- Deep Learning 계에서 ResNet 은 정말 성공적인 모델임. (인용수가 무려 14,000이 넘는다.)
- 이 모델을 통해 더 많은 Layer를 쌓을수록 더 좋은 성능을 낸다는 사실을 알게 되었다.
- 이 논문은 Resnet Block에 대해 좀 더 심층적으로 살펴보도록 한다.
Introduction
- CNN 의 Conv. 레이어 수는 지속적으로 증가하기 시작했다.
- Alex, VGG, Inception, ResNet 의 단계를 거쳤다.
- 동시에 이미지 인식 task의 성능 향상도 이루어졌다.
- 하지만 망이 깊어지면서 학습도 점점 어려워졌다.
- 이를 해결하기 위해 다양한 기법들이 제시되었다.
- 초기화 전략, 다양한 Optimizer, skip-connection, knowledge transfer, layer-wise 학습
- 이를 해결하기 위해 다양한 기법들이 제시되었다.
- 최근에는 activation 을 residual block 의 어느 위치에 두느냐에 따라 학습에 효과가 달라지는 것도 확인하였다.
- ResNet 이전에 나온 아키텍처인 Highway Network 가 있다.
- ResNet과 Highway Net. 의 차이는 residual link 마지막에 gate 를 두고 이를 학습을 하는가 하는 것이다.
- 위의 경우로 보자면 ResNet 과 관련된 연구는 2가지 정도로 진행되었다고 볼 수 있다.
- block 내 activation 위치
- 망의 깊이. (depth)
Width vs. Depth
- 신경망의 깊이 문제는 오래전부터 연구되오던 주제.
- ResNet 을 설계한 연구자들은 최대한 weight 를 적게 사용하면서도 깊은 망을 사용할 수 있도록 연구.
- bottleneck block도 block 에서 사용되는 weight 를 줄여 학습을 용이하게 하여 더 깊은 망을 구성할 수 있도록 연구한 것.
- 하지만 Identity mapping 을 허용하는 residual block 은 학습시 약점이 되기도 함.
- gradient flow 과정 중에 residual block 으로 gradient 를 반드시 전달하지 않아도 되는 구조라서 실제 training 과정 중에 학습이 잘 안될 수 있다.
- 따라서 일부 block 만이 유용한 정보들을 학습하게 된다.
- 결국 대부분의 block 이 정보를 가지고 있지 못하거나 많은 block 들에 아주 적은 정보만 담긴채 공유되게 된다.
- 이 문제는 이미 Highway Network 에서 다루어졌다.
- 저자들은 이 문제를 해결하기 위해 residual block 을 무작위로 비 활성화하는 방법을 취했다.
- 이 방법은 dropout 의 특별한 예로 볼 수 있으며 dropout 이 적용되는 영역의 redidual block에 identity scala weight 가 적용된다.
- 이 논문에서는 망의 깊이를 증가시키는 것보다 residual block 을 개선하여 성능을 향상시킬 수 있는지 살펴보았다.
- 즉, 더 넓은 residual block 을 사용함으로서 성능이 향상되는 것을 확인하였다.
Dropout 적용하기.
- Dropout 은 한때 인기있는 기법이었으나 batch norm. 등장 이후 사용 빈도가 많이 줄었다.
- Dropout 을 사용하면 regularization 효과가 생겨 성능이 증가한다는 사실을 이미 잘 알려진 사실이다.
- WRN의 경우 더 넓은 redidual block 을 사용하게 되므로 parameter 의 수가 증가하게 된다.
- Dropout 이 overfitting 을 막아주게 되므로 여기에 이를 적용해본다.
- 이전 연구에 따르면 dropout 을 identity 영역에 적용하면 성능이 더 하락한다는 결과가 있다.
- 우리는 대신 이를 convolution layer 에 적용한다.
- 실험결과 더 좋은 성능을 확인하였다. (SVHN 데이터를 활용하여 1.64% 에러율을 달성.)
요약 (contiribution)
- Residual 구조에 대해 자세한 실험을 수행하여 이를 확인함.
- 새로운 widened resnet 을 제안함. (성능 향상을 확인함.)
- Residual 에 dropout 을 적용하는 새로운 방법을 제시함.
- 제안된 network 가 SOTA 임을 보임.
Wide residual networks
- 기본적인 residual block 은 다음과 같다.
- \(x_{l+1}\) 과 \(x_{l}\) 은 입력 노드이고 \(l\) 번째 unit 을 의미한다.
- \(F\) 는 residual function 이다. (이 때의 파라미터는 \(W_{l}\)) 이다.
