소개
- 이 논문은 일반적인 검색 시나리오에서 랭킹 모델을 다룬다.
- 좀 더 구체적으로 보면 기본 랭킹에 의해 얻어진 결과를 재랭킹하는 방식을 다룬다.
- 이미지 피쳐를 랭킹 모델에 바로 포함시키는 것은 잘 동작하지 않는다.
- 이는 텍스트와 이미지 사이의 간극으로 인해 발생한다.
- 이미지 검색에서 텍스트는 noisy하고 이미지 정보를 잘 표현하지 못한다.
- 이를 위해서 보통 각각의 similarity를 구하고 이를 혼합하는 방식을 사용한다.
- 최근의 연구에서는 text 와 visual embedding을 latent 공간에 사상하는 방식도 사용한다.
- 하지만 대부분 가상의 검색 시나리오에서만 테스트되었다.
- 예를 들어 MSCOCO 같은 데이터를 이용해서 실험되었다.
Related Work
Cross-Modal Retrieval
- 기존 연구에서는 cross-modal 과 관련된 두 가지 연구 방향이 있다.
- cross-modal similarity measure
- text와 visual 정보 각각의 similarity를 구하고 이를 결합
- 또는 PRF(pseudo relevance feedback) 방식을 사용
- 원래 feedback 시스템은 사용자의 행동을 입력으로 입력받아 학습하는 방법
- PRF는 사람이 개입하는 대신 첫 검색 결과의 top-k 가 실제 relevant한다는 가정
- 이 정보를 다시 feedback하는 방법이다.
- 예를 들어 top-k 결과를 다시 query 로 사용하는 방식
- shared latent space
- 이미지와 텍스트를 동일한 공간에 사상
- 이 방식에는 몇가지 제약이 존재
- triple loss 를 사용하는데 이에 대한 데이터 구축이 어렵다.
- 게다가 학습 데이터를 구축하기 어렵다. (텍스트가 이미지를 설명하고 있어야 한다.)
- MSCOCO 같은 데이터로 학습을 하더라고 실제 서비스에 사용하기 어렵다.
- MSCOCO는 이미지를 서술하고 있는 학습 데이터가 존재
- 하지만 실제 검색 시스템에서는 쿼리가 매울 짧다. (ex: 파리, 에펠탑)
- neural information IR
- RankNet, LambdaRank 라는 IR 모델도 있다.
- 최근에 신경망을 이용해서 LTR을 해보는 논문이 많아지고 있다.
- 기본 방식은 쿼리-문서 쌍에 대한 랭킹 함수를 신경망으로 구현하는 것.
- RNN, Attention을 활용하여 순위 설계를 하기도 한다.
- GNN (Graph neural network)
- 최근에는 GCN을 사용한 방식이 제안됨.
- GraphSAGE, PinSAGE 등
- cross-modal similarity measure
Learning to Rank Images
Cross-Modal similarity measure
- 최종 목표는 멀티 모달 방식의 PRF를 확장하는 것.
- 먼저 cross-modal similarity 측정 방식을 살펴보자.
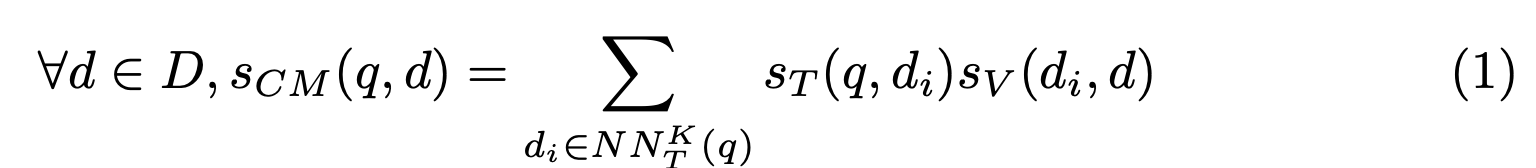
- cross-modal similarity는 텍스트 입력 \(q\)와 텍스트/이미지로 구성된 문서 \(d\)가 존재할 때 얼마나 유사한지를 나타냄
- \(s_T(q, d)\) 는쿼리와 문서의 텍스트 사이의 relevance를 의미한다.
