DropBlock: A regularization method for convolution networks
Introduction
- 딥러닝은 매우 많은 수의 파라미터를 가지고 있고 weight decay 와 dropout 같은 regularization 기법을 사용한다.
- 그 중 dropout 은 CNN에서 가장 먼저 성공한 기법 중 하나이다.
- 하지만 최근 CNN구조에서는 dropout 을 거의 사용하고 있지 않다.
- 사용한다고 해도 맨 마지막 FC 레이어 정도에서만 사용한다.
- 우리는 dropout 의 약점이 랜덤하게 feature 를 drop 하는데 있는것이 아닐까 논의했다.
- 구조상 FC에는 적당히 영향을 주게 되지만 conv 연산에는 크게 도움이 되지 않는다.
- conv 에서는 drop을 시켜도 다음 레이어로 정보가 전달된다.
- 그 결과 network가 overfit 된다.
- 이 논문에서는 DropBlock 기법을 제안한다.
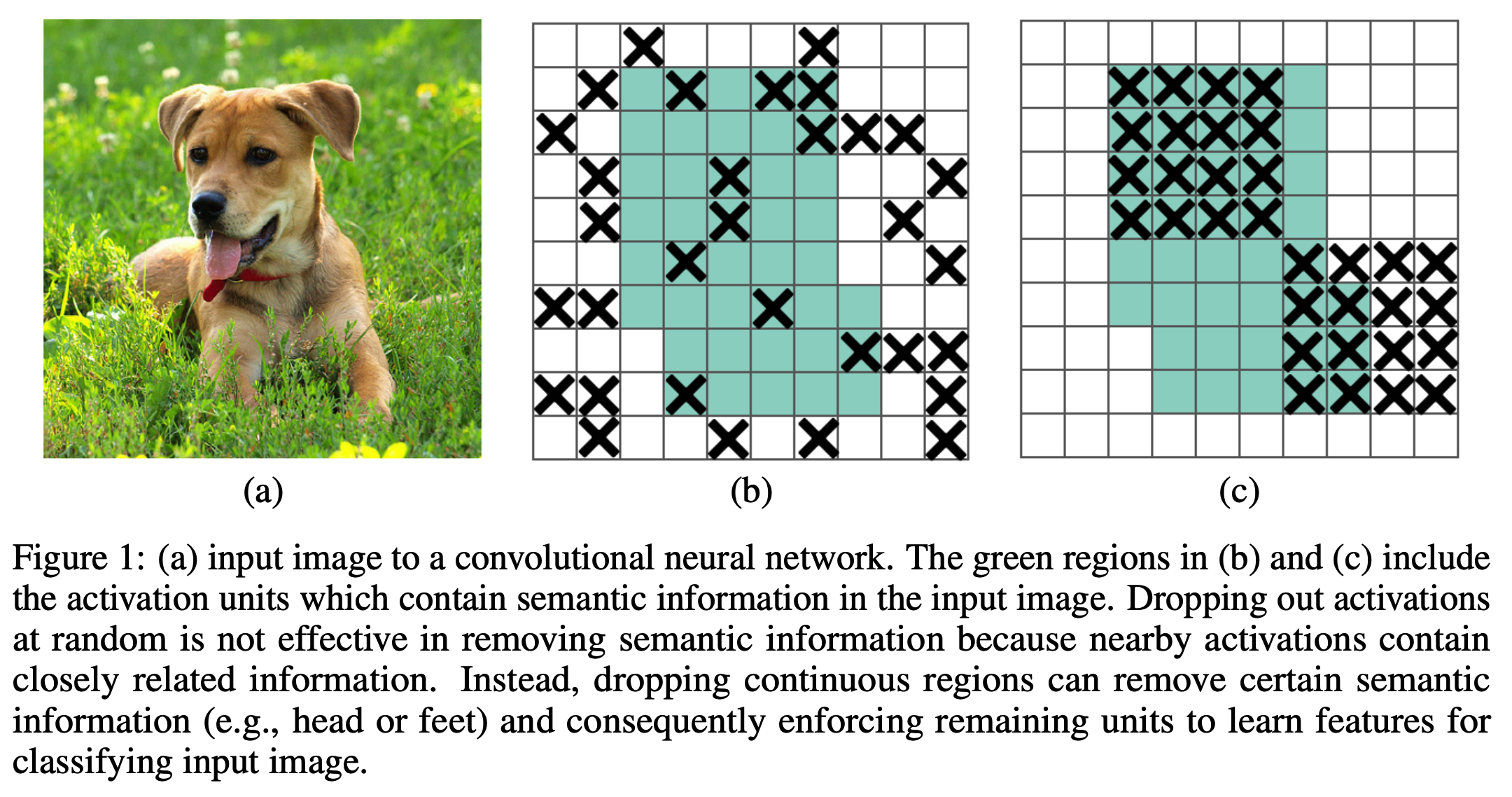
DropBlock
- DropBlock 은 dropout 과 유사한 아주 간단한 기법이다.
