문제 발견.
- 서비스를 위한 분류 모델을 작성 중 다음과 같은 이상 현상을 확인함.
- 사용된 backbone 은 resnet-50 모델
- 모든 과정은 동일하고 이미지 전처리 방식만 다름.
- 왼쪽은
tf.image.resize_bilinear(1.4 version), 오른쪽은 다른 이미지 Tool 의 resize 함수.- 왼쪽의 분류 결과는 높은 확률 값으로 ‘가방’이 나옴.
- 오른쪽의 분류 결과는 높은 확률 값으로 ‘옷’이 나옴.
- 그런데
resize결과만 봤을 때에는 tf resize 함수의 품질은 별로다. (오히려 3rd party resize 함수가 더 좋다.) - Overfitting 이라고 생각하기에는 너무 석연치 않은 결과.

Why do deep convolutional networks generalize so poorly to small image transformations?
- CNN은 일반적으로 이미지 변환 및 변형에 강한 모델로 알려져있음. (즉, 일반화에 강함)
- 가장 흔히 사용되고 있는 CNN 모델을 가지고 실험을 해봤더니 실제로는 그렇지 않더라.
- 여기서는
VGG16,ResNet50,InceptionResNetV2를 가지고 테스트. - 오히려 분류에 좋은 성능을 내는 깊은 망을 가진 네트워크들에서 변형에 취약한 것을 확인하였다.
- 여기서는
- 즉, CNN 모델은 통계적 편향(bias)가 존재하며 인간(human)에 비해 일반화 능력이 형편없다는 것을 나타냄.
Introduction
- 사람들은 객체 인식 영역에 있어 CNN 이 인간의 능력을 훨씬 뛰어 넘는다고 생각하고 있다.
- 즉, convolution 과 pool 연산은 image translations, scalings, small deformations 에 강인한 모델이라 여기고 있음.