- \(s_V(.,.)\) 는 두 이미지의 nomalized similarity 를 의미한다.
-
\(NN_T^K(q)\) 는 \(q\)에 대해 실제로 유의미한 K 개의 문서 집합을 의미한다.
- 이 방식은 적당히 좋은 결과를 내주기는 하지만 이 방식은 완전히 unsupervised 학습법이다.
- 이로 인해 서로 다른 쿼리에 대해 변경이나 새로운 것을 적용해보기가 쉽지는 않다.
Cross-Modal Graph Convolution
- GCN을 여기에 접목시켜 보자.
Graph Configuration
- 모든 쿼리 \(q \in Q\) 에 대해 그래프 \(G_q\) 는 다음과 같다.
- 그래프 내의 노드는 후보 문서 \(d_i\)를 의미한다. (즉, 쿼리마다 다르다)
- \(h_i\) : 문서 \(d_i\)를 나타내는 그래프 노드
- \(v_i\) : 문서 (d_i\) 에 속한 이미지의 visual embedding
- \(N_i\) : 노드 \(i\) 의 인접 노드 \(j\)들의 집합.
- \(f_ij = g(v_i, v_j)\) : 두 노드 사이의 에지 weight.
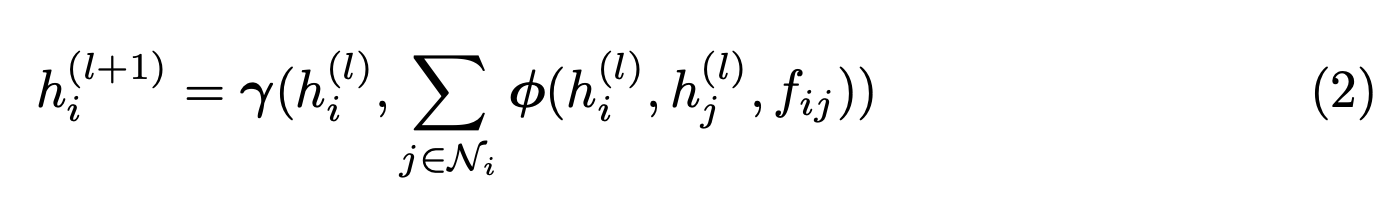
- 여기서 \(\gamma\) 와 \(\phi\) 는 미분 가능한 함수이다. (그냥 MLP라고 생각하자)
- 그럼 식을 단순화 할 수 있다.
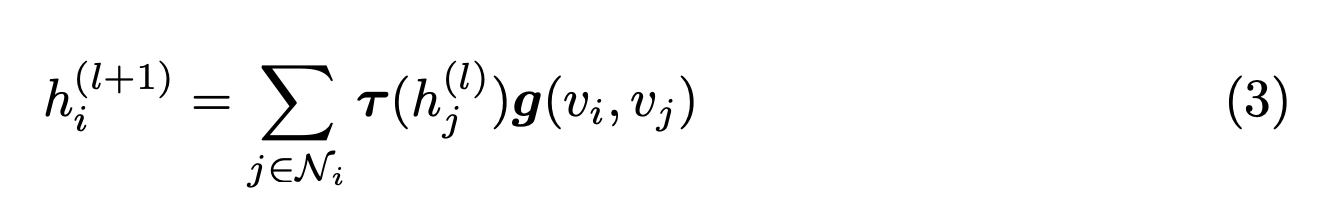
- 이 식은 아까 보았던 (1) 식과 거의 유사하다.