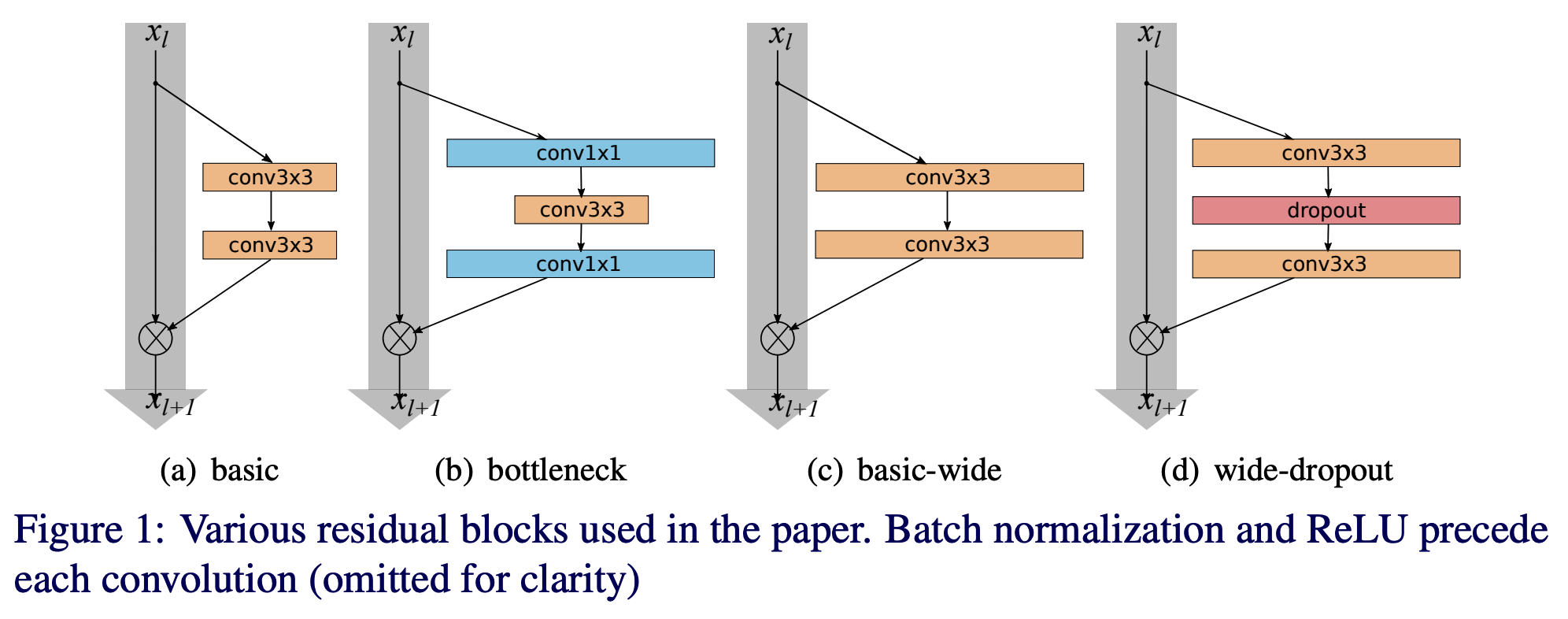
- residual block 는 2 종류이다.
- basic : \([conv 3 \times 3] - [conv 3 \times 3]\)
- bottleneck : \([conv 1 \times 1] - [conv 3 \times 3] - [conv 1 \times 1]\)
- Original Resnet 과 다르게 우리는 BN, ReLU 적용 순서를 다르게 하였다.
- origin : \(conv - BN - ReLU\)
- our : \(BN-ReLU-conv\)
- 이렇게 하면 더 빠르게 학습이 되고 더 좋은 결과를 얻는 것을 알 수 있다. (origin 따윈 무시하자.)
- Residual block 을 강건(?)하게 만들 수 있는 가장 쉬운 방법은 무엇일까?
- block 마다 conv-layer 를 추가한다.
- 더 넓은 conv layer 를 만들기 위해 출력 feature 크기를 키운다.
- filter 크기를 늘린다.
- 작은 filter 를 쓰는 것이 여러모로 좋다는 사실은 이미 잘 알려진 사실이다. (그래서 이를 늘리기는 부담이다.)
- 따라서 우리는 \(3 \times 3\) 이상 크기를 가지는 filter 를 사용하는 것을 포기한다.
Residual block 표기
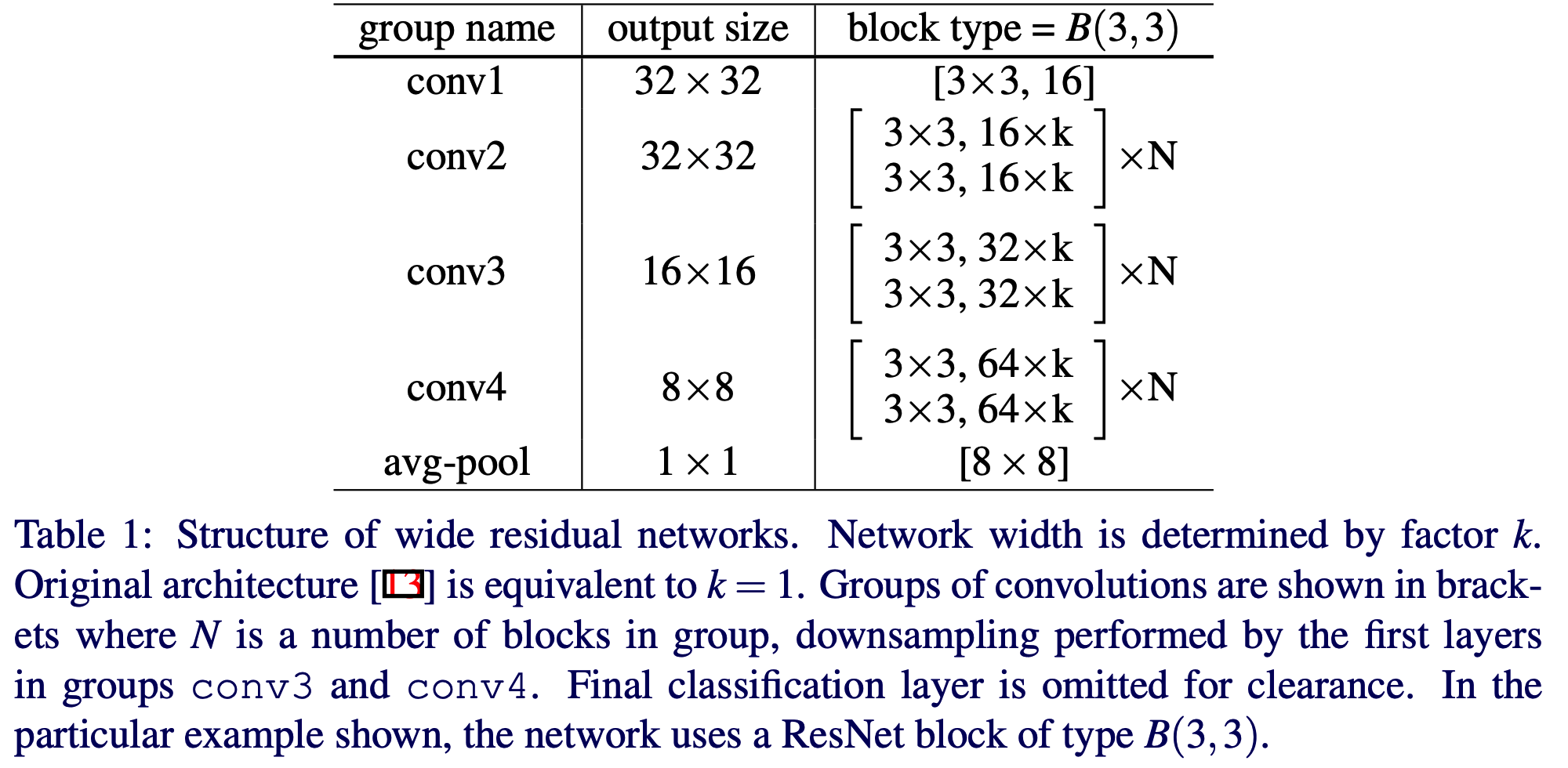
- WRN 에서는 기존 ResNet에 2개의 추가적인 factor 가 존재한다.