- 하지만 이전의 연구들 에서도 CNN의 한계점을 확인할 수 있었던 예가 있었다.
- 약간의 입력 이미지 변화에도 CNN 이 잘못된 결과를 제공하는 것을 확인하였음.
- Adversarial Examples that Fool both Computer Vision and Time-Limited Humans

- 물론 이러한 공격(attack)은 입력 이미지에 대한 괴랄할 변형을 가하는 작업을 동반하므로 일반적인 상황에서는 절대 이런 일이 발생하지 않을 것이라고 기대한다.
- 하지만 이 논문에서는 자연에 존재하는 실제 이미지들의 변환에 의해 CNN이 정말로 불변성(invariant)을 가지는지를 확인해 볼 것이다.
- 이를 대중적인 CNN 인
VGG-16,ResNet-50,InceptionResNet-V2에 대해 확인을 해 볼 것이다.
- 이를 대중적인 CNN 인
CNN의 실패?
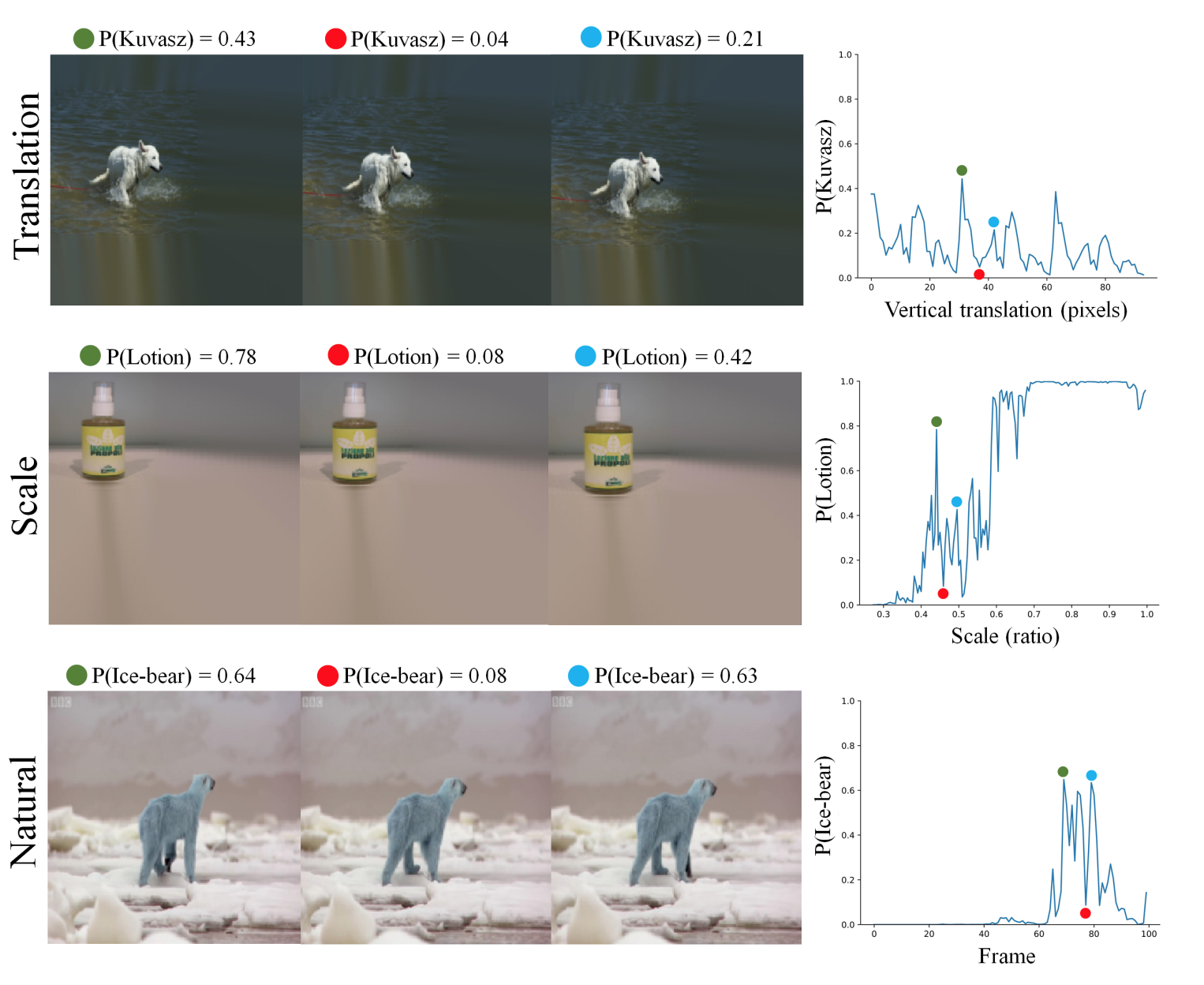
- 여러 입력 변화에 따른 CNN Prediction 결과의 변화 (InceptionResNet-V2 를 사용) (동영상 링크)
Translation(간단한 inpainting procesdure 를 사용하여 변환)Scale(여러번 rescaling 작업을 반복)Natural(BBC 필름으로부터 일부 frame 발췌)
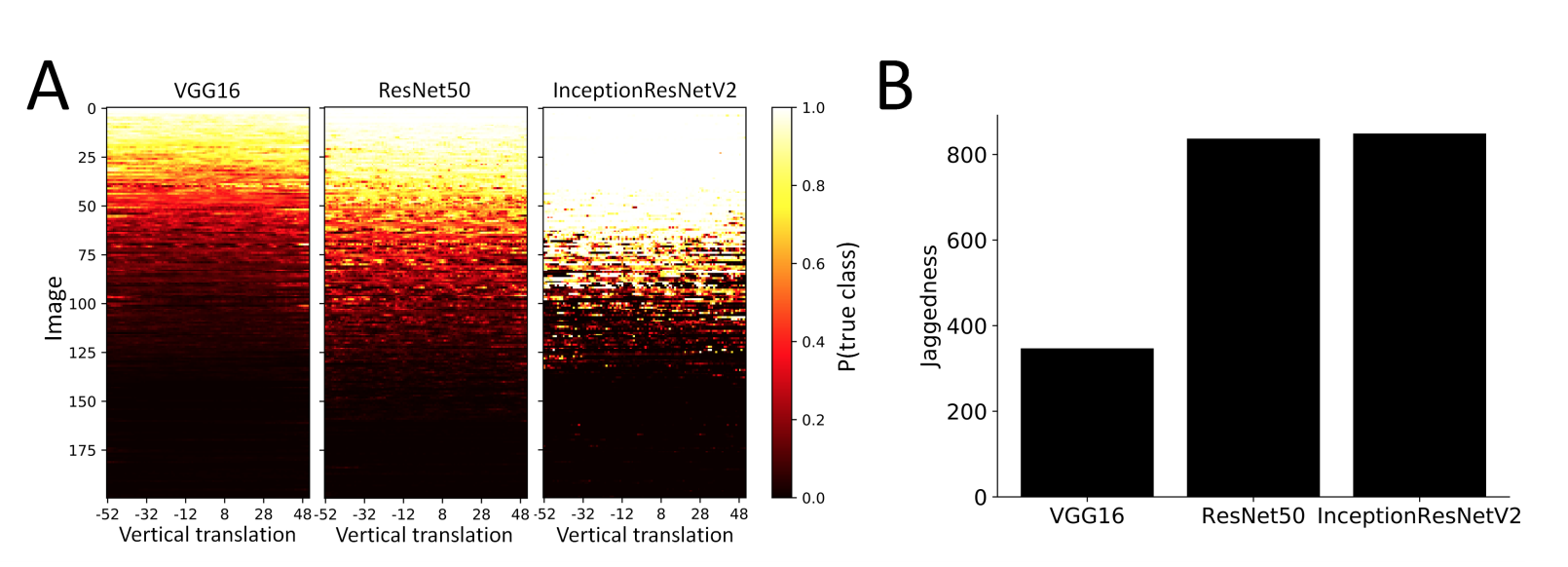
- ImageNet의 validation set에서 200개의 이미지를 랜덤하게 추출하여 translation 에 대한 실험을 수행한 것이다.
- 그림에서 밝은 색은 정답 레이블로 부여했을 경우를 의미하고 검은색의 경우 잘못된 결과를 부여한 경우이다.
- 중요한 것은 변화에 따라 결과가 달라지지 않아야 강건한 모델이라는 의미이다.