- dropout 과의 차이점은 독립적으로 랜덤하게 drop 하는 것이 아니라 feature 의 일정 범위를 함께 drop하는 것이다.
- DropBlock 은 주요한 2개의 파라미터로 구성된다.
- \(block\_size\) : drop 할 block 의 크기
- \(\gamma\) : 얼마나 많은 activation unit 을 drop할지 비율
- 실제 구현 방법은 알고리즘.1 에 서술되어 있다.

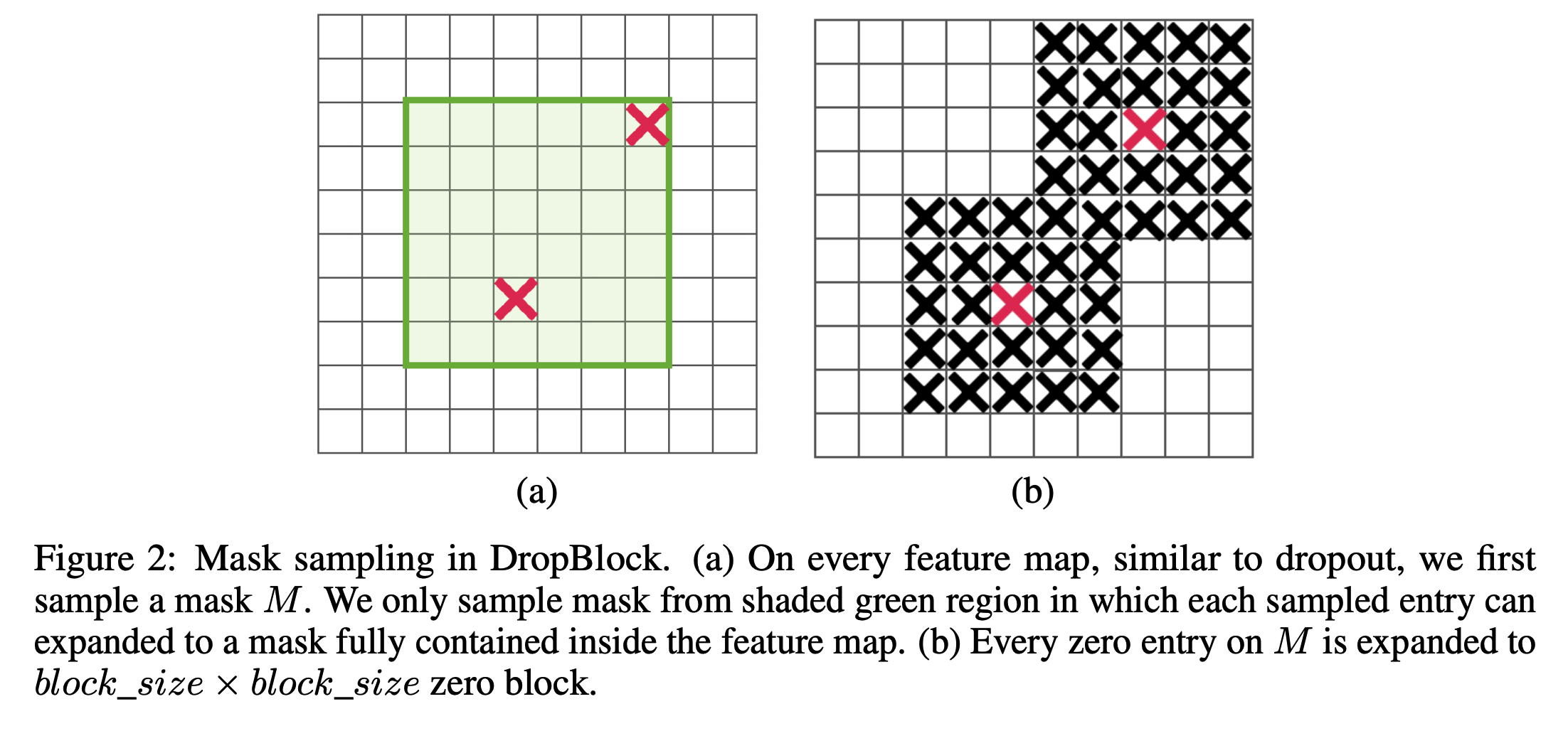
- dropout 과 유사하게 \(Inference\) 시에는 DropBlock 기능을 사용하지 않는다.
