참고자료
Introduction
- ML 관련 업무가 수년간 경험이 쌓이고 있다보니 실제 시스템에 점점 통합이 되어가고 있는 추세입니다.
- ML 시스템 개발 및 배포는 비교적 쉽고 빠르지만 해당 시스템을 유지하고 관리하는 비용은 매우 큽니다.
- 이에 대해서는 1992년 Ward Cunningham 이 설명한 기술 부채 (Technical debt) 이론으로 설명될 수 있습니다.
- 재정 부채와 유사하게 기술 부채를 감내해야 할만한 전략적 이유가 소프트웨어 공학에서도 존재합니다.
- 모든 부채가 나쁘다고 할 수는 없지만 소프트웨어에서의 기술 부채는 지속적으로 관리되어야 합니다.
- 이를 위해 리팩토링, 단위 테스트, 미사용 코드 삭제, 종속성 제거, API 강화, 문서화 등의 작업을 통해 기술 부채를 줄여가야 합니다.
- 이 때의 목표는 새로운 기능을 추가하는 것이 아니라 향후 개선을 위해 오류가 발생할 수 있는 가능성을 줄여 유지 보수성을 향상시키는 것이 목적이 됩니다.
- 이에 대한 지불을 미루게 된다면 복리 이자를 내야 합니다. 감춰진 부채는 교묘히 숨어들어 있기 때문에 무척이나 위험합니다.
- 이 논문에서는 ML 시스템은 전통적으로 다루었던 코드의 유지 관리 문제 외에도 ML과 관련된 고유의 문제들로 인한 기술 부채가 존재하고 있음을 이야기합니다.
- 게다가 대부분의 문제점들이 코드 수준이 아닌 시스템 수준에 머무르기 때문에 이를 감지하기가 더 어렵습니다.
- 소프트웨어 공학에서 이야기하는 추상화(abstraction)의 경계가 ML 시스템에서는 미묘하게 무너지게 됩니다.
- 기존에 알려진 코드 수준의 기술 부채 제거 방식으로는 이 문제를 해결하기 어렵습니다.
- 이 논문이 이러한 문제를 해결하기 위한 새로운 알고리즘을 제안하는 것이 아닙니다.
- 대신 이 문제들이 얼마나 어려운 트레이드 오프(trade-off) 문제인지를 이해하고 장기적으로 고려해야 할 대상임을 이해시키는데 목적을 둡니다.
- 여기서는 시스템 레벨에서 상호 작용 및 인터페이스에 중점을 둡니다.
- 시스템 레벨에서는 ML 모델이 추상화 영역의 경계를 무너뜨릴 수 있습니다.
- 입력 값들을 재사용 한다거나 또는 연쇄 과정을 만들어내는 경우 의도하지 않은 시스템 결합이 생겨날 수 있습니다.
- ML 패키지는 블랙박스처럼 취급되는데 그 결과 이를 위한 “접착 코드(glue code)” 또는 보정 레이어 (calibration layer)가 필요해지게 됩니다.
- 외부 환경의 변화는 모델이나 입력 값에 변화를 주기 때문에 시스템의 결과에 영향을 미치게 됩니다.
Complex Models Erode Boundaries (복잡한 모델의 경계 침식)
- 전통적인 소프트웨어 엔지니어링은 강력한 추상층 경계를 이용하여 캡슐화, 모듈화 과정을 거쳐 유지보수가 쉬운 코드를 생성합니다.
- 엄격한 추상층 경계(abstraction boundaries)는 주어진 컴포넌트로부터 데이터의 입력과 출력의 불변성과 논리적 일관성을 표현하는데 도움을 줍니다.
- 안타깝게도 ML 시스템은 의도된 행동을 규정하여 엄격한 추상화 경계를 강제하는 방법을 적용하기 어렵습니다.
- 문제는, 실제로 ML 시스템을 사용하는 가장 큰 이유가 외부 데이터에 의존하지 않고 소프트웨어 로직에서 원하는 동작을 효과적으로 구현할 수 없기 때문입니다.
- 결과적으로 추상적 경계가 무너지기 시작하면 기술 부채가 증가할 수 있습니다.
- 이 섹션에서는 이러한 현상이 왜 발현되는지를 다루고 있습니다.
Entanglement (얽힘 현상)
- ML 시스템은 입력 신호를 혼합하여 개선을 불가능하게 합니다.
- 예를 들어 모델 내의 피쳐(feature) 를 \(x_1\), …\(x_n\) 개 사용하는 시스템에서 \(x_1\) 의 입력 분포가 변경되면 나머지 \(n-1\) 개의 피쳐의 중요도, 가중치 등이 모두 변경되야 할 수도 있습니다.
- 이는 모델의 배치 스타일을 사용하던 온라인 방식으로 학습하던 상관없이 동일하게 적용됩니다.
- 이는 새로운 피쳐 \(x_{n+1}\) 을 추가한다거나 혹은 임의의 피쳐 \(x_j\) 를 제거할 때에도 동일하게 적용됩니다.