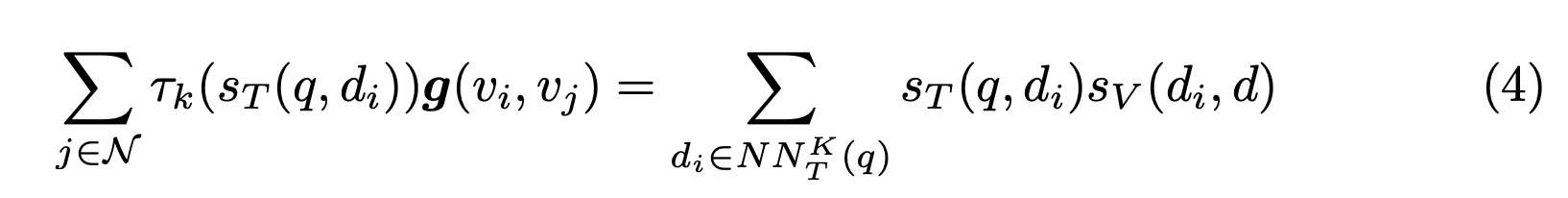
- 여기서는 Graph convolution 식이 PRF 를 적용하는 것과 비슷한 효과를 가져온다고 주장
- Graph 개념을 가져오면 단순한 similarity와는 다르게 여러 레이어를 쌓아 올릴 수 있음
- 미분 가능한 식을 사용하니 학습이 편하다. (NN 돌리면 된다.)
Learning to Rank with Cross-Modal Graph Convolutions
- 우리는 convolution 연산에 아주 간단한 식을 사용한다.
- DCMM (Differentiable Cross-Modal Model)
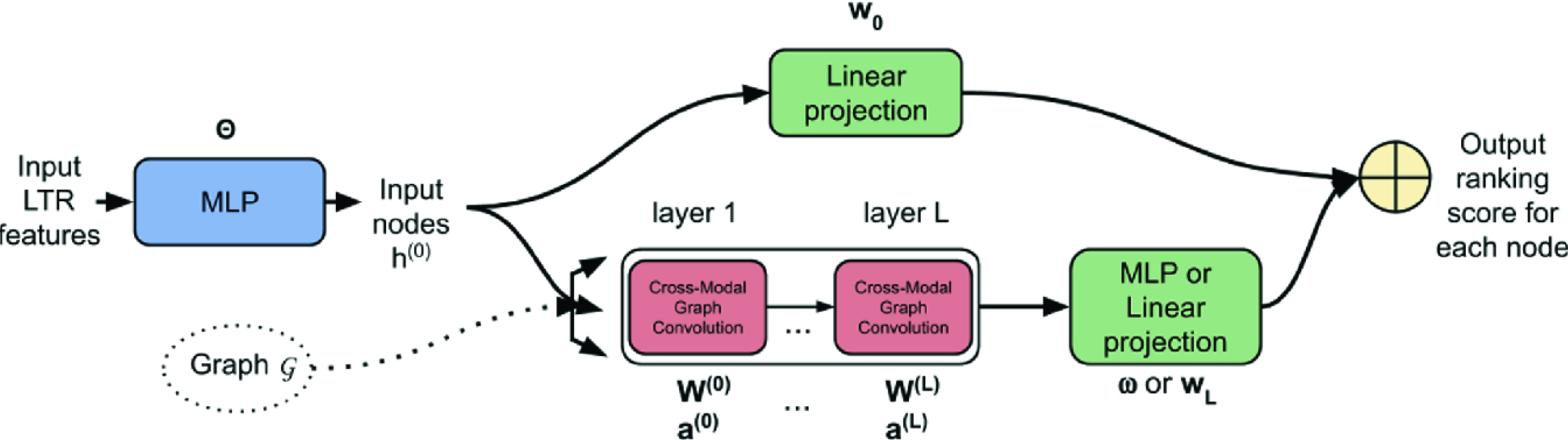
- 최종적으로 두가지 feature의 합을 ranking score로 사용한다.