- 이는 평가시 여러 작은 net 을 앙상블하여 평균값을 취하는 것과 마찬가지의 효과를 가진다.
- \(block\_size\) 할당하기
- 구현에서는 \(block\_size\) 에 고정된 상수 값을 적용한다.
- 레이어의 feature map 크기에 상관없이 모두 동일값 사용.
- 만약 \(block\_size=1\) 을 사용하면 SpatialDropout 과 동일해진다.
- \(\gamma\) 할당하기
- 경험에 의거하여 \(\gamma\)에 명시적인 값을 설정하지 않는다.
- 초반에는 \(\gamma\)가 drop 하기 위한 feature 의 갯수를 조절하게 된다.
- 모든 activation utit 에 대해 이 값들을 유지할 확률을 \(keep\_prob\) 라고 하자.
- 만약 drobout 이였다면 (\(1-keep\_prob\)) 확률을 가지고 베르누이 분포를 이용하여 이진(binary) 마스크(mask)를 만들었을 것이다.
- 하지만 DropBlock 에서는 0의 값으로 mask 되어야 할 영역이 \(block\_size^2\) 크기만큼 되도록 하기 위해 다음 식을 사용한다.
\[\gamma = \frac{1-keep\_prob}{block\_size^2}\frac{feat\_size^2}{(feat\_size-block\_size+1)^2}\qquad{(1)}\]
- 여기서 \(keep\_prob\) 는 dropout 에서 사용했던 파라미터와 동일한 역할이다.
- \(feature\_size\) 는 feature map 의 크기를 의미한다.
- (참고) 여기서는 height, width 가 동일한 경우에 대한 식을 기술하였는데 둘을 구분지어 식에 적용 가능하다.
- DropBlock 에서는 drop되는 block 들이 겹칠수 있기 때문에 위에서 사용한 식은 계산을 위한 근사식이라 생각해도 된다.
- 실험에서는 \(keep\_prob\) 를 \(0.75\) 와 \(0.95\) 사이의 값을 사용하였다.
Scheduled DropBlock
- 실험 결과 고정된 \(keep\_prob\) 를 사용하는 경우 품질이 좋지 않음을 확인하였다.
- 매우 작은 값을 설정하는 경우 초반에 학습이 잘 되지 않는다.
- 대신 \(1.0\) 에서 시작하여 값을 줄여가면 성능 향상을 할 수 있다.
- 이 실험에서는 linear 한 방식으로 값을 감소시키는 방법을 사용하였다.
실험
- 이미지 분류 문제와 시멘틱 세그먼트 문제로 DropBlock 을 적용해보고 성능을 확인해본다.
- 분류 문제에서는 ResNet-50 을 사용하여 실험하였다.
- 그리고 다른 모델에서도 동일한 품질을 얻을 수 있는지 확인하기 위해 SOTA 모델에도 적용해보았다.
- AmoebaNet(분류)와 RetinaNet(시멘틱 세그먼트)에 적용하여 더 좋은 성능을 보임을 확인하였다.
이미지넷 분류문제
- ILSVRC2012 분류 문제는 120만개의 학습(train) 데이터와 50,000개의 평가(validation) 데이터, 150,000개의 테스트(test) 데이터가 존재한다.
- 그리고 1,000개의 레이블을 가지고 있다.
- 학습시 이미지 전처리 과정으로 좌우-플립, 스케일, aspect-ratio augmentation 등을 적용하였다.
- 평가시 single-crop 을 사용하였드며 평가 집합의 accuracy 를 측정한다.
구현 상세
- TPU를 사용
- TensorFlow official 코드를 사용. (ResNet-50, AmoebaNet)
- batch-size 는 ResNet 은 1,024 사용. AmoebaNet는 2,048을 사용
- 이미지 크기는 ResNet 은 \(224 \times 224\), AmoebaNet 은 \(331 \times 331\) 사용.
- 그 외 기본적인 파라미터 설정 값을 사용함.
- \(lr\) 은 125, 200, 250 epoch 마다 0.1 배씩 감소시켰다.
- AmoebaNet 은 340 epoch 까지 학습하였다. (exponential decay 사용)
- Baseline 모델의 경우 너무 오래 학습 시키면 학습 끝에서는 validation 의 accuracy 가 더 낮게 나오기도 한다.