- 모든 입력은 서로 독립적이지 않습니다. 이를 우리는 CACE 현상이라고 부릅니다.
- CACE 원리 (Changing Anything Changes Everything.)
- 하나가 변하면 전체가 변한다는 의미입니다.
- 이는 입력 시그널의 변경 뿐만 아니라 사용하는 하이퍼 파라미터, 학습을 위한 설정, 샘플링 방법, threshold 결정, 데이터 선택 등 모든 가능한 변경들로부터 발생할 수 있습니다.
- 이를 통합할 수 있는 한 가지 쉬운 방법은 앙상블(ensemble)을 도입하는 것입니다.
- 이 방법은 특정한 경우에는 아주 잘 동작합니다
- 문제 정의상 문제가 서브 태스크로 나뉘어질 수 있는 경우에 적용하기 좋습니다.
- 물론 대부분의 경우에도 앙상블은 잘 동작합니다. 각 모델의 에러는 서로 연관성이 없기 때문입니다.
- 하지만 앙상블 모델은 기본적으로 모델 사이의 강한 얽힘을 가지게 됩니다.
- 따라서 개별 구성 요소를 개선하더라도 전체 성능이 오히려 나빠질 수 있습니다. (다른 컴포넌트들이 강하게 연관되어 있는 경우에 발생할 수 있습니다.)
- 이 방법은 특정한 경우에는 아주 잘 동작합니다
- 두 번째 대안으로 발생할 수 있는 예측 행동을 찾는 것에 주력하는 것입니다.
- 고차원 정보를 시각화할 수 있는 Tool 을 활용하여 다차원 공간을 나누어 분석합니다.
Correction Cascades (수정 전파)
- 문제 \(A\) 에 대한 모델 \(m_a\) 가 존재할 때, \(A\) 와 유사하지만 새로운 문제 \(A’\) 를 해결해야 하는 상황을 가정해 봅시다.
- 이 경우 모델 \(m_a\) 의 결과를 입력으로 하여 \(m_a’\) 를 만들어내는 것을 고려하게 됩니다. (빠른 문제 해결을 위해)
- 하지만 이 경우 새로운 시스템은 \(m_a\) 에 종속적이게 됩니다.
- 향후 개선시에 비싼 비용을 치르게 됩니다.
- 만약 모델 \(m_a’\) 를 가지고 문제 \(A’’\) 를 해결해야 한다면 더 복잡한 상황이 되고 맙니다.
- 이런 시스템을 구성하고 나서 개별 구성 요소의 품질 향상을 진행할 때 수정 전파가 데드락을 만들어낼 수도 있습니다.
- 이에 대한 보완 전략은 각각의 문제 사례를 구분하거나, 같은 모델에 이런 상관 관계를 직접적으로 학습할 수 있는 피쳐를 추가하는 것입니다.
- (설명이 애매하긴 한데 하나의 모델로 해결하라는 의미같다.)
Undeclared Consumers
- 예측 모델 \(m_a\) 의 출력 결과가 로그 등에 기록되어 누구나 접속 가능한 환경에 노출될 수 있는 환경을 생각해 봅시다.
- 만약 어떤 ML 시스템이 이를 입력 값으로 활용하게 되면 이를 undeclared 되었다고 합니다. 암묵적으로 어떤 모델의 출력값이 다른 모델의 입력값으로 활용되는 상태입니다.
- 좀 더 고전적인 소프트웨어 엔지니어링 분야이서는 이를 가시성 부채(visiblity debt)라고 부릅니다.
- 이는 다른 모델에 숨겨진 강한 종속성을 만들어내기 때문에 최고로 비싼 비용이여 최악의 위험성을 내포합니다.
- 만약 모델 \(m_a\) 가 개선되면 모든 다른 파트에 영향을 주게 됩니다.
- 경험적으로 이러한 강 결합은 운영 비용을 빠르게 증가시키고 문제를 어렵게 만들어 냅니다.
- 게다가 이 문제는 숨겨진 피드백 루프 (hidden feedback loop) 를 만들어냅니다. (이는 뒤에 설명합니다.)
- 숨겨진 고객(undeclared consumer)을 찾아내는 것은 매우 어렵습니다.
- 엄격한 접근 제약이 없는 경우 엔지니어들은 (특히 마감이 다가올 때) 가장 손쉬운 정보를 활용하기 때문입니다.
코드 의존성보다 데이터 의존성 비용이 더 크다
- 의존성 부채(dependency debt)는 전통적으로 코드 레벨에서 발생하는 부채 문제였습니다.
- 하지만 ML 시스템에선 데이터 의존성 문제가 더 큰 문제입니다.
- 게다가 더 발견하기 어렵습니다.
- 코드에 의한 의존성 부채는 정적 분석 Tool 등을 활용하여 제거할 수 있습니다. 하지만 데이터에 의한 의존성 부채는 아쉽게도 현재 이런 Tool들이 없습니다.