- 즉, 변화를 주더라도 밝은 색은 계속 밝은색으로, 어두운 색은 계속 어두운 색으로 유지되어야 한다.
- 눈으로 보기 좋게 적당히 sorting 처리함.
- 위의 결과를 보면 약간의 translation 에도 결과가 매우 민감하다는 것을 알 수 있다.
- 특히
InceptionResNet-V2의 경우 색 변화 차이가 급격하다. (백->흑, 흑->백)
- 특히
- 그런데 불변성(invariant)를 확인하려면 좀 더 명확한 기준이 필요하다.
- 여기서는
jaggedness([dƷӕgɪdnis] ‘들쭉날쭉’이라는 뜻) 라는 정량적 지표를 내세워 불변성의 정도를 측정한다. - jaggedness
- 최초 망의 결과로 top-5 내에 정답이 포함되어 있는 이미지에서 1개의 pixel을 임의로 이동
- 이후 top-5 내에 정답 클래스가 삭제되는지를 확인
- 실제 이 방식으로 28% 의 이미지의 클래스가 변경된다는 것을 확인.
- 한가지 특이한 사항은 망의 깊이에 따라 결과가 다르다는 것이다.
- 망의 깊이가 깊을수록 정확도는 더 높지만 불변성에 취약하다.
- 따라서 상대적으로 망의 길이가 짧은
vgg가translation에 훨씬 안정적이다.
- 참고로 각 Net 의 정확도와 크기는 다음과 같다.

- 결과를 보고 자연스럽게 떠오르는 의문은 혹시
resize나inpainting도 연관이 있지 않을까 하는 것이다. - 이를 알아보기 위해서 또 다른 방법으로 테스트를 수행한다.
- ImageNet 에 Bounding Box 정보가 포함되어 있는데 여기에 있는 Object 를 중심으로 적당히 Cropping 을 수행한다.
- 이렇게 모은 이미지로 다시 평가를 해본다.
- 이렇게 하면
inpainting이나resize문제는 없다.