- \(l\) : block 에 포함된 conv 갯수
- \(k\) : conv 레이어 내에서 feature 수의 배수.
- 예를 들어 \(l=2, k=1\) 은 «basic» block 을 의미하게 된다.
- 다음으로 residual block 을 표현하는 방법은 다음과 같다.
- \(M\) 은 kernel 크기로 예를 들어 \(3\) 인 경우 \(3 \times 3\) 을 나타낸다.
- \(B(3, 3)\) - origial «
> block - \(B(3, 1, 3\) - with one extra \(1 \times 1\) layer
- \(B(1, 3, 1\) - with the same dim. of all conv. «stgaightened» bottlenect
- \(B(1, 3)\) - the newtork has alternating \(1 \times 1\) - \(3 \times 3\)
- \(B(3, 1)\) - similar idea to the previous block
- \(B(3, 1, 1)\) - NiN style block
- \(B(3, 3)\) - origial «
- 논문 내에서 망의 표기 방식
- \(WRN-28-2-B(3,3)\)
- 28 depth, \(k-2\), \(3 \times 3\) conv 2개
Experimental results
- 실험 데이터 : CIFAR-10, CIFAR-100, SVHN, ImageNet
- 이 중 CIFAR-10,100 은 입력 이미지가 \(32 \times 32\) 이고 클래스가 각각 10, 100 개
- Data augmentation
- 간단하게 horizontal flip 과 4 pixel 정도 padding 뒤 ranodm crop 적용
- 과하게 augmentation 을 적용하지 않음.
- Data augmentation
- SVHN 은 구글 스트리트 뷰 데이터
- 이미지 전처리를 사용하지 않음.
- 다만 입력 pixel 을 255 로 나누어 \([0-1\) 정규화 수행
- ImageNet 은 실험을 해보니 앞단에 activation 을 두는 모델의 장점이 전혀 없어서 그냥 original resnet 모델을 사용
- 좀 더 자세한 사항은 논문을 참고
Type of convolutions in a block
- 가장 먼저 CIFAR-10 데이터를 이용해서 여러 종류의 block 타입을 확인해봄.
- 최대한 비슷한 크기의 param 을 사용해서 결과를 얻도록 실험함.
- residual block 을 바꾸어가면 실험 (\(k=2\)를 유지.)
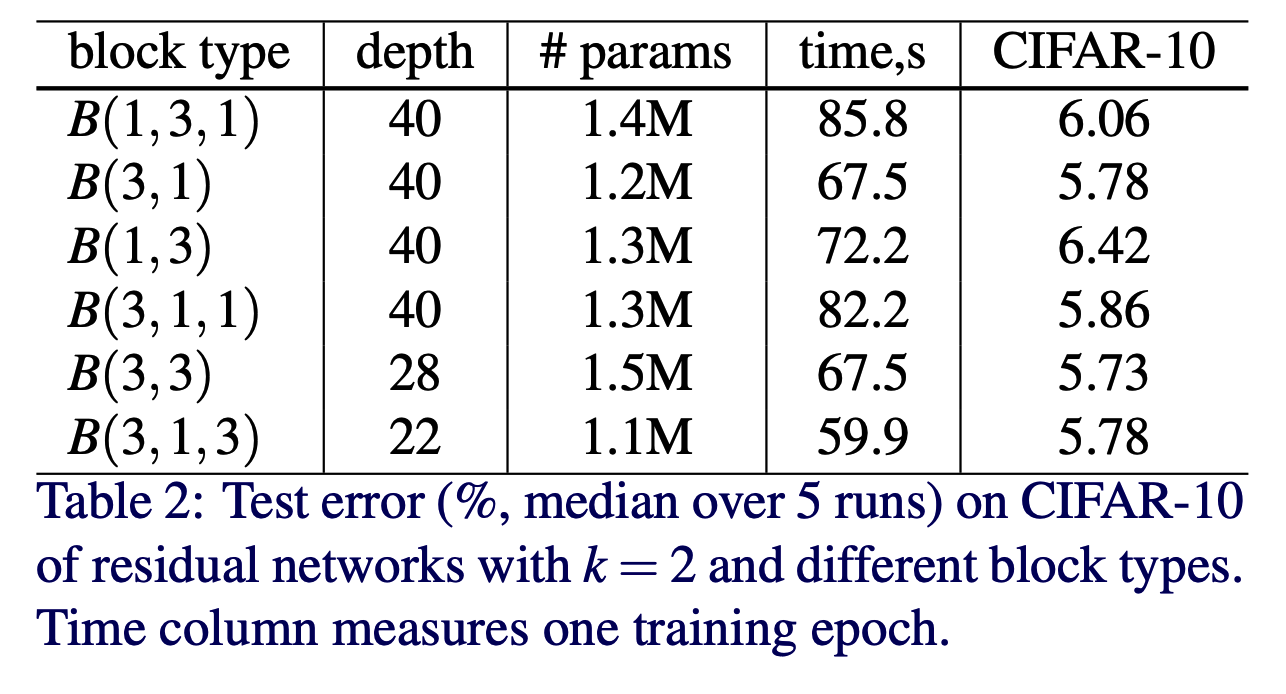
- \(B(3,3)\) 이 가증 우수하지만 파라미터 수 대비 \(B(3,1)\) 과 \(B(3,1,3)\) 도 나쁘지 않다.