불안정한 데이터 의존성 (Unstable Data Dependencies)
- 종종 편리함에 다른 시스템으로부터 생성되는 시그널을 입력 데이터로 활용합니다.
- 하지만 일부 입력 신호는 불안정하여 시간지 지남에 따라 정성적 또는 정량적으로 값이 변경됩니다.
- 입력에 대한 엔지니어링 소유권과 일을 소비하는 모델의 엔지니어링 소유권이 다른 경우에도 명시적으로 발생합니다.
- 이 경우 입력 영역이 언제든지 업데이트 될 수 있습니다. 입력 신호에 대한 개선 조차도 소비쪽에서는 이에 대한 진단 및 처리 비용이 많이 발생할 수 있는 유해한 영향을 줄 수 있으므로 매우 위험합니다.
- 예를 들어 이전에 사용하던 입력 신호가 잘못된 calibration 을 사용한다는 것을 깨닫고 이를 보정했다고 생각해 봅시다. 하지만 이미 이를 소비하는 시스템은 잘못된 calibration에 적합하도록 구성되어 있으며 이를 수정시 큰 영향을 미치게 됩니다.
- 이에 대한 보완 전략은 불완전한 데이터에 대한 버저닝(versioning) 관리입니다.
- 예를 들어 주기적으로 변경되는 단어 주제 클러스터가 있다고 해봅시다.
- 시간이 지남에 따라 이를 변경되도록 구성하는 대신 고정된 버전을 작성하고 새로 업데이트 될 버전을 완전히 검증한 뒤 이를 대체하는 것이 합리적일 수 있습니다.
- 물론 이러한 버전 관리는 내부적으로 부실하게 관리될 가능성이 있고 시간이 지남에 따라 동일한 신호 정보를 포함한 여러 버전을 만들어낼 수 있다는 단점이 있습니다.
- 즉, 동일한 정보를 가진 여러 클러스터가 생겨나더라도 이를 유지해야 하는 비용이 발생합니다.
활용도가 낮은 데이터에 대한 종속성 (Underutilized Data Dependencies)
- 코드 레벨에서 활용도가 낮은 종속성이 의미하는 것은 불필요한 패키지를 사용하는 것을 의미합니다.
- 데이터 관점에서 활용도가 낮은 종속성이란 모델링 관점에서 거의 이득이 없는 입력 신호를 의미합니다.
- 이로 인해 ML 시스템은 변경에 취약할 수 있으며 비록 큰 영향없이 제거 가능할 지라도 큰 문제가 되는 경우가 있습니다.
- 예를 들어 제품 코드 체계를 관리하는데 있어 이전 코드 체계에서 신규 체계로 전환을 가능하도록 기능을 제공하는 시스템이 있다고 해봅시다.
- 일단 신제품은 새로운 숫자 형태로 코드를 읽게 되지만 구형 제품은 두 정보가 존재할 가능성이 큽니다.
- 모델을 개발할 때 구형 코드를 피쳐로 활용하는 것으로 구현하는 것이 쉽습니다.
- 1년 후 구형 코드 방식은 폐기되고 ML 시스템 개발자에게는 악몽이 시작됩니다.
- 활용도가 낮은 데이터는 다음과 같이 발생합니다.
- Legacy Features
- 이게 가장 흔한 경우인데 모델 개발 초기에 사용되다가 시간이 지남에 따라 다른 피쳐에 의해 중복된 정보를 내포하게 되는 경우입니다.
- Bundled Features
- 때로는 마감 기한에 쫒겨 일단 피쳐를 다 때려 넣었더니 좋은 결과가 나온 경우입니다. 이 경우 모든 피쳐를 한번에 추가하여 실제로는 불필요한 피쳐가 포함되어질 수 있습니다.
- e-Features
- ML 연구자들이 그러는 것 처럼 실제로는 매우 적은 이득만을 주는 피쳐임에도 모두 다 모델에 포함을 시키는 경우입니다.
- Correlated Features
- 종종 두개의 피쳐가 강한 상관관계를 보이지만 그 중 하나가 좀 더 직접적인 원인이 되는 경우입니다.
- 많은 ML 방법론들이 이를 구분하기가 어렵습니다. 그냥 둘 다 선택을 하거나 아니면 직접적인 원인 대신 다른 피쳐를 선택하게 되는 경우입니다.
- Legacy Features
- 활용도가 낮은 데이터에 대한 종속성을 파악하는 방법은 철저한 평가 후 판단될 수 있습니다.
- 불필요한 기능을 식별하고 제거하기 위해서는 정기적으로 이를 실행해서 확인해야 합니다.
데이터 의존성에 대한 정적 분석 (Static Analysis of Data Dependencies)
- 전통적으로 코드 관점에서는 컴파일러와 빌드 시스템에서 의존성과 관련된 정적 분석을 수행해 줍니다.
- 하지만 데이터 의존성에 대해서는 이에 대한 도구나 경험이 부족합니다.
