OpenImage
- 올해 구글이 공개한 약 900만개의 이미지 데이터.
- 현재 약 6000개의 클래스를 제공한다.
- 경로 : https://github.com/openimages/dataset
- 실제 이미지를 제공하는 것은 아니고 사용 가능한 이미지 URL이 기술된 Text 파일을 제공한다.
- 따라서 이미지를 사용하고 싶으면 직접 다운 받아야 한다.
- 시간이 없다. URL Missing 비율이 계속 올라간다.
- 토렌트를 활용하기도 하는데 전체 이미지 집합은 아니다.
- 이미지는 Multi-Label 로 기술되어 있으며 2가지 타입으로 나뉜다.
- Machine Generated Labels : 기계가 부여한 레이블
- Human Verified Labels : 사용자가 검정한 레이블.
- 추가로 약 600 클래스의 Bounding-Box도 함께 제공하므로 Object Detection 연구자도 살펴볼만 하다.
Introduction
- 대규모 데이터를 학습하면 CNN 성능이 더 좋아진다는 것은 이미 알려져 있음.
- 그런데 왜 여전히 5년전에 나온 ImageNet 데이터를 여전히 활용하고 있을까?
- 이보다 더 클린한 이미지 데이터 집합을 얻을 수 없기 때문.
- 학습 데이터 확보가 병목이 되는 상황. (대규모 클린(clean) 데이터의 필요성)
- 어차피 힘들다는 것을 알고 있으니 다른 방안들을 고민한다.
- unsupervised learning
- self-supervised learning
- learning noisy annotations
- 그리고 이러한 방식들은 모두 주어진 데이터가 에러를 많이 포함(noisy)하고 있다는 것을 전제로 한다.
- 따라서 말들은 이렇게 하지만 결국 semi-supervied 형태의 학습을 진행하게 된다.
- Noisy를 잘 걸러내어 정수를 뽑아내자.
- 이 논문도 별반 다르지 않다.
- 소량의 정제 데이터 (small amount of clean annotaions)
- 대량의 Noisy 데이터
- “이 둘을 잘 활용해서 더 좋은 모델을 만들자.”
- 일반적인 접근 방법.
- 먼저 Noisy한 데이터 집합으로 학습 후, Clean 데이터를 이용해서 Fine-Tuning
- 근데 생각보다 잘 안된다. (Clean Data의 정보 활용 비율이 매우 낮다.-고 주장)
- 본 논문의 접근 방식
- 이미지를 표현하는 모든 컨셉(concept)을 표기하는 방식으로 이미지 분류를 다룸.
레이블(label) 분류 접근 방식
- 많은 분류 문제에서 타겟 레이블 (Label)은 서로 독립적이라고 가정함.
- 학습 데이터를 이에 맞춘다면 타당한 가정임.
- 하지만 Noisy 데이터에서는 이렇지 않다.
- 많은 class가 서로 연관 관계를 가지게 됨. (상하/포함 관계 등)
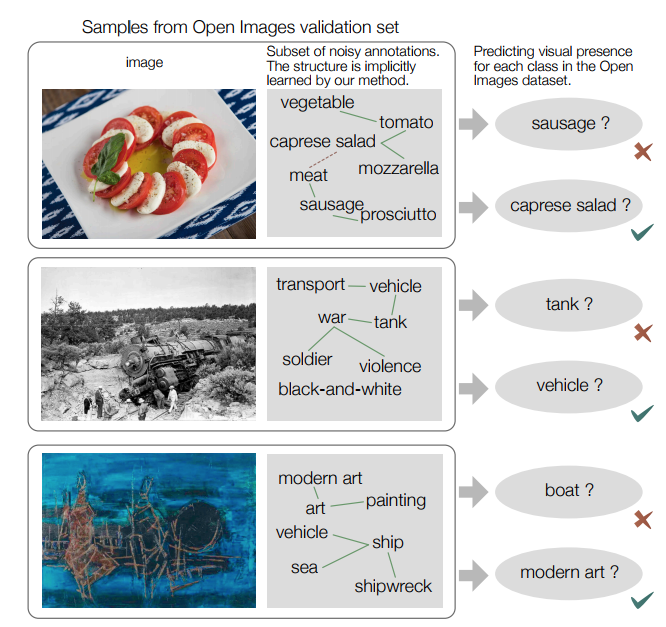
- (그림1)
- 실제 내부적으로는 annotation 사이의 relation을 학습하게 된다.