- 사실 성능상 큰 차이는 없으므로 이후 실험은 \(B(3,3)\) 만을 가지고 실험.
Number of convolutions per block
- block 내에 conv. layer 갯수는 몇 개가 적당한가?

- 이 때 총 depth 는 유지. (\(depth=40\))
- \(l=2\) 인 경우 성능이 가장 좋았다. 이후 실험에서는 \(l=2\) 로 고정한다.
Width of residual blocks
- 폭(width), 깊이(depth), 파라미터 수(# of param) 실험
- WRN 의 다양한 형태를 실험함.
- \(k\) 는 2~12 로, \(depth\) 는 16~40 실험
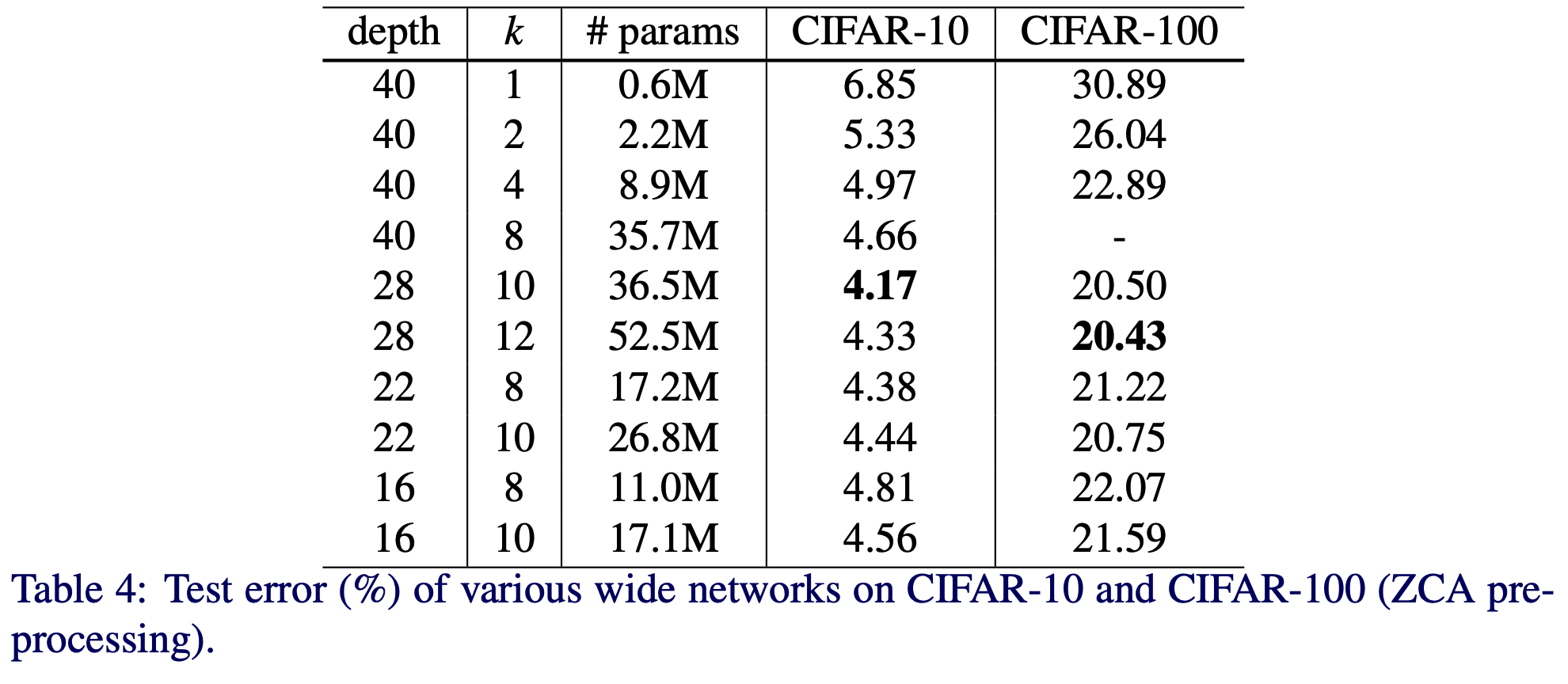
- 동일한 \(depth\) 에서는 \(k\) 가 클수록 우수
- 동일한 \(k\) 에서는 \(depth\) 가 클수록 우수
-
동일한 파라미터 수에는? \(depth\) 와 \(k\) 가 제각각. 고민이 필요하다.
- 이제 다른 Network 들과 비교해보자.