- 그럼에도 불구하고 오류 확인, 사용자 추적, 마이그레이션, 업데이트 시행시 이러한 분석은 필수적인 부분입니다.
- 이에 대한 도구 중 하나는 자동 피쳐 관리 시스템으로 데이터 소스와 피쳐에 대해 주석(annotated)을 표기할 수 있습니다.
- 그런 다음 자동화된 체크 과정을 통해 모든 종속성에 적절한 주석이 달려있는지를 확인할 수 있습니다.
- 이런 종류의 Tool은 실제 서비스의 마이그래이션 및 삭제 처리를 더 안전하게 수행할 수 있습니다.
- (SE 관련 논문이라 문장이 너무 추상적인데 그냥 정보를 관리할 수 있는 시스템을 구축하라는 의미같습니다.)
Feedback Loops
- 라이브 ML 시스템의 주요 기능 중 하나는 시간이 지남에 따라 업데이트가 발생하여 자체 동작에 영향을 미치게 된다는 것입니다.
- 이로 인해서 실제 모델을 배포하기 전까지는 결과에 대한 분석을 하기가 매우 어렵다는 문제가 있습니다.
- 이를 분석 부채(analysis debt)라고 부릅니다.
- 이러한 피드백 루프(feedback loops)는 여러 형태를 가질 수 있지만 시간이 지남에 따라 점진적으로 발생하기 때문에 이를 찾아내기 어렵습니다.
직접적인 피드백 루프 (Direct Feedback Loops)
- 현재의 모델은 직접적으로 미래에 사용될 새로운 모델을 위한 학습 데이터를 선택하는데 영향을 미칠 수 있습니다.
- 이를 해결하기 위해 bandits 알고리즘을 사용할 수 있지만 실제로 대부분은 지도 학습(supervised)을 사용합니다.
- bandits 알고리즘은 간단히 이야기해서 각기 다른 리워드를 가진 슬롯 머신에서 한번에 한 슬롯 머신에서만 돈을 빼 갈수 있는 도적이 H 시간 후에 최종 보상을 최대화하는 문제입니다.
- 여기서 문제는 bandits 알고리즘이 실제 문제에서 요구되는 액션 공간만큼 확장하기 어렵다는 것입니다.
- 보통 랜덤 값을 이용하거나 모델 영역 중 확실한 부분은 따로 분리해서 복잡도를 줄입니다.
- (이것도 너무 추상적이라 이해하기 어려운 부분이 있는데 사실 별로 중요한 부분은 아닌 것 같습니다.)
숨겨진 피드백 루프 (Hidden Feedback Loops)
- 직접적인 피드백 루프는 분석 비용이 꽤 들지만 ML 연구자들이 자연스럽게 연구할 수 있는 통계적 도전 과제를 제시합니다.
- (그냥 분석하긴 어렵지만 할려면 할 수있다고 설명하면 될텐데 말이 참 어렵습니다.)
- 이것보다 더 어려운 상황은 두개의 시스템이 간접적으로 서로에게 영향을 미치는 숨겨진 피드백 루프입니다.
- 하나의 예를 들면,
- 각기 다른 두 시스템이 독립적으로 웹 페이지의 패싯을 결정하는 경우 한쪽이 시스템을 변경하면 다른 쪽의 결과가 달라질 수 있습니다.
- 사용자가 변경에 반응하여 클릭이 달라집니다.
- (그냥 이것도 애매한 내용인데 단순히 생각해보면 서로의 출력값이 상대방의 입력값이 될 수 있다는 의미입니다.)
- 이 숨겨진 루프는 완진히 분리된 시스템에서 발생할 수 있습니다.
- 완전히 다른 두 투자회사가 주식 예측 프로그램을 각기 내어놓았다고 해봅시다.
- 이 중 한 쪽이 성능을 개선하는 경우 (아니면 끔찍한 버그를 내포했거나) 이것이 구매로 이어져 다른 회사의 모델에 영향을 주게 됩니다.
- 의도하지 않아도 두 시스템이 영향을 미치게 되는 현상을 생각하면 됩니다.
ML 시스템의 안티 패턴들 (ML-System Anti-Patterns)
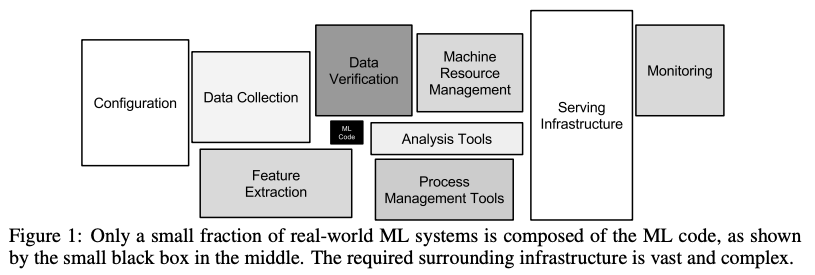
- 실제 ML 시스템 영역에서는 아주 작은 부분의 코드만이 실제 학습(training)이나 추론(inference)을 담당합니다.