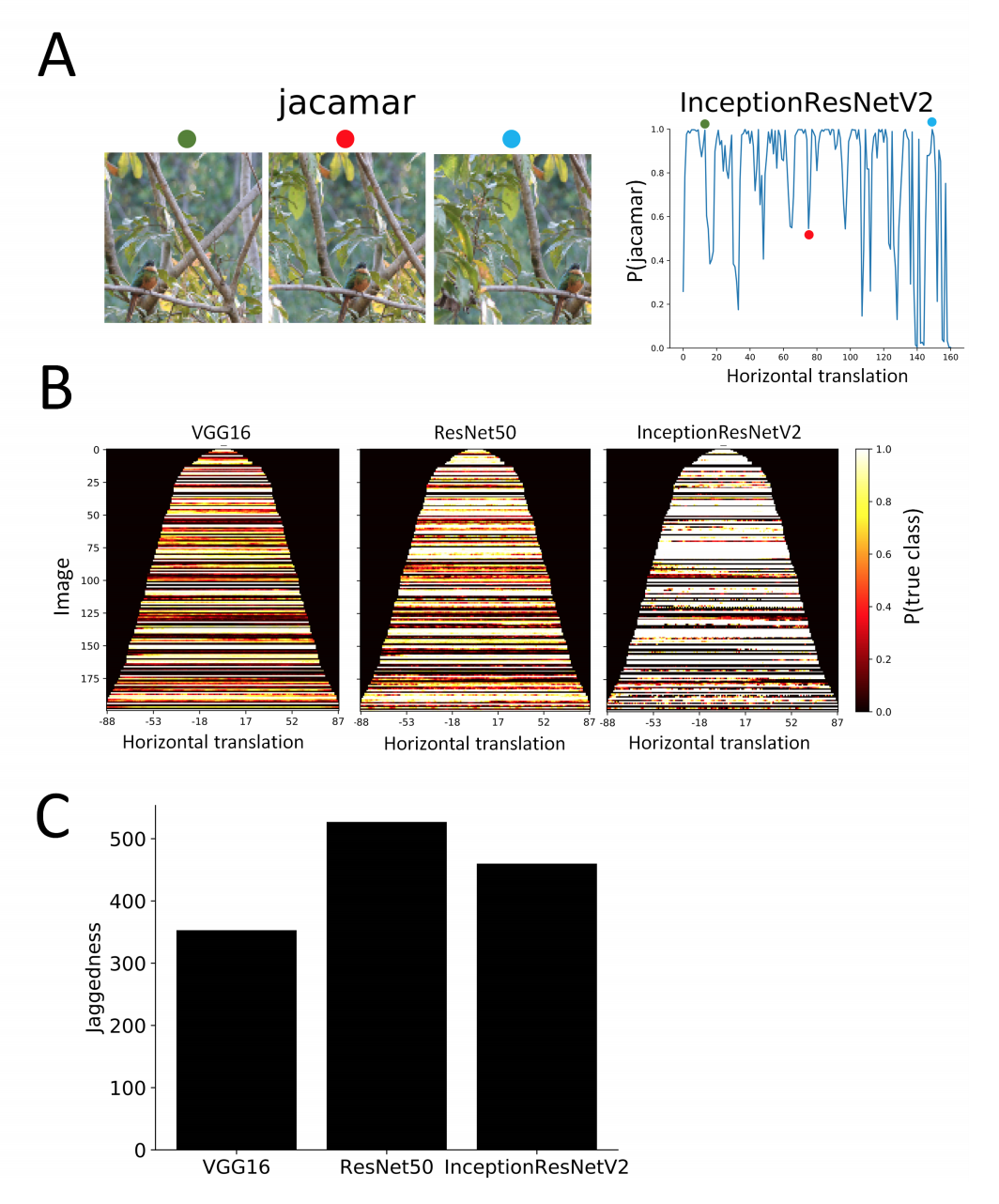
- 그림(A)를 보면 동일하게 확률값이 지그재그로 움직이고 있는 것을 확인.
- 그림(B)는 Bounding Box 크기 순으로 정렬 뒤 표기.
- 역시나 색상 변화가 심한 것을 확인할 수 있다.
- 그림 (C)는
jaggedness를 확인. 앞선 결과와 비슷한 결과를 얻는다.
Ignoring the Sampling Thereom
- 그런데 CNN 에서 translation 문제가 발생한다는 것은 조금 의아하다.