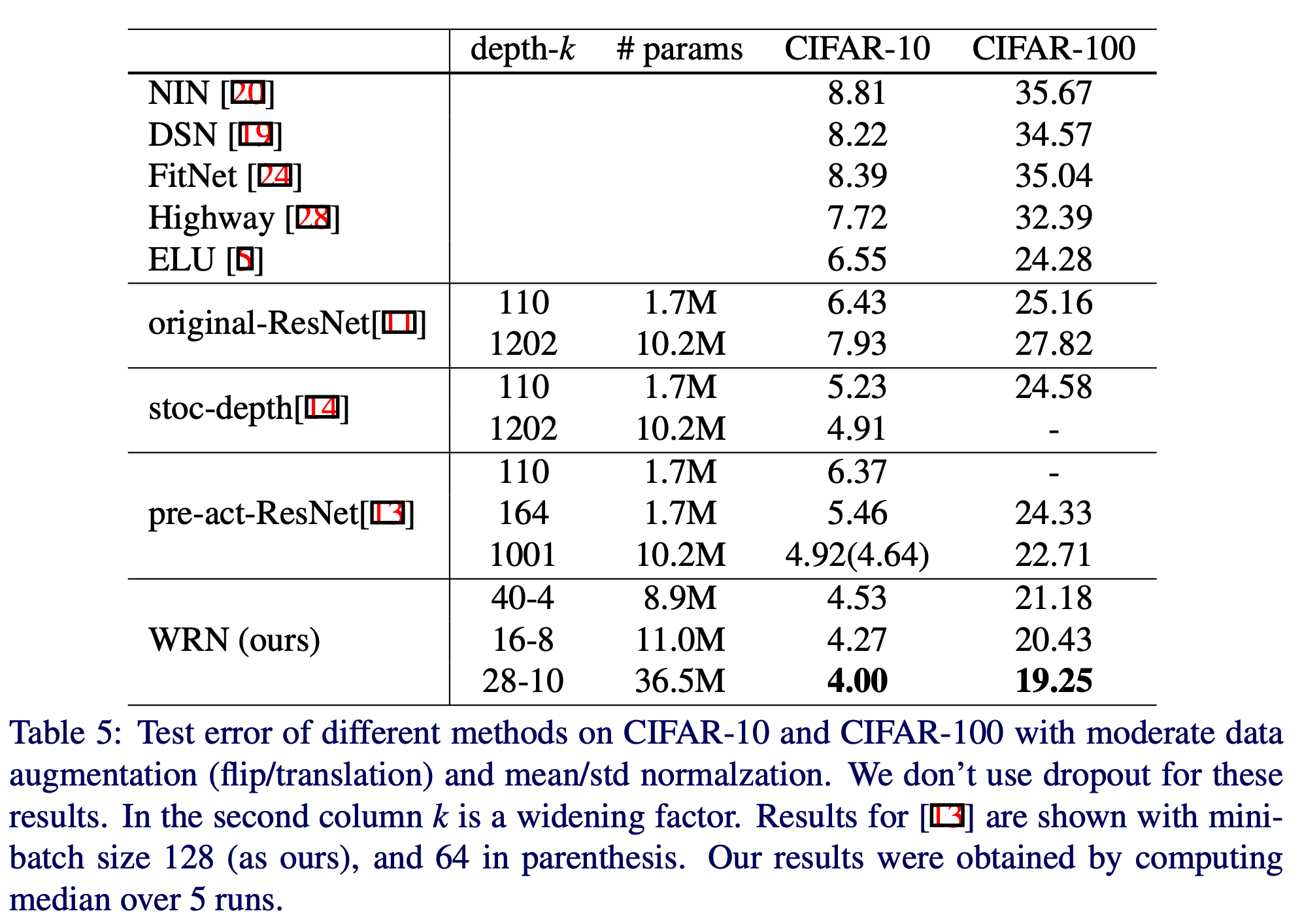
- WRN-28-10 모델이 pre-act-ResNet-1001 보다 0.92% 만큼 성능이 더 좋다. (동일한 batch size 128 로 학습)
- 참고로 batch 크기를 64 로 했을 때 pre-act-ResNet 의 error 는 4.64. (괄호 안 수치)
- 표를 보면 사용되는 파라미터의 수가 WRN 이 훨씬 많은데 어쨌거나 더 학습이 잘 된다는 주장.
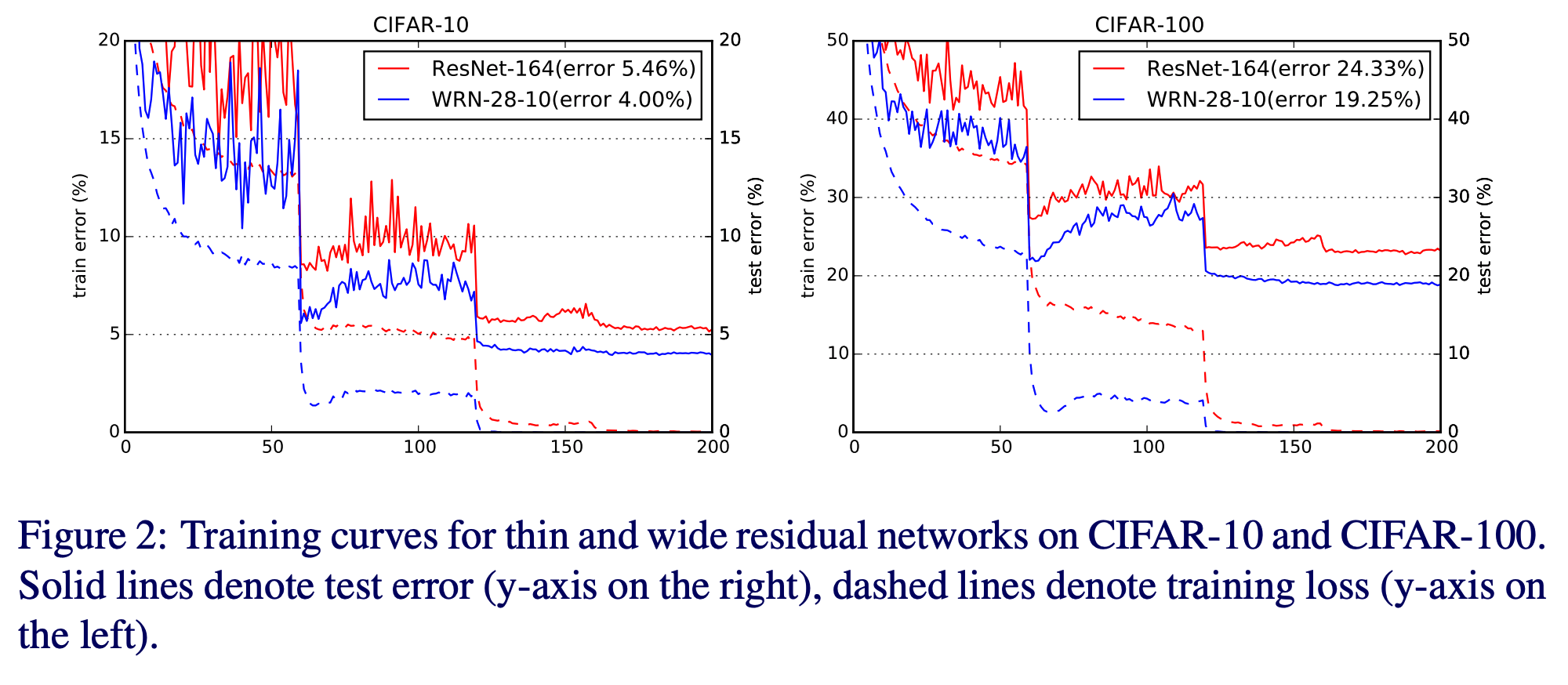
- 뭐, 그림만 보자면 파라미터가 더 많은 WRN-28-10 이 Resnet-164 보다 학습이 잘 됨.