- 불행하게도 ML 시스템은 부채가 많을 수밖에 없는 디자인 패턴으로 끝나게 됩니다.
- 이 섹션에서는 ML 시스템에 흔히 보여지는 안티 패턴을 기술합니다.
접착 코드 (Glue code)
- ML 연구자들은 독립된 패키지 형식으로 솔루션을 개발하는 경향이 있습니다.
- 이 때 다양한 오픈소스 패키지를 사용하게 되는데 이런 경우 접착코드 패턴이 생겨납니다.
- 특히 데이터 입출력시 막대한 양의 지원 코드가 생겨나기 쉽습니다.
- 접착제 코드는 코드를 특정 패키지만을 사용하도록 고정시키는 경향이 있기 때문에 장기적으로는 비싼 비용을 치르게 됩니다.
- 일반화된 패키지를 도입하면 목적 함수 조절이 어려워지기 때문에 개선점 적용이 어려울 수 있습니다.
- 이미 성숙된 시스템은 최대 5% ML 코드와 95% 정도의 접착 코드가 구성될 수 있습니다.
- 따라서 일반적인 패키지를 선호하는 것 보다 깨끗한 상태의 기본 솔루션을 만드는게 비용을 줄일 수 있습니다.
- (사실 이해는 잘 되지 않습니다. 진짜 이런지)
- 접착 코드를 줄이는 방안은 블랙박스 스타일의 패키지들을 API 로 한번 감싸는 것입니다.
- 이를 통해 재사용성을 높이고 패키지 변경 비용을 줄일 수 있습니다.
파이프라인 정글 (Pipeline Jungle)
- 접착코드의 특별한 경우로 파이프라인 정글을 고려할 수 있습니다.
- 보통 데이터 전처리 과정에서 발생하는데 새로운 시그널(입력 정보)이 포착되고 이를 추가함에 따라 이들은 유기적으로 발전됩니다.
- 이 때 주의를 기울이지 않으면 중간 파일 생성, 스크랩, 조인, 샘플링 등 어러 정글(jungle)을 만들어 낼 수 있습니다.
- 이런 파이프라인 관리 및 오류 감지, 장애 복구 비용은 매우 비쌉니다.
- 이런 파이프라인을 테스트하려면 비용이 높은 엔드 투 엔드 통합 테스트가 필요합니다.
- 이 모든 것이 시스템의 기술적 부채를 증가시킵니다.
- 파이프라인 정글 문제는 데이터 수입 및 추출에 대해 전체적으로 조망해야만 피해갈 수 있습니다.
- 파이프라인 정글을 폐기하고 처음부터 다시 설계하는 방식은 투자 비용이 높지만 전체 지속되는 비용을 줄이고 혁신을 가속화할 수 있는 방법입니다.
- (깔끔하게 밀고 다시 만드는게 좋다는 말이 참 마음에 드네요)
- 접착 코드 및 파이프라인 정글은 “연구” 파트와 “엔지니어” 파트가 분리되었을 경우 발생하는 증상 중 하나입니다.
- 연구원과 엔지니어가 함께 하이브리드 방식으로 연구하면 이런 문제를 줄이는데 도움이 됩니다.
죽은 실험 코드 (Dead Experimental Codepaths)
- 접착 코드, 파이프라인 정글의 일반적인 결과는 단기적으로 주요 생성 코드가 조건부 분기로 실험되어진다는 것입니다.
- 개별적인 변경의 경우 이런 식으로 실험하는게 상대적으로 비용이 낮으므로 특별히 다른 인프라 수정이 필요 없습니다.
- 그러나 시간이 지남에 따라 이런 변경은 이전 버전과의 호환성을 유지하기 어렵게 만들고 순환 복잡성이 기하급수적으로 증가합니다.
- 결국 코드 경로간의 모든 상호 작용을 테스트하기가 불가능합니다.
- 이 예시 중 가장 유명한 일화는 45분만에 4억6천6백만 달러의 손실을 본 Knight Capital 시스템입니다. (관련 내용은 논문 링크를 참고합시다)
- 일반적인 소프트웨어 개발시 실행하는 데드 플래그(dead flag) 제거 방식과 같이 주기적으로 실험용 브랜치를 없애는 작업을 수행해야 합니다.
- 실제로는 여러 실험 브랜치 중 몇 가지만이 실제 사용 가능성이 있습니다.
- 그 외에는 대부분 버려지는 코드임을 명심하세요.
추상화 부채 (Abstraction Debt)
- 이 문제는 ML 시스템을 지원할 수 있는 강력한 추상화 기능이 없다는 사실을 강조합니다.
- Zheng 의 연구에 따르면 ML 추상화의 정도를 DB 시스템과 비교했을 때, 어떠한 ML 시스템도 DB에서 성공한 추상화 시스템을 적용하기에 적합하지 않다는 것을 확인하였습니다.