- 이 경우 가장 높은 accuracy 를 가지는 순간의 값을 지표로 사용한다. (공정한 비교를 위해)
ResNet-50 에 DropBlock 적용
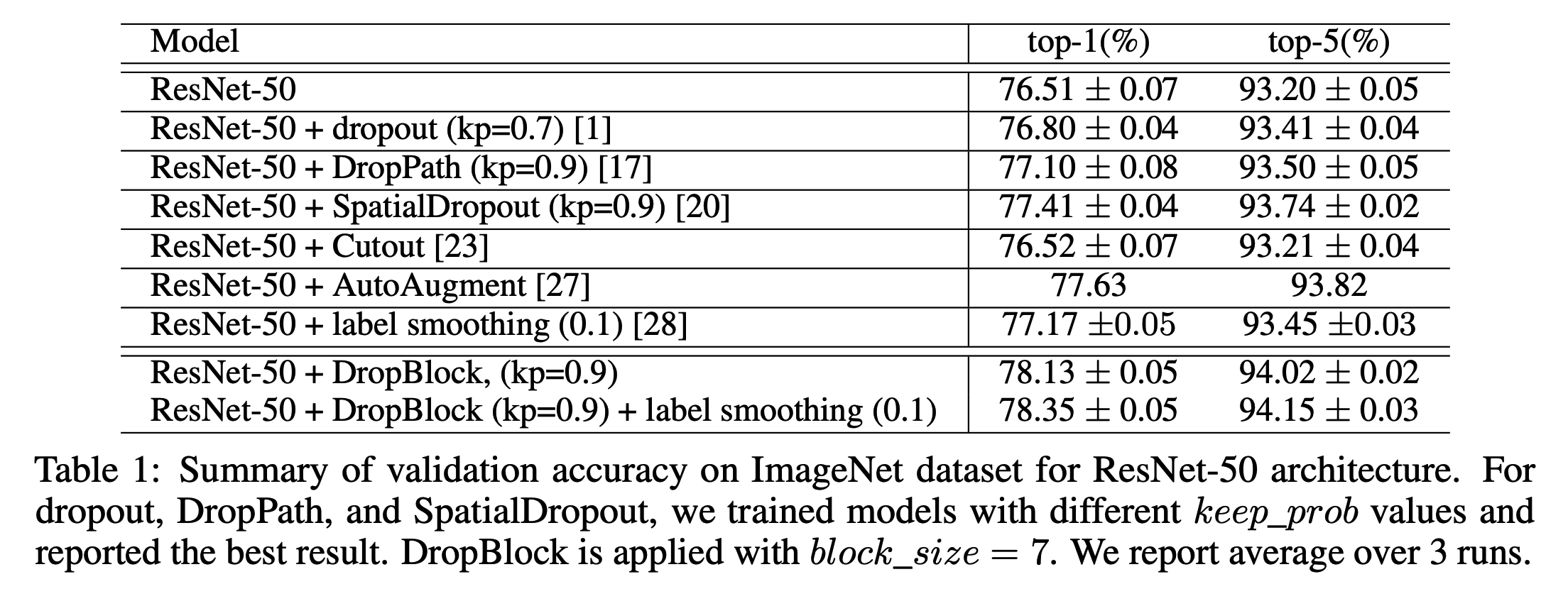
어디에 DropBlock 을 적용하는가?
- 먼저 ResNet 구조를 보자.
- 블록(block)
- ResNet 에서 하나의 블록(block)에는 여러개의 conv 레이어가 사용된다. (보통 3개) : 보통 Path-A라 한다.
- 이와는 다른 path 로 skip connection 영역이 있다. : 보통 Path-B라 한다.
- 그리고 모든 conv 레이어에는 batch-norm 과 ReLU가 적용된다.
- 이후 conv 브랜치와 skip 브랜치를 concat 하게 된다.
- 그리고 이러한 블록(block)을 여러 개 묶은 모듈이 있다.
- 이 논문에서는 이를 group 이라고 하는데 다른 논문에서는 stage 라고도 한다.
- ResNet 망의 깊이에 따라 하나의 group에 포함된 block 갯수가 다르다.
- ResNet은 망의 깊이에 상관없이 4개의 group(stage) 로 나눈다.
- 망이 깊을수록 하나의 group 에 속한 block 갯수가 많다.
- resolution 작업은 group 을 거치는 단계에서 발생한다.
- 맨 마지막 group에 적용을 하는 DropBlock 을 DropBlock Group-4 라 한다.
- 이 말은 각 group 에 적용되는 DropBlock 을 Group-X 라고 생각하면 된다는 이야기이다.
- 논문에서는 Group-3와 Group-4 만 사용한다.
- DropBlock은 residual block과 skip-conn. 이후에 적용한다.
- residual 의 경우 conv2d 뒤에 적용한다.