- 녹색은 강한 양의 상관 관계. 적색은 강한 음의 상관관계.
- 목표
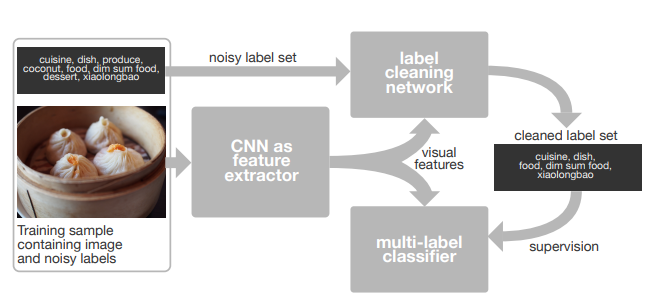
- Noisy 데이터로부터 다중 레이블 분류기(multi-label image classifier)를 만들고 싶다.
- 부가적으로 Noisy 데이터의 정제 버전을 생성할 수 있다.
- 이미지와 레이블의 상관 관계.
- 결국 우리가 필요로 하는 모듈은 Noisy Label 사이의 상관관계를 파악해서 좋은 Label을 추출하는 것.
- 하지만 여기에는 이미지가 반드시 필요하다.
- 예를 들어 ‘코코넛’ 과 같은 annotation은 중의적 의미를 포함할 수 있다. (음료수 or 실제 과일)
- 평가 방법
- Open Image 평가 방법을 따름.
- 그리고 실제 해보니 우리 방식이 짱 좋다.
- 게다가 Clean Dataset 크기가 작은 경우 오히려 Noisy 만을 가지고 학습한 모델보다 추가로 Fine-Tuning 한 것이 성능이 더 나쁘다.
논문의 공헌 (Contribution)
- Multi-Label Image Classifier 를 위한 Semi-supervied 학습 프레임 워크 소개
- 최근 출시된 Open-Image 데이터의 벤치 마크 제공
- 일반적으로 알려져있는 Fine-Tuning 기법보다 더 효과적인 Tuning 방법 제안.
Related Work
- 기존의 방식은 대부분 2가지 방법을 사용함.
- Noisy 데이터로 부터 Noisy 에 강한 알고리즘을 개발하는 방식
- Label 을 적절히 전처리하거나 제거 등으로 강건한 모델을 생성
- Noisy Dataset 과 Clean Dataset 을 적절히 결합하여 모델 성능을 올림.
- 우리가 하는 일과 유사.
- Noisy 데이터로 부터 Noisy 에 강한 알고리즘을 개발하는 방식
Approach
- 일단 두 개의 집합으로 데이터를 구분함.
- 여기서 \(T\) 는 Noisy 데이터이고 \(V\) 는 Clean 데이터를 의미한다.
- \(y_i\) 는 Noisy한 이미지의 레이블(label)이고 \(v_i\) 는 Clean 이미지 (즉, 사람이 검수한) 레이블이다.
-
보통 \(T\) 의 크기는 \(V\) 보다 훨씬 더 크다. (more three orders)
- 사실 전체 구조도만 봐도 대충 뭘 하자고 하는지 이해가 된다.