- 실제 데이터 스트림, 모델, 추론을 표현할 수 있는 적절한 인터페이스는 무엇일까요?
- 특히 분산 학습을 위한 ML 추상화 모델은 존재하기나 할까요?
- 가장 널리 알려진 분산 알고리즘인 MR(MapReduce) 방식이 ML에서 자주 활용되는 이유가 사실은 강력한 분산 학습 추상화가 존재하지 않기 때문이라는 시각도 있습니다.
- 실제로 몇년간 논의된 합의점 중 하나는 MR이 반복적인 ML 알고리즘에 대한 잘못된 추상화라는 것입니다.
- 파라미터 서버(Parameter-server) 방식은 강력해 보이지만 기본 아이디어에 대한 경쟁 사항(?)들이 존재합니다.
- 표준화된 추상화가 없기 때문에 구성 요소를 구분하는 것이 부족합니다.
- (안타깝게도 오래된 논문이라 분산 학습 관련해서는 Parameter-Server 방식밖에는 언급이 없습니다.)
흔한 냄새 (Common smell)
- 소프트웨어 엔지니어링에서는 시스템이나 컴포넌트에 존재하는 문제들을 냄새(smell)로 표현합니다. (심한 경우 악취라고 하지요)
- 여기서는 ML 시스템에서 발생 가능한 냄새를 정의합니다.
POD 타입 냄새 (Plain-Old-Data Type Smell)
- ML 시스템에서 사용되는 정보는 모두 POD 타입의 정수나 실수로 인코딩됩니다. (POD는 원래 전산학에서 사용되고 있는 단어입니다.)
- 강건한 시스템에서는 모델 파라미터가 로그 승수 값인지 경계 바운더리를 위한 값인지 알고 있어야 합니다.
- 예측 값 또한 하나의 정보로서 이를 어떻게 사용할 수 있는지에 대한 정보를 알고 있어야 합니다.
- (말이 어려운데 ML 모델들이 너무 저수준의 자료형을 사용한다는 의미 같네요. 그래서 별도의 메타 정보를 항상 유지하고 활용해야 합니다. 레이블 파일이라던지 등)
다중 언어 냄새 (Multiple-Language Smell)
- 제공된 언어로 시스템의 특정 부분을 구현하려는 경우가 많습니다. (컴퓨터를 위한 언어를 의미합니다.)
- 특히 해당 언어에 특화된 편리한 라이브러리나 구문 등이 제공될 때 더욱 그러합니다.
- 하지만 여러 언어를 혼용해서 사용하면 테스트 비용이 증가하고 서비스 이전시 어려움을 겪게 됩니다.
프로토타입 냄새 (Prototype Smell)
- 프로토타입으로 새로운 아이디어를 구현하고 테스트하는 것은 편리합니다.
- 그러나 프로토 타이핑을 기본으로 의존하는 것은 시스템 취약성을 늘리고 변경이 어렵게 합니다.
- 사실 개선된 추상화 및 인터페이스가 필요하다는 신호일 수 있습니다.
- 프로토타이핑 환경을 유지 관리하는데 비용이 추가되며 시스템 오픈 시간 압력이 들어오는 경우 프로토타이핑 시스템이 실제 솔루션으로 사용될 수 있는 심각한 위험이 있습니다.
- 소규모 환경을 염두해 둔 프로토타이핑은 실 세계 환경을 거의 고려하지 못합니다.
설정 부채 (Configurations Debt)
- 여기서 설정이란 프로그램 실행시 사용되는 옵션 값을 의미하는 것입니다.
- 부채가 축적될 수 있는 다른 분야는 설정(configuration) 영역입니다.
- 대형 시스템에는 사용되는 기능, 데이터 선택, 다양한 학습 옵션, 암묵적인 전처리, 검증 방법 등 다양한 영역에서 설정 정보를 사용하게 됩니다.
- 연구원과 엔지니어는 보통 설정 정보에 관련된 내용(개발)들을 나중으로 미룹니다.
- 그리고 실제로 설정 정보의 검증 또는 테스트는 최종 결과에 중요하지 않을 수도 있습니다.
- 성숙한 시스템에서의 설정 정보의 코드 수는 실제 구동 코드보다도 더 많을 수 있습니다.
- 이 경우 각 설정 정보에는 실수가 있을 가능성이 높습니다. (코드 라인이 길기 때문에요).
- 예를 들어 봅시다.
- 피쳐 A 가 실수로 9/14~9/17 사이에 잘못 기재되었습니다.
- 피쳐 B 는 10/7 까지는 사용 불가입니다.
- 피쳐 C 는 로깅 형식 변경으로 인해 11/1 전후 데이터에 대해 변경되어야 합니다.
- 피쳐 D 는 현재 프로덕션 레벨에서 사용할 수 없기 때문에 D’ 및 D’’ 로 대체되어야 하빈다.
- 피쳐 Z 를 사용하고자 할 경우 조회 테이블로 인해 추가 메모리가 필요합니다.