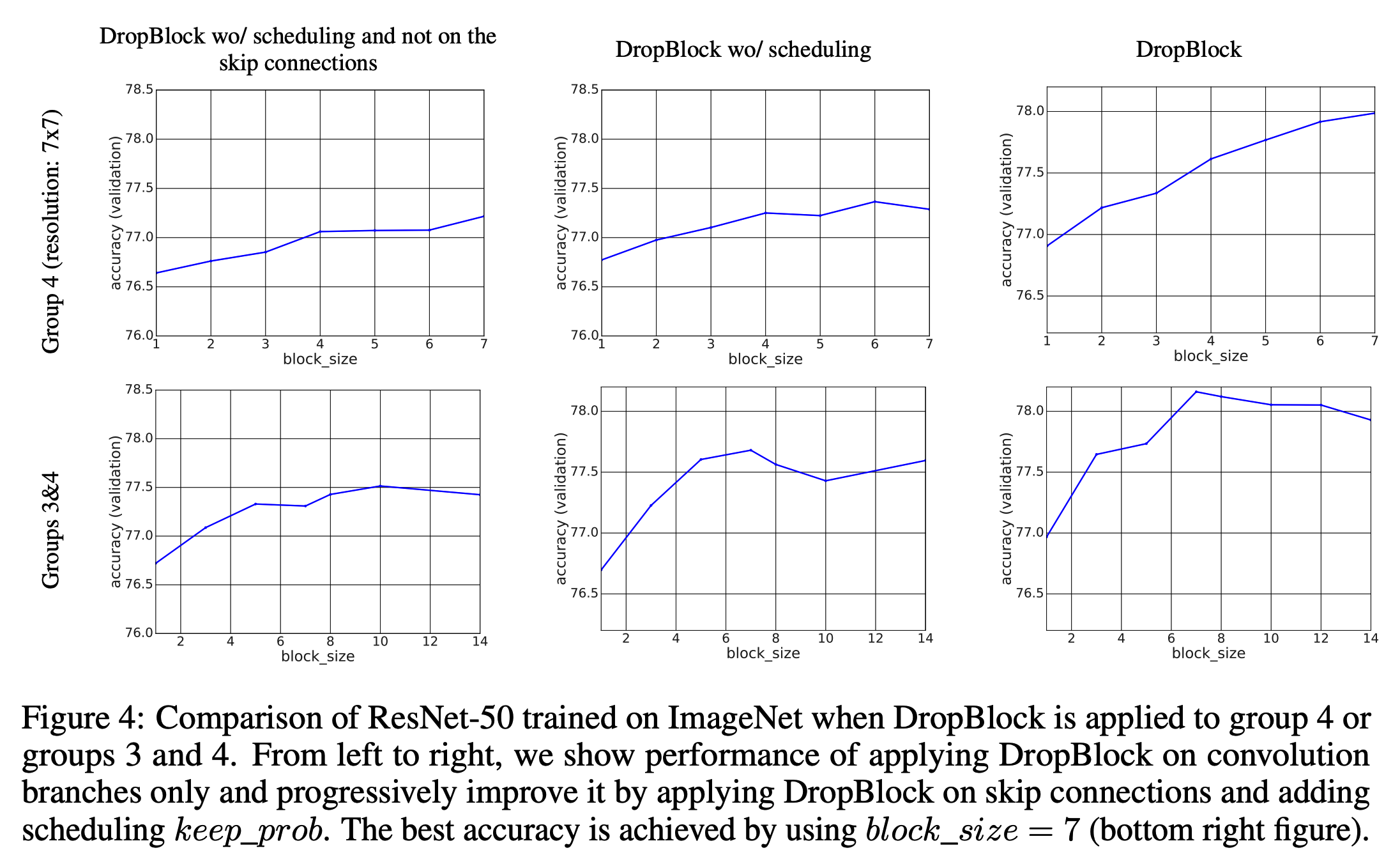
- 실험에서는 Group-4만 사용하는 경우와 Group-3 과 Group-4 를 함께 사용하는 것을 실험하였다.