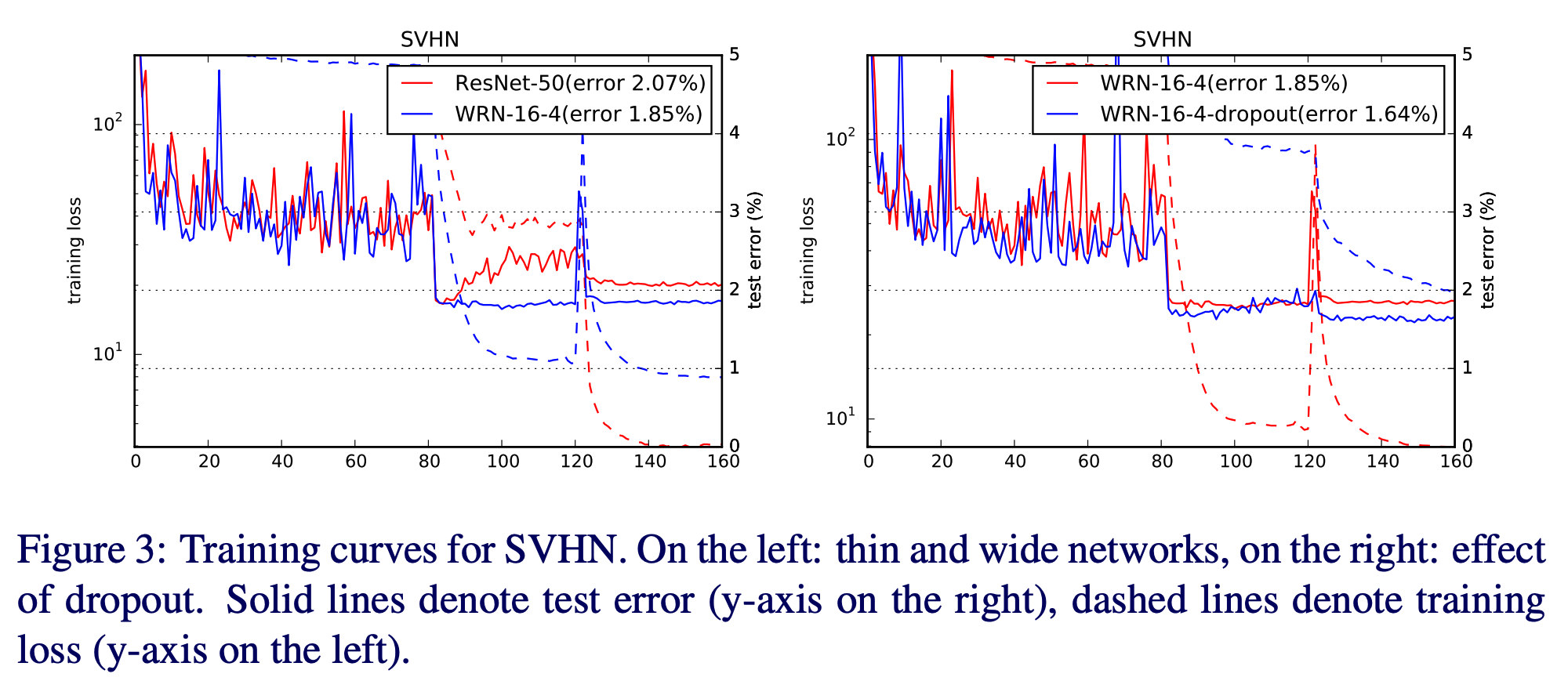
Dropout in residual blocks
- dropout 을 residual block 에 적용해 봄.