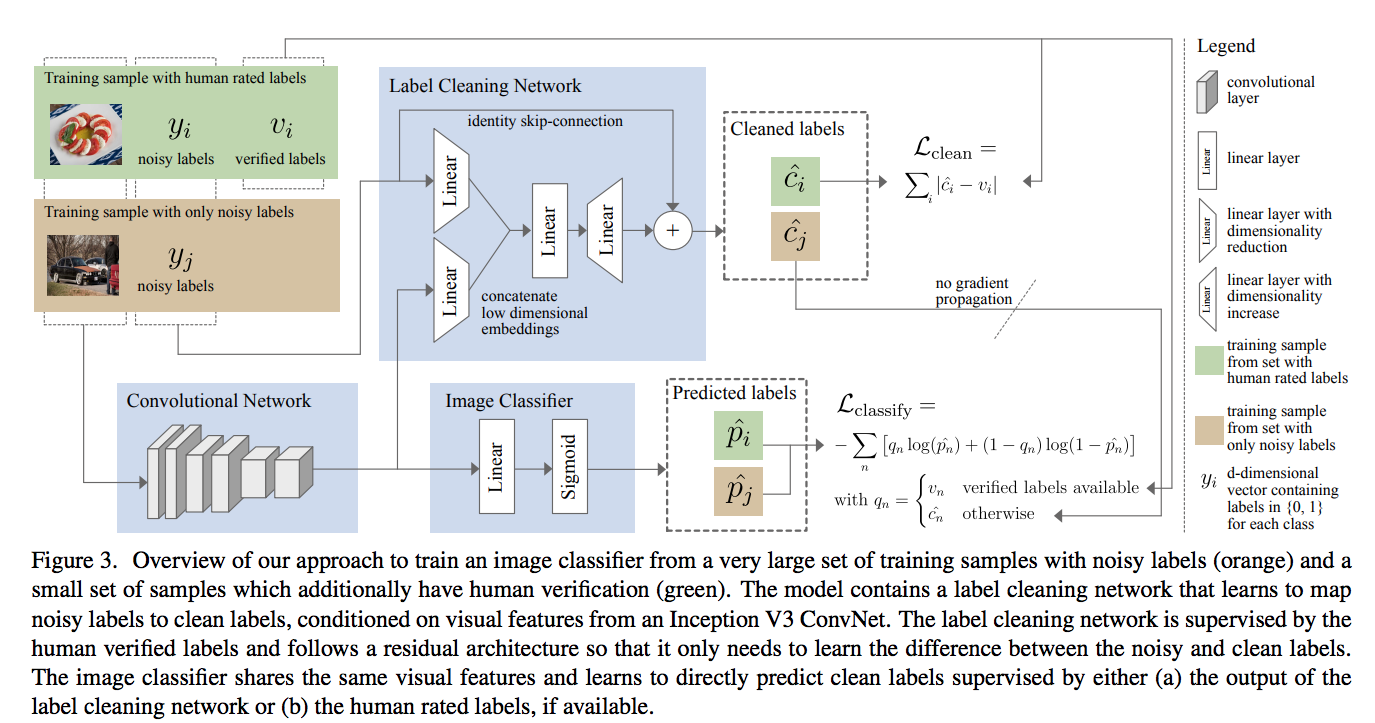
- 여기서 상단의
Label Cleaning Network를g네트워크라고 한다. - 하단의
Image Classifier를h라고 한다. - \(\widehat{c}_i\) 는 Clean class 를 의미한다.
- 따라서 \(\widehat{c}_i = g(y_i, I_i)\) 라고 생각할 수 있다.
- 물론 약간의 추가 작업은 있다. 이건 하단에서 설명한다.
- \(\widehat{p}_i\) 는 실제 맞춰야 하는 class 로 Multi-Label Classifier가 된다.
- 따라서 \(\widehat{p}_i = h(I_i)\) 라고 대충 생각할 수 있다.
- 마지막으로 CNN 백본 망은 \(f\) 로 표기한다.
좀 더 자세히
- \(h\) classifier 는 사실 \(g\) 를 모방하는 classifier라 할 수 있다.
- \(g\) 의 출력 결과를 GT (ground truth)로 사용한다.
- 가장 먼저 이미지를 \(f\) 에 입력하여 이미지 Vector를 얻는다.