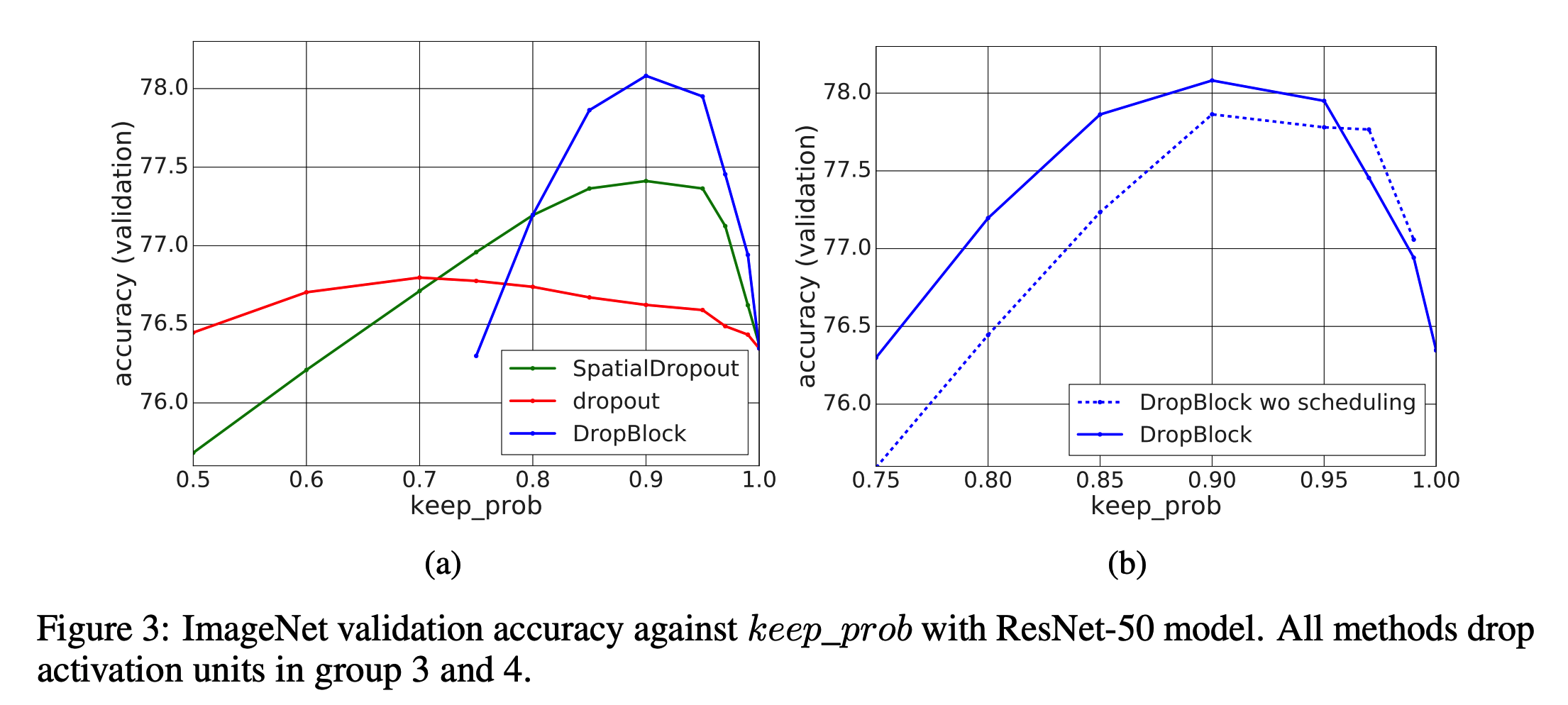
DropBlock vs. dropout
- 원래의 ResNet 에서는 droupout 를 사용하지 않는다.
- 실험을 비교해보기 위해 BaseLine 이 되는 ResNet 에 droupout 을 적용해 보았다.
- DropBlock 에서는 Group-3과 Group-4 모두 \(block\_size=7\) 을 적용하였다.
- \(\gamma\) 값의 경우 Group-3 을 1/4 로 축소시켜 사용하였다.
- 그림.3(a) 를 보면 DropBlock 이 dropout 보다 top-accuracy가 1.3% 높은 것을 알 수 있다.
- scheduled \(keep\_prob\)는 그림.3(b) 를 보자.
- 그림.3을 보면 최적의 \(keep\_prob\)를 알아낼 수 있다.
- 그림.4는 여러 \(block\_size\) 에 대해 실험한 결과이다. 최종적으로 \(block\_size=7\)을 사용한다. (Group-3 & Group-4 사용)
- 전체 실험에 걸쳐 DropBlock 과 dropout 는 비슷한 경향성을 가진다.
- 그리고 상대적으로 DropBlock 의 효과가 더 좋으므로 dropout 보다 더 효과적임을 유추할 수 있다.
DropBlock in AmoebaNet
- DropBlock 을 AmoebaNet-B 에 적용해본다.
- dropout 의 경우 base 모델에 FC 레이어에만 적용한다.
- 후반부 50% 영역의 batch-norm 과 skip-conn. 이후에 DropBlock 을 적용한다.
- 입력 이미지의 크기는 \(331 \times 331\) 이다.

실험 분석
- DropBlock 은 dropout 에 비해 좋은 성능을 낸다.
- 이는 conv 연산이 인접한 지역의 정보들고 강한 상관관계를 맺고 있으므로 랜덤하게 몇 개의 위치를 drop 하더라도 해당 정보가 유지되어 전달되기 때문이 아닐까 생각한다.