- Convolution 연산으로 만들어지는 Representation 은 translation 이미지인 경우 마찬가지로 translation 된 Representation 이 만들어질 거라 생각되기 때문이다.
- 게다가 마지막에 Global Pooling 을 사용한다면 마지막에 pooling 작업을 수행하게 되므로 결국 translation에 대해 불변이 아닐까하는 생각이 들게 된다.
- 참고로 Global Pooling 은
ResNet50과InceptionResNetV2에서 사용.
- 참고로 Global Pooling 은
- 이는
stride라고 부르는 기법을 고려하지 않았기 때문. (다들 아시죠?)stride는 sub-sampling 효과를 발생시킴. (전체 중 일부 영역에 대해 sampling 을 하게 되므로…)- sub-sampling 을 사용하는 시스템에서는 translation 불변성(invariant)을 보장할 수 없다는게 알려져있음. (Simoncelli et al.)
- “‘convolution’ 과 ‘subsampling’ 을 사용하는 시스템에서는 translation invariance 를 정확히 예측할 수 없다.”
- 딥러닝의 경우 매우 많은 수의 sub-sampling 연산이 포함되어 있기 때문에 sub-sampling factor 가 매우 크다.
- 정확히는 모르겠으나 Simoncelli 는 이러한 subsampling 의 불변성 영향도를 지표로 뽑을 수 있나보다.
- 예를 들어
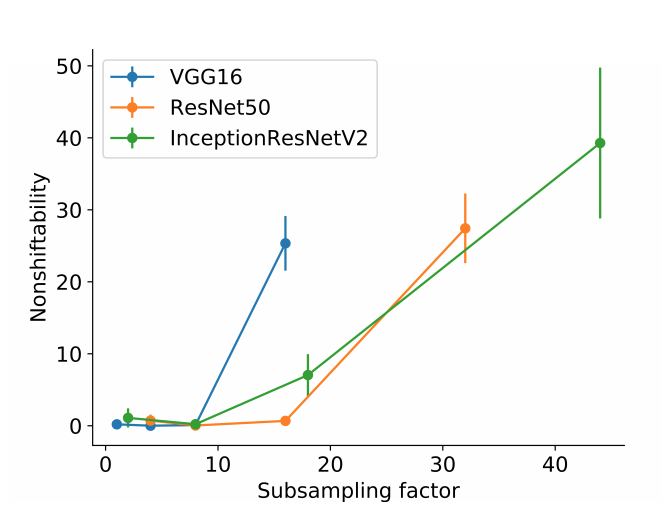
InceptionResnetV2는 subsampling factor 가 45이고, - 따라서 가능한 모든 변환(translation) 중 \(\frac{1}{45^2}\) 만 불변성을 보장한다고 기대할 수 있다.
- 예를 들어
- 정확한 계산법은 Simoncelli 논문을 봐야 할 듯.
- Simoncelli 는 또한 변화 불변성(translation invariance)보단 덜 엄격한 형태의 수치로서
shiftability라는 값을 정의하였다.- 여기서는 이 개념을 좀 더 확장하여
shiftablity가 고정되면 Global Pooing 이 언제나 불변성을 보장한다는 것을 증명한다.
- 여기서는 이 개념을 좀 더 확장하여
- 증명 수식이 있으나 반드시 필요한 것인가 싶다.
- \(r(x)\) 는 이미지 위치 \(x\) 에서 얻어진 feature 값을 의미한다.
Observation
만약 \(r(x)\) 가 convolution 연산이라면 global pooling \(r=\sum_x r(x)\) 는 translation invariant 하다.