- 피쳐 Q 는 대기 시간 제약 때문에 기능 R을 함께 사용할 수 없습니다.
- 이런 제약점들로 인해서 설정을 올바르게 수정하기 어렵습니다.
- 설정 오류로 인해 작업 시간이 많이 소요되고 리소스가 낭비되는 경우가 흔합니다.
- (예제가 참 별로입니다.)
-
우리는 다음 원칙을 통해 명확한 설정 시스템을 설명합니다.
- 필수 조건
- 설정을 이전 설정에서 약간 변경하여 쉽게 지정할 수 있어야 합니다.
- 수동 오류, 생략, 누락 등을 어렵게 해야 합니다.
- 두 모델 사이의 설정 차이를 쉽게 확인할 수 있어야 합니다. (시각적으로)
- 자동으로 Assert 되어야 하고 기본적인 값들을 체크해야 합니다.
- 사용되는 피쳐의 갯수나 데이터에 순환이 발생하지 않는지 등이 자동으로 체크되어야 합니다.
- 사용하지 않거나 중복된 설정값을 자동으로 감지할 수 있어야 합니다.
- 구성은 전체 리뷰를 통해 머지되어야 합니다. (전체 구성원이 숙지)
외부 세계의 변화를 다루어야 합니다. (Dealing with Changes in the External World)
- ML 시스템이 매혹적인 이유는 종종 외부 세계와 직접적인 상호 작용을 수행한다는 것입니다.
- 경험적으로 외부 세계는 불안정하기 때문에 이에 대한 변경을 지속적으로 확인하여 변경해야 합니다. 이에 대한 유지 비용이 발생합니다.
동적인 시스템에서의 고정된 임계치 (Fixed Thresholds in Dynamic Systems)
- 특정 모델에 대한 고정된 결정 임계 값을 선택할 경우가 존재합니다.
- 예를 들어 참/거짓 예측, 스팸 여부, 광고 표시 여부 등을 고려할 수 있습니다.
- 전통적인 ML 의 접근 방법은 정확도와 리콜 사이의 Metric 에 대해 적절한 균형을 찾는 방안을 모색하는 것이었습니다.
- 하지만 많은 경우 이 값은 수동으로 설정됩니다.
- 따라서 새로운 모델로 업데이트 되면 이 값은 더 이상 유효하지 않은 값이 됩니다.
- 많은 경우 이 값을 수동으로 유지하는 것은 업데이트시 많은 비용이 소요되고 깨어지기 쉽습니다.
- 이를 위한 전략들이 존재하며 이 전략들은 검증된 데이터를 통해 임계 값을 학습하는 것을 제시합니다.
모니터링과 테스트 (Monitoring and Testing)
- 개별 구성 요소에 대한 단위 테스트와 엔드 투 엔드 테스트는 가치가 있지만 외부 데이터와 연동중인 시스템에서는 이러한 테스트가 의도적으로 동작한다는 것을 모두 반영하기에는 충분하지 않습니다.
- 실시간 시스템 동작에 대한 포괄적인 모니터링 시스템은 장기적인 관점에서 매우 중요합니다.
- 여기에서 핵심 질문은 “과연 무엇을 모니터링해야 하는가?” 입니다.
- 많은 ML 시스템이 시간이 지남에 따라 변경될 수 있다는 것을 고려하면 테스트 가능한 불변성은 가능하지 않습니다.
- 우리는 다음과 같은 출발점을 제시합니다.
예측 바이어스 (Prediction Bios)
- 의도한 바대로 동작하는 시스템은 예측된 레이블 분포와 실제 레이블 분포가 동일해야 합니다.
- 반면 단순하게 실제로 발생할 수 있는 입력 데이터와 상관 없이 널모델(입력 가능한 모든 범위를 포함하는) 레이블에 대한 평균값을 예측하는 방법은 정석은 아닙니다.
- 하지만 이 방법은 놀랍게도 유용한 진단법이며 갑작스럽게 변경되는 외부 환경에 대한 감지를 수애합니다.
- 이를 자동 경고에도 활용할 수 있습니다.
- (말이 어려운데 그냥 간단히 생각해보면 입력 값의 가용 범위 내에서 대량의 랜덤값을 발생하여 테스트하고 출력의 평균값을 alarm 으로 사용할 수도 있다는 의미같네요)
행동 제약 (Action Limits)
- 입찰을 한다거나 스팸을 체크하는 등 실제 환경에서 사용되는 시스템에서 처리에 대한 제한값을 설정할 수 있습니다.
- 이 값은 False Alarm 을 발생시키지 않을 정도로 넓은 범위를 가져야 하고 이 값에 도달하면 자동 경고가 발생하게 하여 수동 개입을 하거나 조사를 수행할 수 있도록 해야 합니다.
업스트림 제공자 (Up-stream Producers)
- 데이터는 종종 업스트림 생산자로부터 수급되게 됩니다.
- 이 과정의 프로세스는 철저한 모니터링, 테스트 및 요구사항 만족을 위한 시스템 구축이 마련되어 있어야 합니다.