- 그런 다음 \(\sigma\) 를 사용하는 \(h = \sigma(w(f(I)))\) 식을 통과하게 된다.
- 즉, \(d\) class 개의 벡터가 출력된다.
- \(\sigma()\)를 사용했으므로 \([0, 1]\) 값이 출력된다.
- \(\widehat{c}\) 를 얻기 위해 사용되는 \(g\) 네트워크는 Noisy 레이블이 입력으로 사용된다.
- 특징 중 하나는 skip-connection이 존재한다는 것이다.
- 왜 이것이 좋을까?
- 결국 Network이 학습하는 것은 특정 Label을 예측하는 것이 아니라,
- 입력된 Label과 실제 GT Label의 차이만을 학습하게 된다는 것이다.
- 출력은 마찬가지로 0~1 사이에 안착되도록 clipping 처리한다.
- 그런데 이미지가 Noisy한 레이블만 있고 사람이 평가한 레이블(즉, \(v_i\) )가 없으면 어떡하나?
- 그냥 원래 Noisy 레이블을 예측하도록 만들어버린다.
모델의 학습
- Clean Loss
- MSE를 쓰지 않는 이유는 해당 데이터가 sparse 하기 때문.
- MSE를 쓰면 출력 결과가 smooth 해질 수 있다.
-
이제 Noisy 데이터 \(T\) 에 대해 \(g\) 를 통과한 결과 \(\widehat{c}_j\) 가 얻어질 수 있게 된다.
- \(h\) 함수는 Human Rate가 존재하는 이미지에 대해서는 원래의 \(v_i\) 값을 \(q_i\)로 사용하고,
-
Noisy 한 데이터에 대해서는 Label Cleaning Network를 타고 얻어진 결과를 \(q_i\)로 사용한다.
- Classify Loss
- 이 때 대부분의 Loss 값은 \(T\) 집합의 Loss에서 나온다는 사실을 염두해두자.
- 따라서 식 (3)의 맨 오른쪽 항이 전체 Loss를 지배하게 된다.
- \(\widehat{c}_j = \widehat{p}_j = {0}^d\) 인 상황을 막기 위해 \(\widehat{c}_j\)를 backprop 하지 않는다.
- 따라서 Cleaned Label \(c_j\)는 image classifier에서는 상수 취급함.
- 실제 학습은 \(g\) 와 \(h\) 망을 함께 학습한다.
- 이를 위해 \(T\) 와 \(V\) 비율을 9:1 로 유지하는 Batch 를 구성한다.
- 이를 이용하여 \(V\) 쪽 데이터를 최대한 많이 활용하면서 전체 classifier를 학습 가능하다.
실험
- OpenImage 데이터를 학습에 사용.
- Traning Set에는 총 79,156,606개의 annotation이 존재한다.
- 이는 이미지당 평균 8.78개의 annotation이 있는 것임.
- 총 이미지의 수는 9,011,219개.
- Validation Set은 총 2,2047,758개의 annotation이 존재.
- 이는 이미지당 평균 12.26개의 annotation이 존재.
- 총 이미지의 수는 167,056개.
- Traning Set에는 총 79,156,606개의 annotation이 존재한다.
- 데이터 특성
- 총 6012개의 클래스가 존재.
- 근데 OpenImage github 에는 5,000개의 클래스라고 밝힘.
- 실제로 제공되는 pretrained model의 class 개수는 6012개.
- 최근 다시 공개한 Resnet101은 또 5,000개의 클래스.
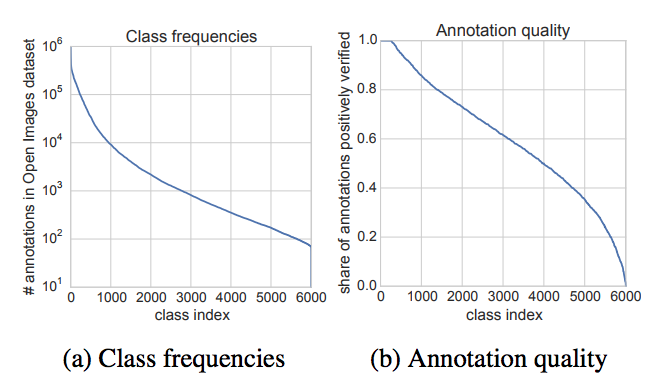
- 클래스 분포가 고르지 못함. (롱테일)
- 예를 들어 ‘vehicle’ 은 약 900,000개의 annotation. 하지만 ‘honda nsx’는 70개.