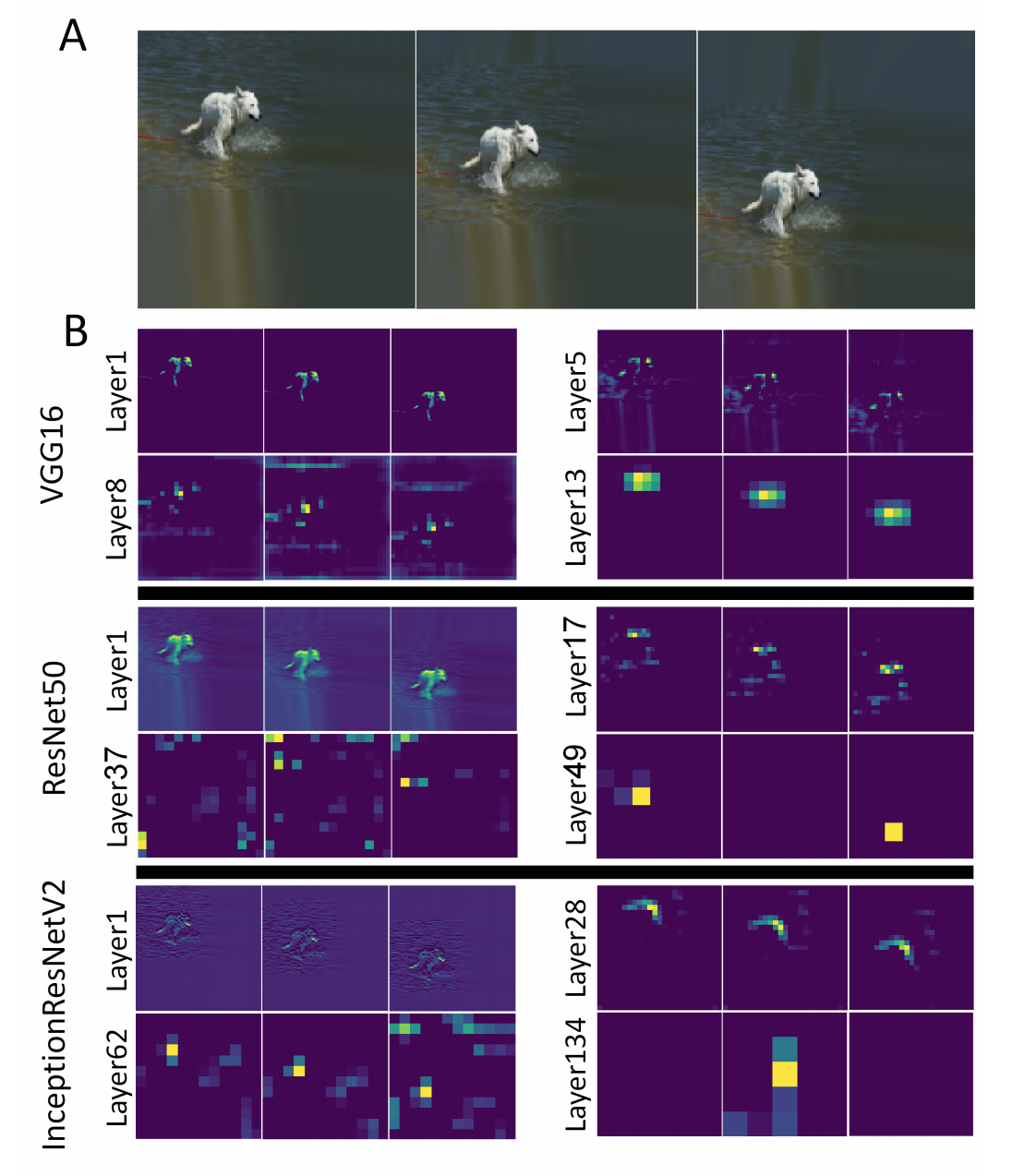
- 그림 (A) 는 vertical 에 대해 이미지를 이동한 것이다.
- 그림 (B) 는 각 레이어에 대해 활성화된 영역을 확인할 수 있다.
VGG의 경우 객체의 shift 에 대해 비교적 잘 동작함을 확인할 수 있다.- 심지어 마지막 레이어에서도 blury 한 패턴으로 객체 정보가 남아있음을 알 수 있다.
- 그리고 pooling 을 위한 전체 합(sum) 도 모든 경우에 대해 비슷하게 값을 얻을 수 있다.
- 다른 두 network는 VGG 에 비해 좀 더 sharp 한 형태로 정보를 남기게 된다.
- 하지만 뒤로 갈수록 shiftablity 는 없어진다.
- 마지막 레이러를 보면 하나의 위치에서만 특징점(response)을 보이며 다른 지점에서는 거의 값이 발생하지 않는다.
- 이를 통해 shiftable 하지 않음을 확인할 수 있다.