- 또한 모든 데이터에 대한 알람은 ML 시스템의 정확성을 보장하기 위해 제어 영역(control plane ??)으로 전파되어야 합니다.
- 또한 ML 시스템이 실패할 경우 이를 사용하는 모든 사용자에게 빠르게 전파되어야 합니다.
- 이 또한 각각의 제어 영역(control plane)으로 전파되어야 합니다.
외부 세계의 변화 정리
- 외부의 변경은 실시간으로 발생하기 때문에 응답 또한 실시간으로 대응되어야 합니다.
- 경고에 대한 응대는 사람의 개입에 의존하는 것이 보통의 전략이지만 시간에 민감한 문제에는 취약합니다.
- 이 경우 자동화된 대응을 가능케 하는 시스템을 만드는 것은 투자할 가치가 있습니다.
다른 영역에서의 ML 관련 부채 (Other Areas of ML-related Debt)
- 추가적인 영역에서 발생하는 부채에 대해 다룹니다.
데이터 테스트 부채 (Data Testing Debt)
- ML 시스템에서 데이터가 코드를 대체하고 이 코드는 테스트되어야 한다고 할 때 테스트를 위한 데이터를 구축하고 이를 이용하여 테스트를 하는 것은 명확해 보입니다.
- 하지만 이 방식은 기본적인 체크는 유용하지만 복잡한 테스트에서는 결과를 확인하기 어렵습니다.
- (그래서 어쩌라는건지…)
재현성 부채 (Reproducibility Debt)
- 과학자의 입장에서 실험을 재실행하고 유사한 결과를 얻을 수 있는 것은 중요합니다.
- 하지만 엄격한 재현성을 허용하는 시스템을 설계하는 것은 불가능합니다.
- 무작위 알고리즘, 병렬 학습, 비결정성, 초기 조건에 대한 의존성 등
프로세스 관리 부채 (Process Management Debt)
- 여기서 설명하는 사용 사례는 단일 모델을 유지 관리하는 비용을 의미하지만,
- 성숙한 시스템에서는 수십 또는 수백개의 모델이 동시에 실행됩니다.
- 이를 통해 많은 유사 모델이 안전하게 자동 업데이트되고 리스스 관리 및 할당하는 방법, 데이터 흐름을 시각화하고 감지하는 방법이 중요한 이슈로 떠오릅니다.
- 생산 파이프라인, 장애 시 복구를 위한 Tool 개발도 중요합니다.
- 여기서 가장 피해야 할 냄새(smell)는 장애시 수동 복구를 진행해야 하는 단계를 놓아두는 것입니다.
문화적 부채 (Cultural Debt)
- 연구자와 엔지니어의 차이점에 의해 발생합니다. 연구자는 모델 품질을, 엔지니어는 시스템을 우선시 하게 되니까요.
결론
- 기술 부채는 괜찮은 은유법이지만 명확한 지표를 제시하는 것은 아닙니다.
- 어떻게 기술 부채를 측정하거나 평가해야 할까요?
- 팀이 빠르게 돌아간다는 점을 확인하는 것이 기술 부채가 적은 상태라고 말할 수는 없습니다.
- 대신 부채의 전체 비용은 시간이 지남에 따라 명확하게 드러나기 마련입니다.
- 오히려 빠르게 움직이는 것이 기술 부채를 더 많이 만들어내는 것일 수도 있습니다.
- 따라서 이에 대한 적합한 질문은 다음과 같습니다.
- 완전히 새로운 알고리즘에 대해 조직 내에서 전체 규모로 얼마나 쉽게 테스트가 가능합니까?
- 모든 데이터 종속성에 대한 transitive closure 는 무엇입니까?
- 시스템에 적용하는 새로운 변경에 대해 얼마나 정확하게 그 영향도를 측정할 수 있습니까?
- 한 모델이나 입력을 개선하면 다른 모델이나 입력 값이 향상되어집니까?
- 팀의 신입 사원이 업무에 얼마나 빨리 적응할 수 있나요?
- 이 논문을 통해 더 좋은 추상화, 테스트 방법이 나오기를 희망합니다.
- 가장 중요한 통찰력은 ML 영역에서 연구자와 엔지니어가 모두 기술 부채가 무엇인지를 알아야 한다는 것입니다.
- 어떤 연구 솔루션이 아주 적은 성과만을 가지지만 시스템의 복잡도가 크게 증가하는 경우가 생긴다면 이는 결코 좋은 솔루션이 아닙니다.
- 문제가 없어 보이는 데이터를 하나, 두개만 추가해도 업무 진행 속도가 극적으로 느려질 수 있습니다.
- ML 기술 부채를 상환하려면 별도의 노력이 필요하며 이는 팀 문화의 변화에 의해서만 달성될 수 있습니다.
- 성공적인 ML 팀이 되기 위해서는 이러한 노력은 인식하고 우선 순위를 정하고 업무를 진행하는 것이 중요합니다.