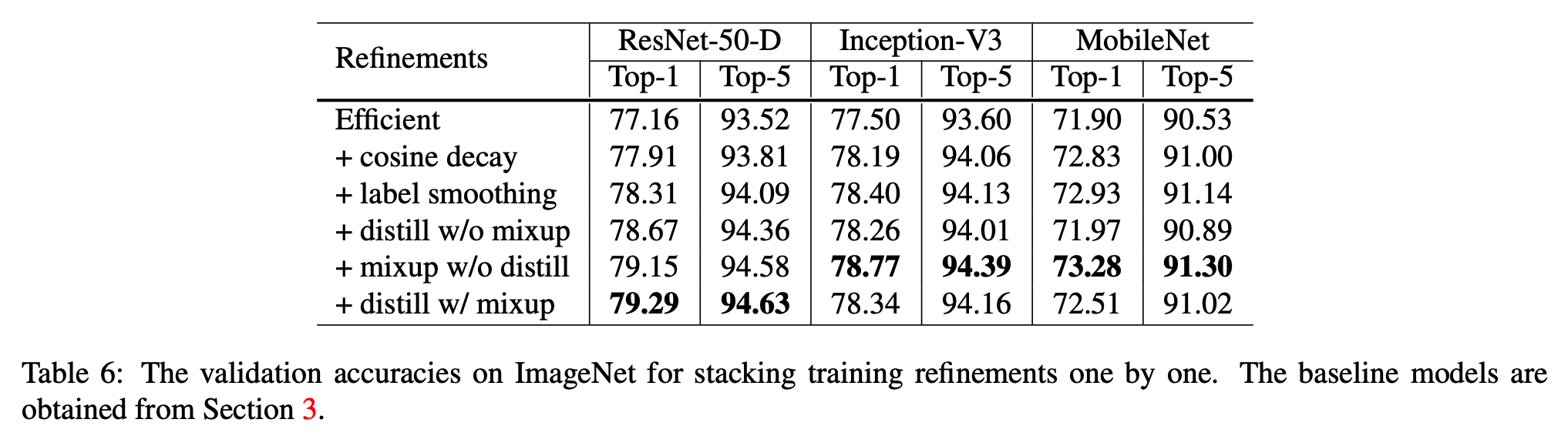
- distillation 은 ResNet 에서는 잘 동작했으나 다른 모델에는 잘 맞지 않는 것 같다.
- 다른 데이터 집합에도 어떠한지 비교해보았다.
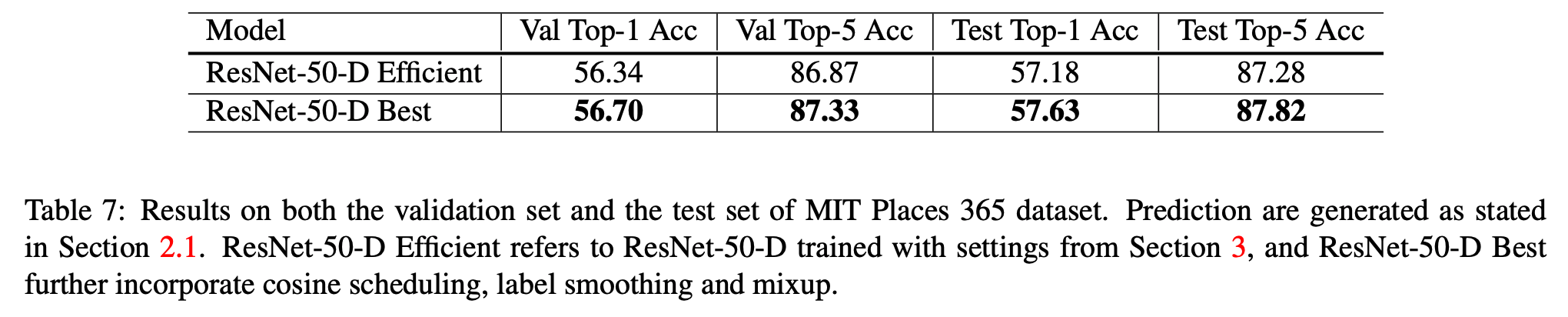
Transfer Learning
- transfer learning 은 대표적인 분류 모델 학습 방법이다.
- 여기서는 지금까지 살펴본 내용들이 transfer learning 에도 적용이 가능한지 살펴본다.
- 특별히 vision 문제에서 주요하게 다루고 있는 Object Detection과 Semantic Segmantation 문제를 다루어보자.
Object Detection
- object detection의 최종 목적은 이미지에 존재하는 object의 bbox 를 찾는 것.
- 여기서는 Pascal VOC 데이터를 가지고 실험을 진행한다.