- 위의 그림은 무작위로 선택된 feature map 에서 입력 데이터가 이동함에 따라 global sum 값이 평균값의 20% 이상 변화하는 횟수를 계산한 값이다.
- (10개의 샘플을 무작위로 선별하여 평균값을 계산한다.)
- 만약 입력 이미지의 이동에 따라 정상적으로 활성화되는 영역이 따라서 이동하게 된다면 비이동성 값은 0이 되어야 한다.
- 결국 (그림에서 알수 있듯) 망이 깊어질수록 transition 불변성을 유지하기가 힘들어진다.
왜 CNN 은 데이터로부터 invariant 를 학습할 수 없을까?
- 지금까지 살펴본 내용으로는 CNN 은 자연스럽게 invariant 를 얻을 수 있는 모델은 아님을 확인했다.
- 하지만 학습 데이터에 대해서는 transition invariant 를 습득할 가능성이 있다.
- 이를 확인하기 위해 ImageNet 학습 데이터에 포함된 데이터 중 5개의 카테고리 데이터에 대해 확인을 해본다.
Tibetan terrier,elephant,pineapple,bagel,rowing paddle
- 앞선 연구들의 결과에 따라 ImageNet 데이터가 translation과 rescaling 에 대해 불변성을 보장하지 않는다는 것이 알려져있다.
- 아래 그림을 보면
Tibetan terrier의 두 눈 사이의 점의 위치를 도식화한 결과이다.
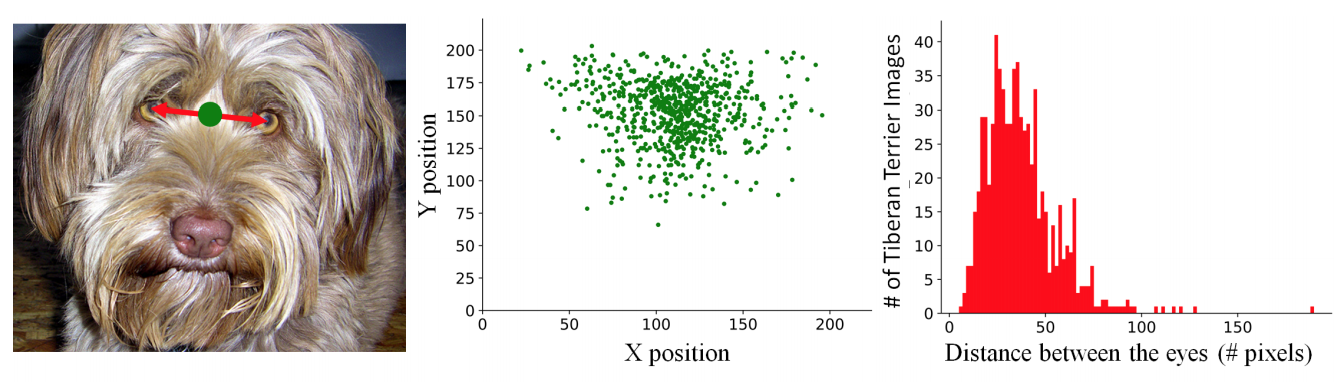
- 간단히 생각해보면 uniform distribution 을 가져야 할 것으로 생각되나 실제 결과는 그렇지 않다.
- 나머지 5개의 카테고리에 대해서도 비슷한 형태로 값을 만들어 측정해보면 비슷비슷한 결과를 얻는다.
- 이를 좀 더 정량화하기 위해서 사용 가능한 bounding-box 레이블를 활용하였다.
- BBox 의 중앙점과 높이를 쌍으로 하여 이미지 내에서 각 객체의 위치와 크기를 정량화하였다. (uniform을 만족하는지 알아보기 위해)
- 확인 결과 1000개의 class 중 900 개 이상의 클래스가 당연히 uniform 하지 않다는 것을 확인하였다. (극단적으로 non-uniform하다.)
- 요약하자면, ImageNet 의 객체들은 극단적으로 bias 된 데이터라는 것.
- 물론 학습 데이터가 invariant 하지 않기 때문에 data augmentation 을 사용하고 있다.
- 그런데 진짜 이것이 불변성을 유지하는데 도움이 되는 것일까?