- 총 6012개의 클래스가 존재.
Class Label 사이의 연관성
- 의미론적으로 가까운 연관성있는 클래스 사이의 차이점을 평가하기 위해 일단 고수준의 카테고리로 구분지어 본다.
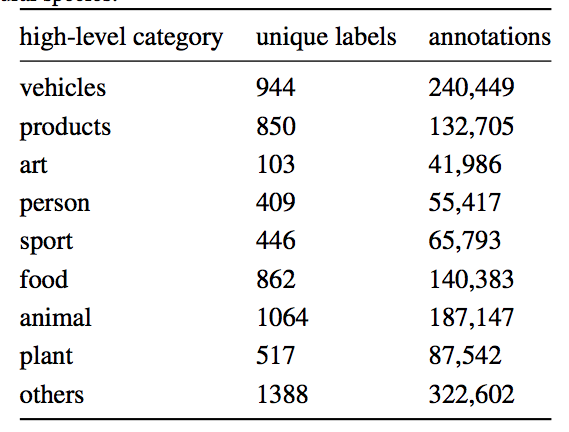
노이즈의 문제
- Validation Set을 이용해서 annotation 품질을 평가해 본 결과 auto annotation 의 26.6%가 false positive이다.
- 그리 각 class마다 품질이 너무 차이가 난다. (위 class 품질 표를 보자.)
- 어떤 class는 완전히 틀린 annotation만 존재하는 경우도 있다.
- 그렇다고 해도 모든 Noise가 완전히 Random하다고 할수는 없다.
- class 사이에 연관성이 존재하기 때문.
Validation Set
- 최종적으로 사용하는 Validation Set을 크게 2개로 나눔.
- 약 40,000개의 이미지 중 1/4만을 cleaning training set으로 사용.
- 나머지 3/4는 classification 에 대한 validation set으로 사용함.
평가 매트릭
- 클래스 분류가 Softmax 방식이 아니기 때문에 일반적인 평가 방식은 사용하지 못한다.
- 그래서 여기서는 각 클래스마다 품질 Score를 만들어내어 사용함.
- 사실 OpenImage 데이터에 대한 표준 평가 절차가 없다.
- 따라서 적당한 성능 매트릭으로 널리 사용되는 AP를 사용함.
- \(Precision(k, c)\) 는 \(k\) 개의 annotation을 사용할 때 클래스 \(c\) 에 대한 정밀도(precision)
- \(rel(k, c)\) 는 indicator function으로 실제 해당 클래스인 경우 1, 아닌 경우 0
- \(N\) 은 validation set 크기
- 모든 클래스(6012개)에 대해 \(AP\)를 구한 뒤 평균내어 최종 \(mAP\)를 만들어낸다.
-
좀 더 일반화된 방식으로 모든 클래스를 동일한(?) 클래스에서 나온 것처럼 계산하는 \(AP_{all}\) 도 다로 구한다.
- OpenImage 이미지의 Validation Set 또한 자동 생성된 annontations
- 이 부분은 사람의 verification이 없는 클래스들은 어떻게 해야 하는가 하는 문제가 발생
- 사람들이 특정 클래스에 대한 verafication만 수행하였다.
- 한가지 방안은 사람이 확인하지 않은 클래스를 부정적인 예제로 간주하는 것.
- 그런데 데이터 집합을 보면 꽤나 적절한 annotation임애도 불구하고 사람이 검증하지 않은 경우도 많다.