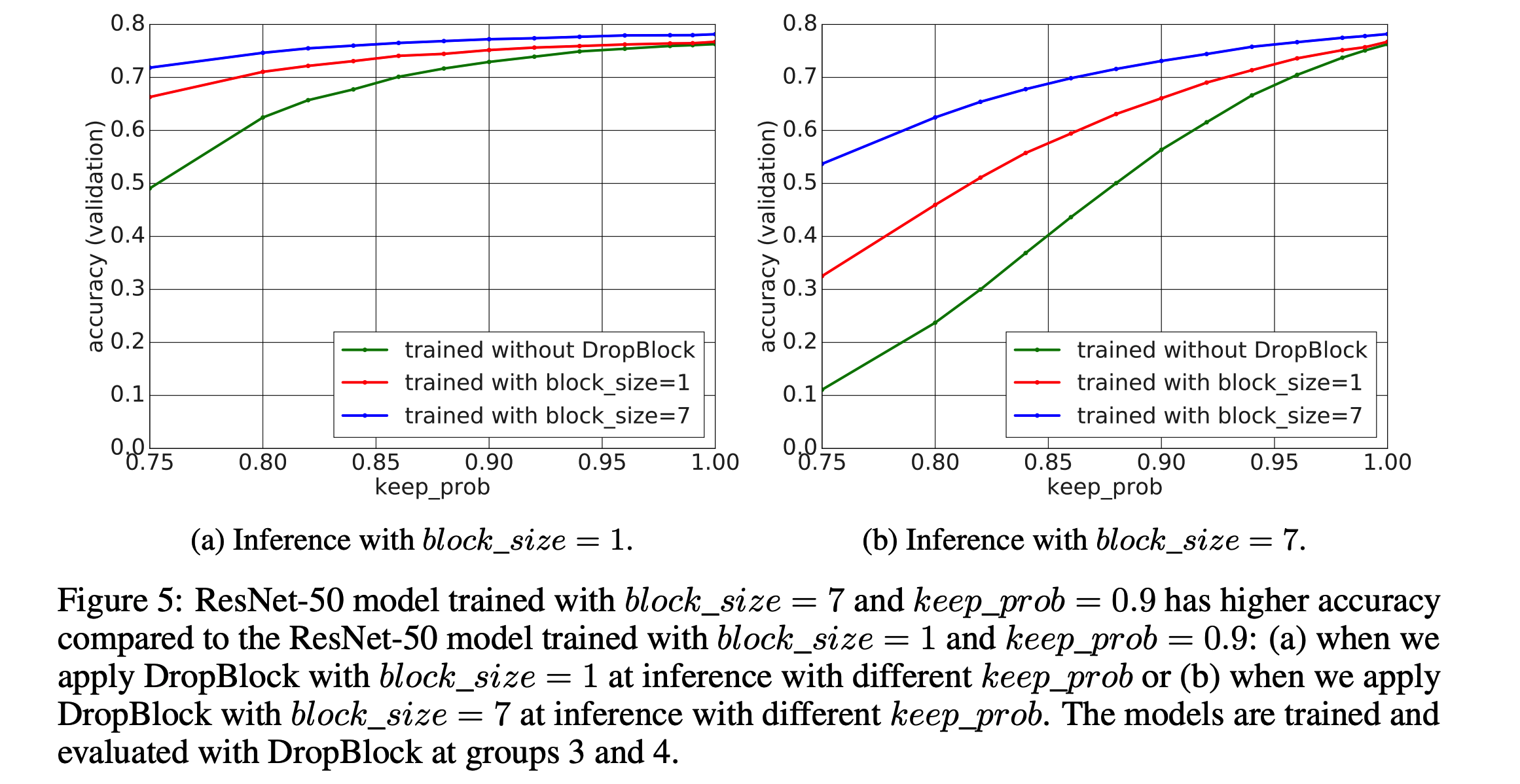
- 우리는 별도의 regularization 을 사용하지 않고 오로지 DropBlock 만을 적용한 상태로 테스트를 진행해보았다.
- 위 그림에서 녹색 선은 \(keep\_prob\) 가 감소함에 따라 성능이 급격히 감소하는 것을 알 수 있다.
- 이 말은 DropBlock 이 적용되면 semantic information 이 급격하게 감소된다는 의미가 된다.
- 이러한 정보 손실로 분류 성능이 급격하게 떨어지게 된다.
- 왼쪽 그림에서 \(keep\_prob\) 이 감소될 때 \(block\_size=1\) 보다 \(block\_size=7)이 더 급격하게 성능이 감소한다.
- 이 말은 DropBlock 이 dropout 보다 semantic information 을 더 많이 제거한다는 의미이다.