- 당연히 안된다. 우리가 사용하는 pretrained 모델은 당연히 data augmentation 이 적용된 모델이다.
- 이게 왜 안되는지 이해하기 위해서는 subsampling factor 를 알아야 한다.
- (근데 저도 잘 몰라요 ㅠㅠ)
- 최신의 CNN 은 대략 \(45\) 정도의 sub-sampling factor 를 가지고 있기 때문에,
- 하나의 이미지에 대해 \(45^2 = 2025\) 개의 augmentation 이미지를 갖추어야만 얼추 동작하게 된다.
- 게다가 여기에 rotation 과 scaling 에 대한 불변성을 추가하려면, 지수적인 변환 이미지 수가 필요하게 된다.
현실은 어떠한가?
- 지금까지 CNN이 image transformation 에 별로 강건하지 않다는 내용을 열심히 살펴보았다.
- 하지만 이미지 평가 결과를 보면 이미 인간을 압도하고 있다는 이야기들을 하고 있다.
- 이렇게 평가받는 이유는 간단하다.
- 학습 집합과 평가 집합이 동일한 bias 를 가지고 있다.
- 그래서 평가셋에 서로 다른 크기나 위치 정보가 반영되어 있지 않다.
- 이 이야기는 ImageNet 으로 학습한 모델을 가지고 새로운 형태의 입력 이미지를 평가하게 되면 엉망이 된다는 이야기이다.
- 아래 그림은 동일한 이미지에 대해 rescale 시 어떻게 성능이 변화하는지를 살펴본 그림이다.
- 인간의 경우 무슨짓을 하든 결과를 잘 맞춘다.
- 하지만 CNN 의 경우 이미지 크기가 반으로 줄면 성능이 50% 이상 하락한다.
- 그 대신 ImageNet 에 들어가 있는 크기 수준에 맞추면 거의 인간 수준의 성능을 가지게 된다.
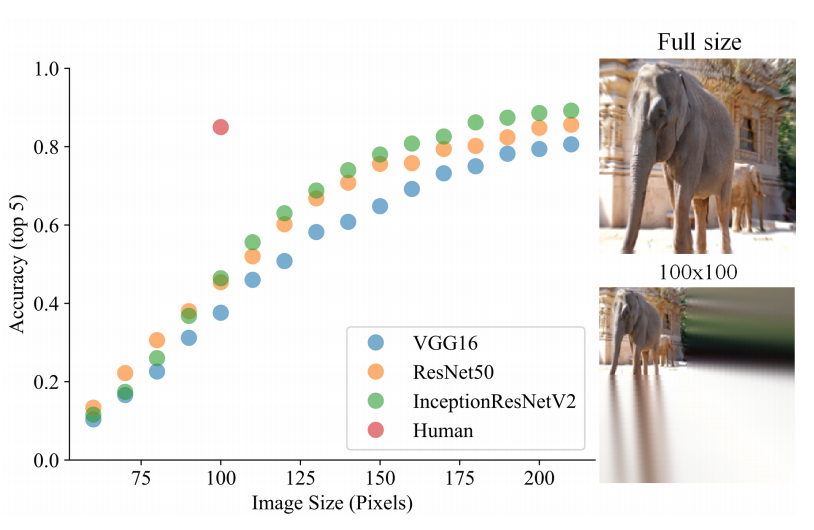
- 따라서 현실적으로 inference 시에도 어느 정도 성능을 유지하려면 test time augmentation 을 도입해야 할 수도 있다.
논의
- CNN 아키텍쳐는 convolution 과 pooling 과정을 통해 deformation 된 이미지에 대해서도 invariant transition 을 보장한다.
- 하지만 sub-sampling (=
stride) 가 사용되면 CNN 이 고전적 sampling 이론에 따라 불변성을 가지지 못한다는 증거를 제시하였다. - 학습 데이터로부터 불변성을 학습할 수 있다는 가능성을 가지고 있으나, ImageNet 예제를 통해 이미 학습 데이터가 bias 된 정보를 가지고 있기 때문에 불변성을 확보할 수 없음을 확인하였다.
- 또한 불변성을 학습하기 위한 augment 데이터가 지수적으로 증가하기 때문에 데이터를 증가시키더라도 불변성을 배우지 못함을 논의하였다.