- 따라서 이 논문은 사람이 검증하지 않은 클래스는 평가에서 무시
-
평가 결과는 다음과 같다.
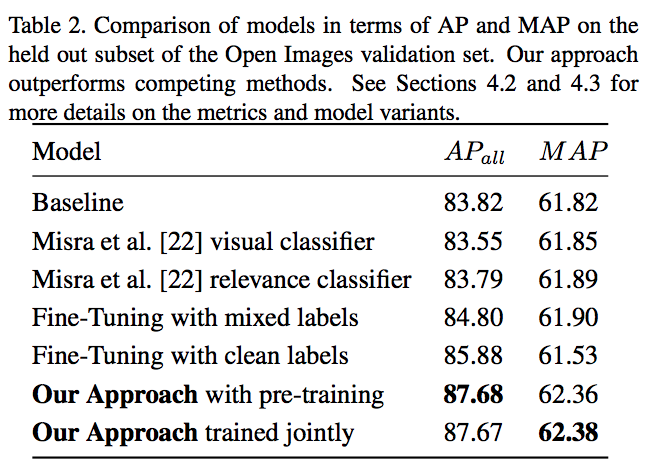
- BaseLine : 오로지 noisy 데이터로만 학습
- Fine-Tuning with mixed labels : noisy + clean 을 섞어서 Fine-Tuning
- 섞는 비율은 9:1 (9가 noisy)
- fine-Tuning with clean labels : 오로지 clean 데이터로만 fine-Tuning
- Our Approach with pre-training : 먼저 clean label network를 학습한 뒤 classification과 clean label network를 동시 학습
-
Our Approach with jointly : Batch로 두 네트워크를 동시에 학습
- 고찰
- 일반적으로 \(AP_all\) 지표가 더 높게 나온다.
- 평균적인 정밀도는 rare 클래스보다는 normal 클래스들이 더 높다.
- 모든 annotation을 동등하게 비교하면 모두 명확한 개선을 확인 가능.
- \(AP_all\) 은 특정 클래스로 인해 성능이 향상. 하지만 많은 클래스에서 성능이 저하.
- Noisy 데이터만을 가지고 fine-tuning 하는 경우 오히려 오버피팅
- 우리가 택한 접근 방안 2가지는 사실 큰 차이 없다.
- 따라서 사전에 미리 망을 학습할 필요 없이 한꺼번에 해도 된다.
클래스 빈도와 annotation 품질.
- 상위 10% 일반적인 class에 대한 품질이 매우 좋아짐.
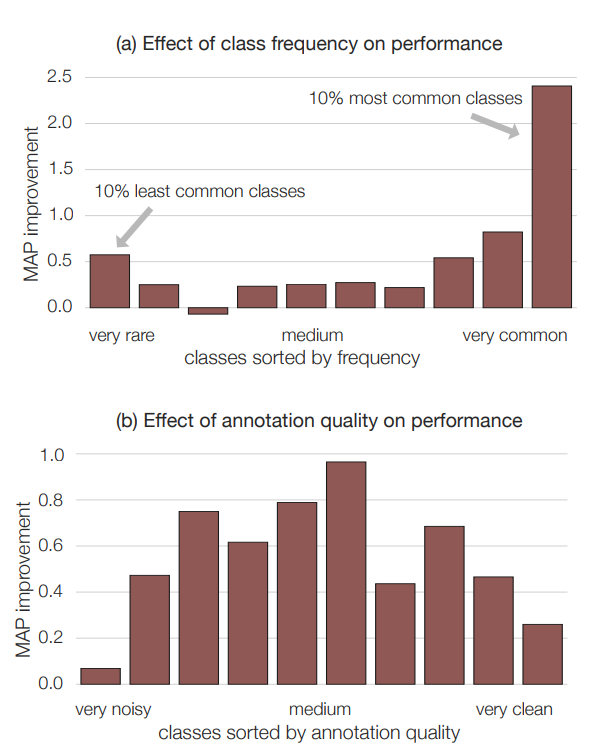
품질 자세히.