- cross-validation 을 이용해서 CIFAR 데이터에는 dropout 비율을 0.3 으로 정함. (SVHN은 0.4)
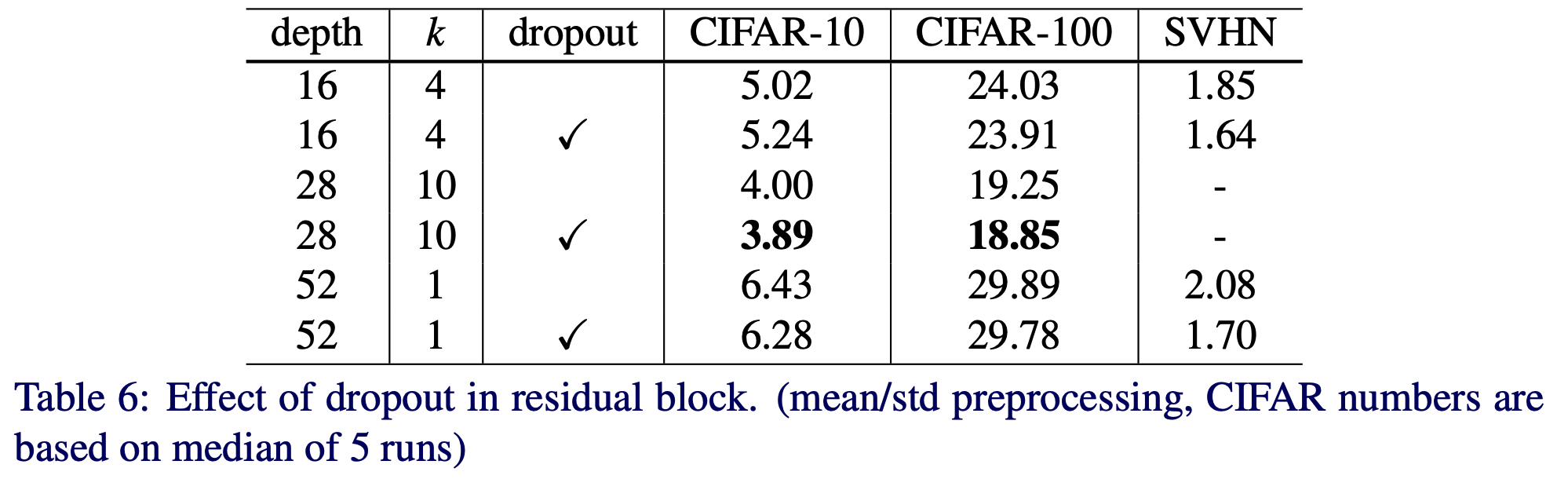
- 확실히 효과가 있음.
- 이상한 현상을 확인함.
- 첫번째 lr drop 이 발생하는 순간 loss 와 validation error 가 갑자기 올라가면서 흔들림.
- 이 현상은 다음 lr drop 까지 지속됨
- 이 현상은 weight decay 때문에 발생하지만 이 값을 낮추어버리면 accuracy 가 떨어짐.
- dropout 을 쓰면 이 현상이 개선된다.
ImageNet & COCO experiments
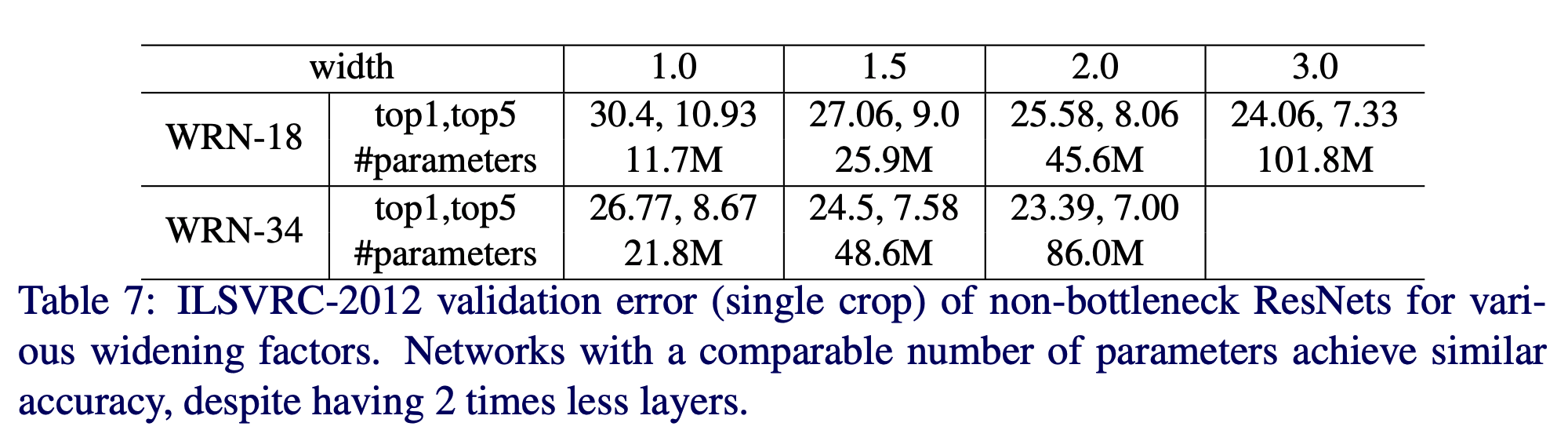
- non-bottleneck ResNet-18 과 ResNet-34 로 실험.
- 여기에 WRN 을 적용해 본다.
- \(width\) 를 1.0~3.0 으로 조정해 봄.
- \(width\) 가 증가하면 성능이 올라감.
- 그리고 파라미터 수가 비슷하면 성능도 얼추 비슷
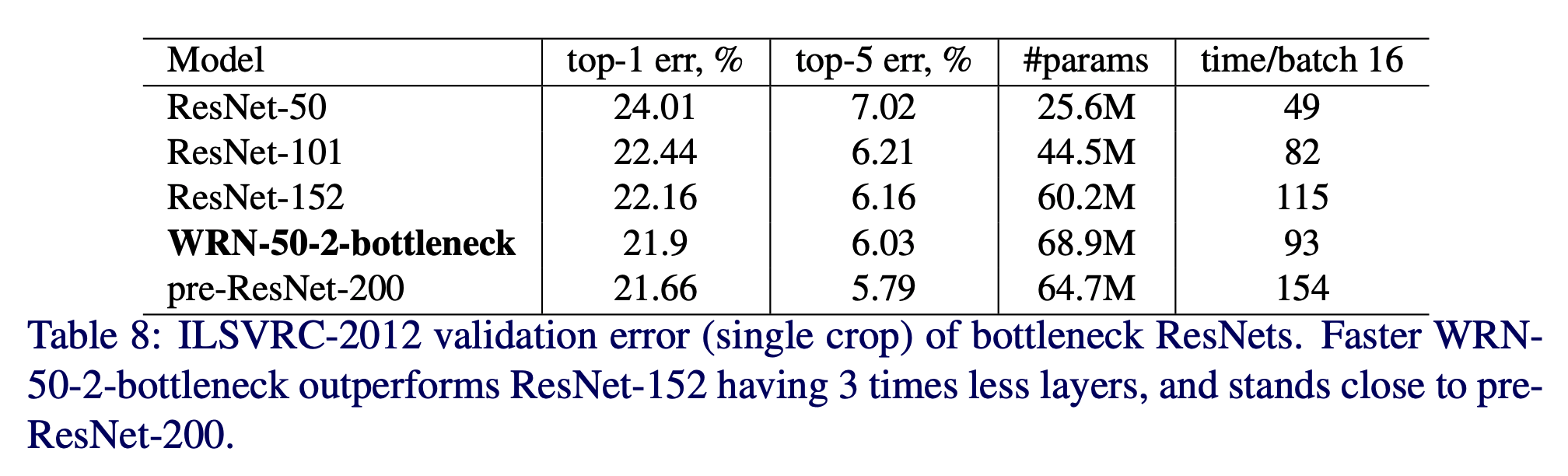
- 다음으로 WRN-34-2 를 이용해서 Object-Detection 문제를 풀어본다.