- VOC 2007 과 2012 데이터를 합쳐 사용한다. (대표적인 object detection set이다.)
- Faster-RCNN 을 보도록 하자.
- 앞서 설명했던 Net 을 backbone 으로 삼아 새로 학습을 해본다.
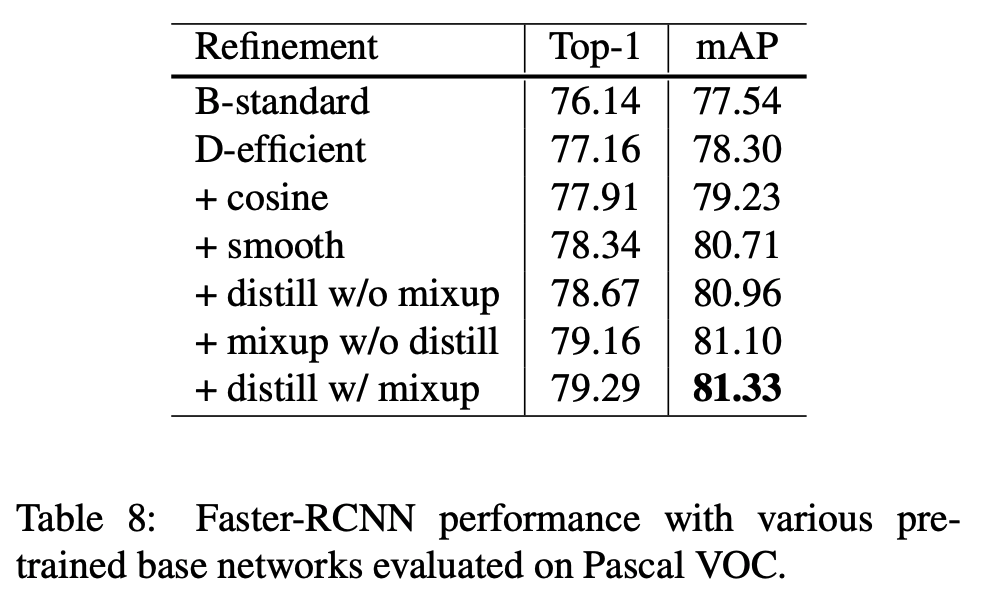
Semantic Segmentation
- semantic segmentation 문제는 픽셀 단위의 분류문제로 입력 이미지의 픽셀 레벨 클래스를 분류한다.
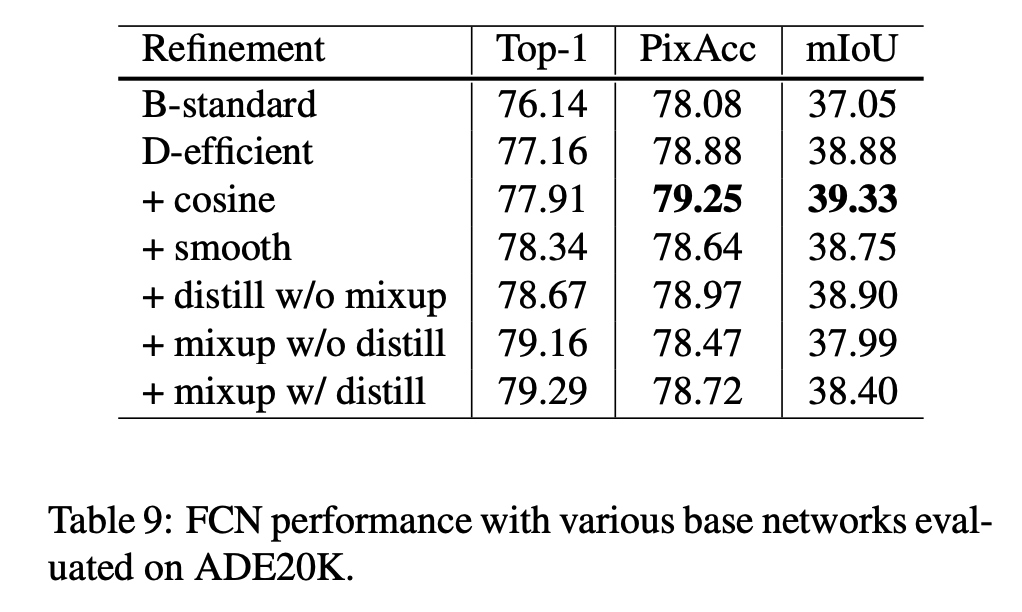
- FCN 을 모델과 ADE20K 데이터셋으로 결과를 확인해본다.
- 좀 더 자세한 내용은 논문을 참고하자.
Conclusion
- 여러 trick 을 설명했는데 적용해보니 좋았더라. 끗.