- 첫번째는…
- 문서의 LTR feature h0를 linear projection 통과시킨 pure text-based score.
- 그림에서 위쪽 브랜치에 속함.
- real-valued score를 얻기 위해 사용한다.
- \(s_T(q, d_i) = w_0^T h_i^{0}\)
- 두번째는…
- 다음 식으로 정의된 값을 사용한다. (여러 층 사용 가능)
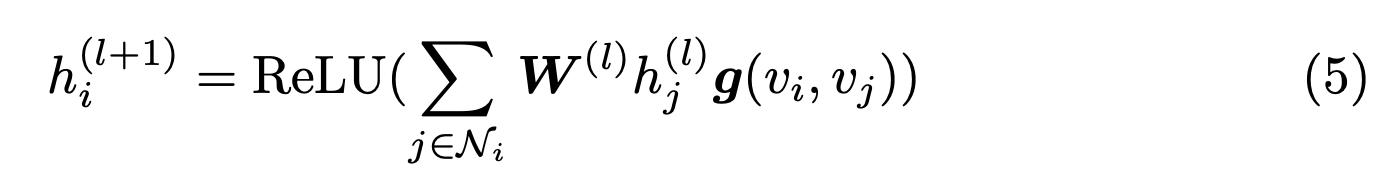
- 여기서 함수 \(g\)는 둘 하나를 사용한다.
- \(g_{cos}(v_i, v_j) = cos(v_i, v_j)\) : DCMM-cos
- \(g_{edge}(v_i, v_j) = v_i^T diag(a) v_j\) : DCMM-edge
- 최종 스코어 함수
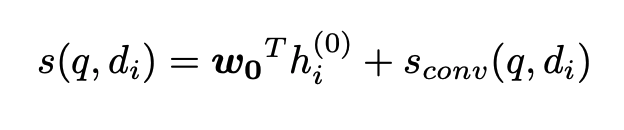
- 최종 학습 Loss는 BPR (Bayesian Personalized Ranking) Loss를 사용하였다고 한다.
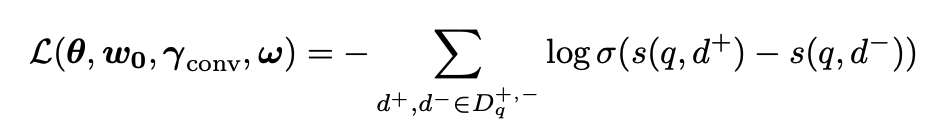
- BPR은 query와 document pair 두 개를 사용하는 Loss로 \(q))와 관련있는 문서는 \(d^+)\)로, 관련없는 문서는 \(d^-)\)로 표기한다.
- 다른 여러 Loss보다 이 Loss 함수가 성능이 좋아 그냥 사용했다고 한다.
Experiments
- 사용한 데이터는 2가지이다.
- MediaEval
- Flickr 검색 결과를 Rank-300 까지 가져온 데이터.
- 사람이 이 결과를 가지고 relevant, irrelevant를 annotation한 데이터
- 이미지별로 caption을 모두 기술
- train : 110 queries, 33,340 images
- test : 84 queries, 24,986 images
- image feature : Inception-V3
- Flickr 검색 결과를 Rank-300 까지 가져온 데이터.
- WebQ
- 네이버 데이터셋 (직접 만든 데이터셋)
- 952 queries, 43,064 images
- text feature : BM25, DESM
- image feature : ResNet-152 (d=2048, ImageNet pretrained)
- MediaEval
- 평가방법 : 5-fold cross validation
- 따라서 MediaEval에서는 training data만을 실험에 사용
Baselines
- 텍스트 피쳐에 바탕을 둔 learning to rank (LTR)
- cross model similarity (CM)
- 텍스트에는 LTR, 추가로 CM을 입력으로 넣어 사용 (LTR+CM)