- MultiPathNet과 LocNet 을 함께 사용
- 34 layer 밖에 없는데도 SOTA 찍음
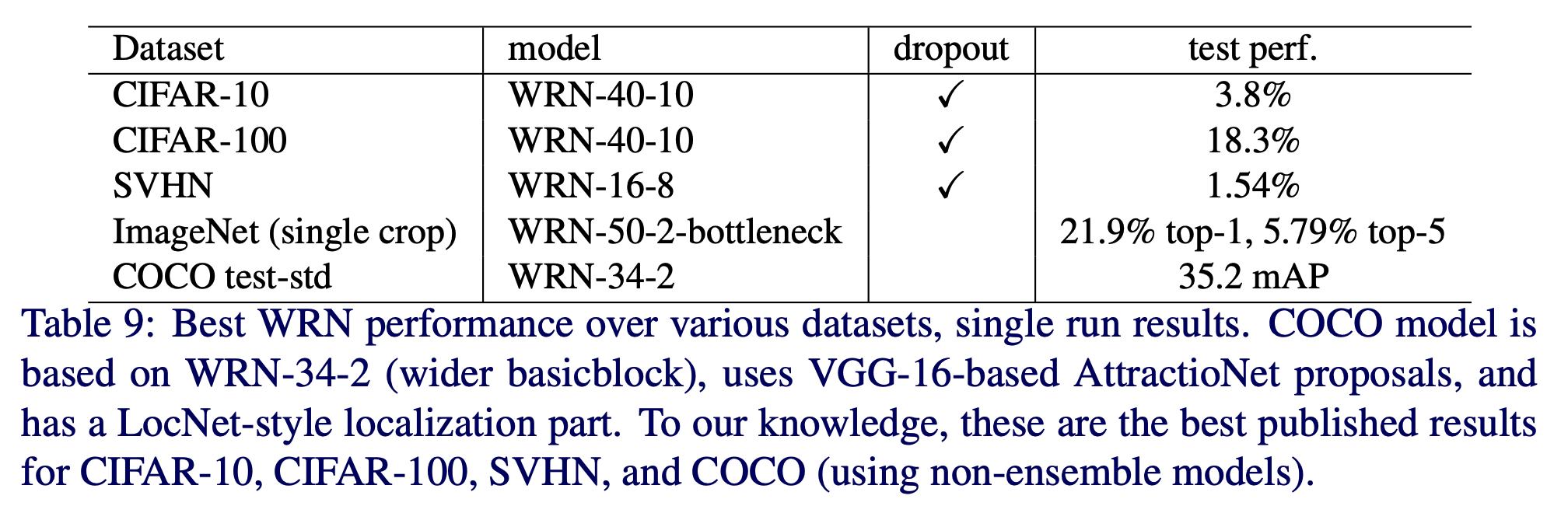
Computational efficiency
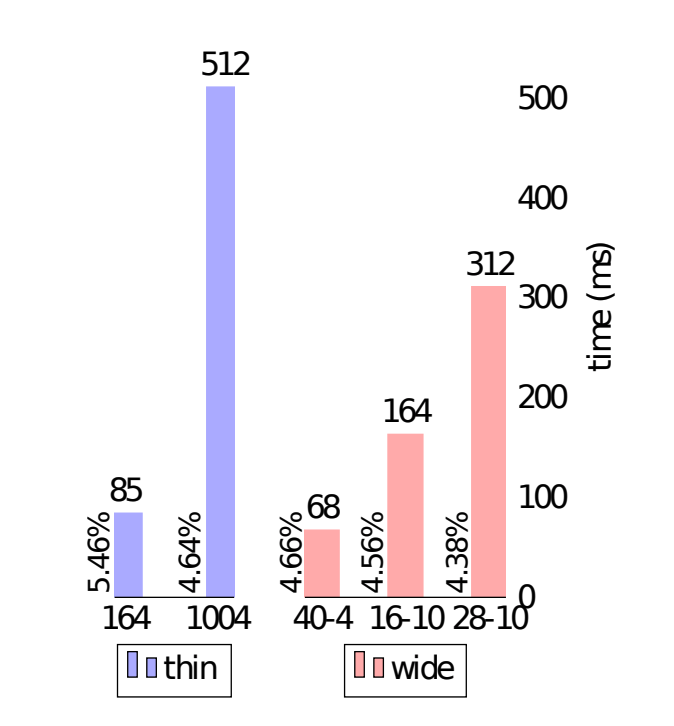
- Thin & Deep Network (그냥 ResNet을 의미함) 은 GPU 활용이 어려운데 기본적으로 Seq. 연산이기 때문
- 성능을 올리려면 당연히 최적화가 필요
- CUDNN.v5 와 Titan.X 로 간단하게 forward+backward+update 연산을 계산해 봄.
- batch 크기는 32를 사용
- ResNet-1001 과 WRN-40-4 를 비교
- 비슷한 정확도를 보임
- 8배의 속도 차이.