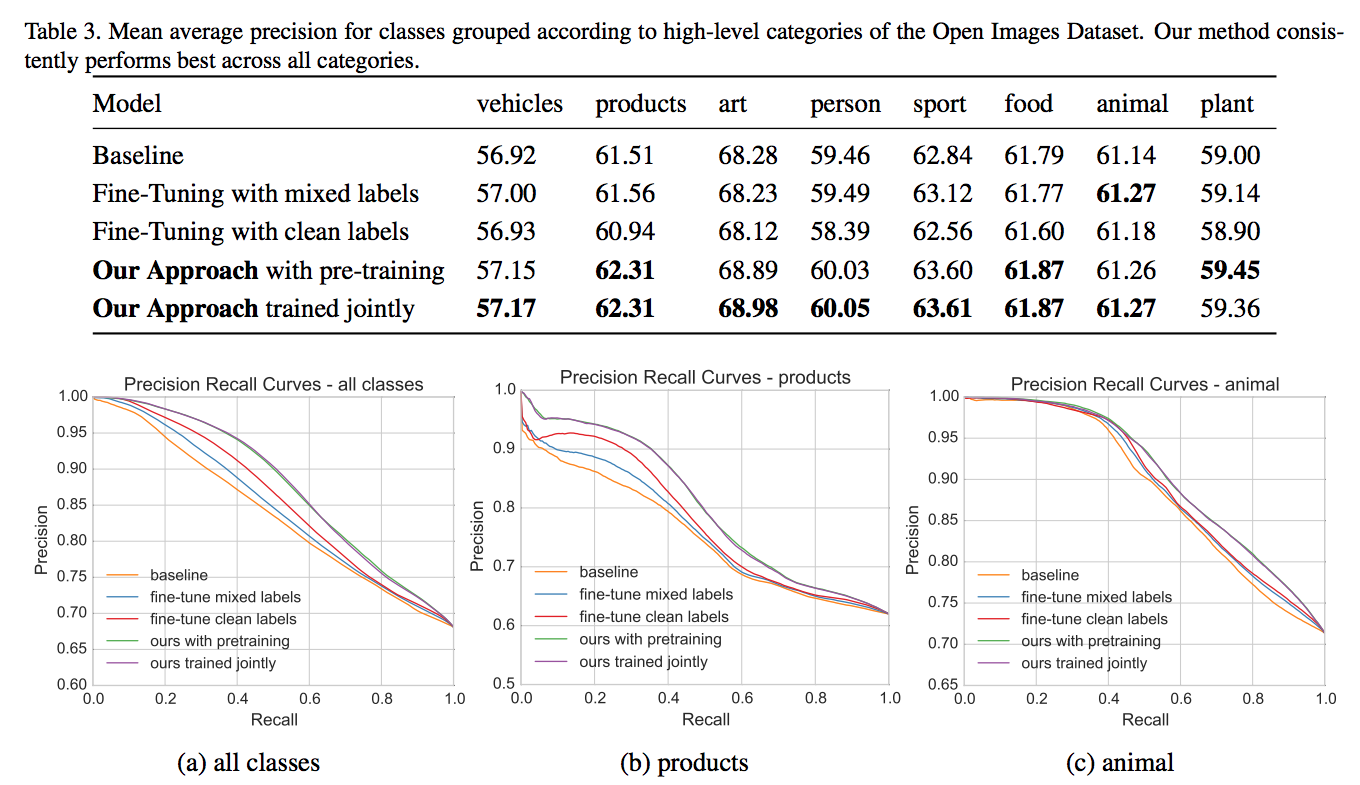
예제
- 다음은 validation set 예제이다.

학습 상세
- 50개의 K40 장비
- 32개의 mini-batch. 총 4,000,000 batch 작업 후 종료
- lr은 0.001 (마지막 레이어)
- Clean Label Netork는 가중치가 0.015
- \(L_clean\) 과 \(L_classify\) 의 가중치는 \(0.1:1\)