- 다음으로, 더 큰 \(block\_size\) 로 학습한 모델이 좀 더 일반화가 잘 되어있다는 것을 알고 있다.
- 학습은 \(block\_size=7\) 로 하고 평가시엔 \(block\_size=1\) 로 평가한 모델과,
- 그 반대의 경우로 평가한 모델을 살펴보자.
- 그림을 보면 알수있듣 \(block\_size=7\) 로 학습한 모델이 더 강건하다.
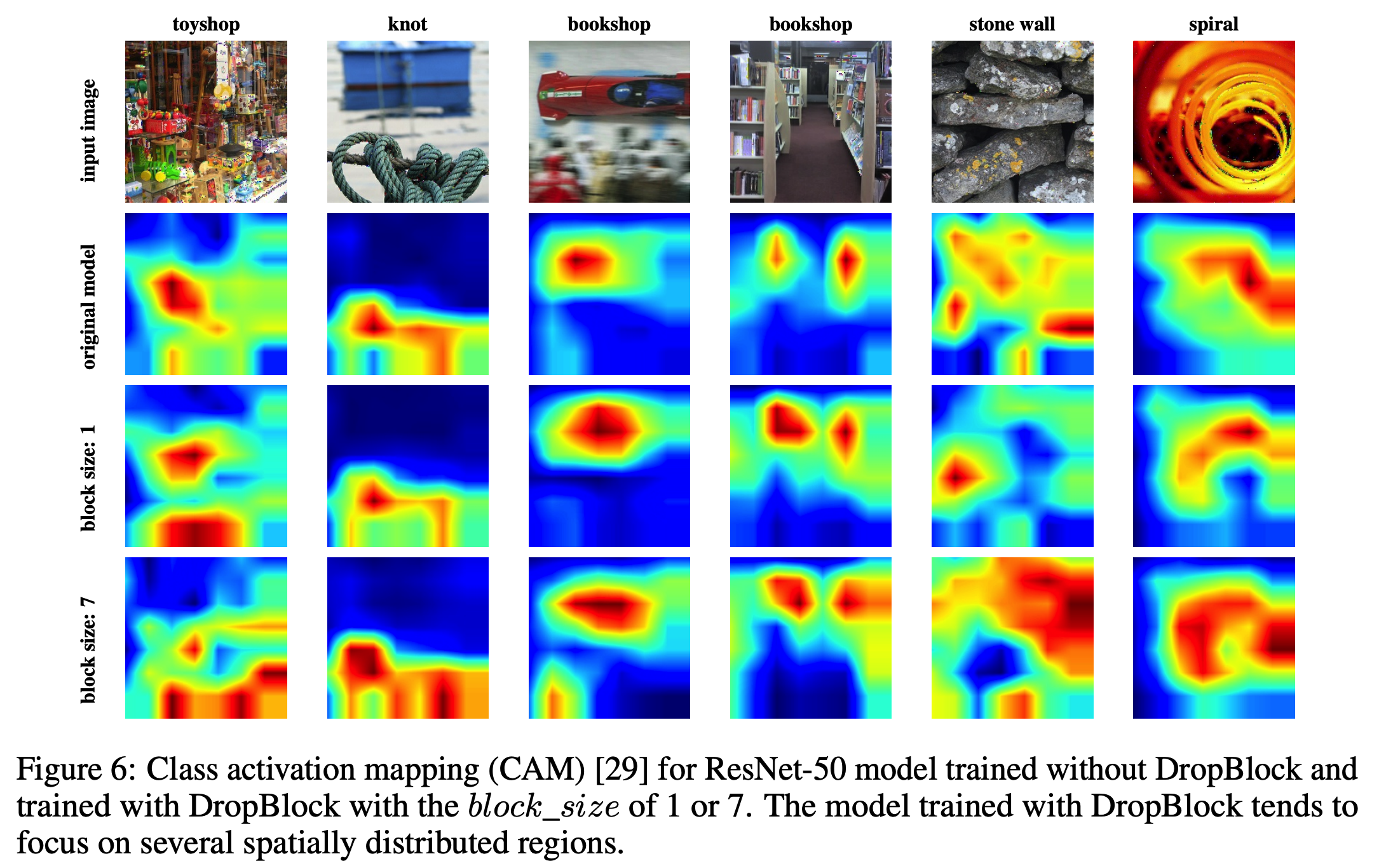
- 실제 어떤 영역이 활성화되는지 살펴보기 위해 CAM 을 수행한다. (class activation map)
conv5_3 영역을 활성화시켜 보았다.
Object Detection & Sementic segmantation
- 여기서는 관련 내용을 생락한다.
- 다만 DropBlock 을 적용한 모델이 더 좋다더라… 정도만 알고 있으면 된다.