(급하게 읽고 정리한 것입니다. 오역을 확인 못했어요)
- Transfer Learning 은 이미지 분야에서 널리 사용하고 있는 방법론이다.
- pre-trained 모델을 이용해서 fine-turning 하는 방식을 의미한다.
- 이 논문에서는 어떤 데이터를 선택해야 최종적으로 얻고자 하는 결과가 좋아지는지를 확인한다.
- 따라서 가장 중요한 포인트는 어떤 pre-trained 모델을 선택하는가?
- 결국 backbone 학습을 위해 어떤 데이터를 사용해야 가장 좋은지를 확인해본다.
(참고)
- ICLR2019 에 제출되었다 철회되었다.
- 리뷰가 호의적이지 않았음.
- 그리고 아카이브에 v2 가 올라옴.
Introduction
- 이미지 분야에서는 pre-training 데이터로 주로 ImageNet 과 같은 대량의 데이터집합을 활용한다.
- 이를 통해 기본적인 모델을 학습한 뒤 마지막 layer 만 변경하여 원하는 도메인의 데이터로 fine-tuning 작업을 수행한다.
- 이러한 방식은 매우 성공적이었으며 object detection, segmentation, object recognition 등 다양한 분야에서 활용된다.
- 보통 ImageNet 데이터로 학습된 네트워트를 시작점으로 사용하면 원하는 모델을 보다 빠르게 수렴하게 할수 있고 학습 시간을 많이 단축시킬 수 있다.
- 이런 이유로 대부분의 학습에서는 기본적으로 ImageNet 데이터를 활용하여 만든 pre-trained 모델 만을 base 모델로 간주한다.
- 하지만 이 논문에서는 더 나아가 fine-tuning 모델에 사용할 기본 모델의 데이터 집합으로 어떤 것을 선택하면 좋은지 알아본다.
- 이 문제를 고찰해보기 위해 다음과 같은 상황을 고려해본다.
- 먼저 실제로 원하는 문제(task)는 음식(food) 분류같은 FGVC 문제이다. (입력 이미지가 ‘핫도그’인지 ‘햄버거’ 인지 등을 구별하는 문제)
- FGVC 는 fine-grained visual classification 의 준말로 세부 분야에서의 분류 문제를 다룬다.
- Transfer learning 를 활용하는데 있어 ImageNet 데이터를 사용한다.
- 먼저 실제로 원하는 문제(task)는 음식(food) 분류같은 FGVC 문제이다. (입력 이미지가 ‘핫도그’인지 ‘햄버거’ 인지 등을 구별하는 문제)
- 그런데 여기서 궁금함이 생긴다.
- ‘개’ 와 ‘고양이’ 를 구분하는 ImageNet 모델이 ‘핫도그’와 ‘햄버거’를 구별하는데 정말 도움이 되는 것일까?
- 아니면 pre-trained 모델에서도 음식과 관련된 데이터만을 선별하여 학습한 뒤 fine-tune 을 하는 것이 더 좋지는 않을까?
성질 급한 분들을 위한 정답 요약
- 단지 pre-training 학습 데이터가 크다고 해서 target task 결과에 더 도움이 되는 것은 아니다.
- 즉, 더 많은 데이터가 더 좋은 결과를 가져오는 것이 아니다.
- 오히려 fine-turning 하는 데이터와 연관이 없는 데이터는 가급적 제외하는 것이 최종 결과에 도움이 된다.
- FGVC 에서 두드러지게 나타남
- pre-training 데이터의 분포를 target dataset 분포에 맞추면 더 결과가 좋다.
- 이를 적용하기 위한 간단한 방법을 뒤에서 자세히 살펴볼 것이다.
- FGVC에서는 pre-trained 모델도 FGVC 로 학습해야 한다.
- 큰 데이터 집합을 다 사용하지 말고 선별해서 사용해야 한다.
- Transfer learning 의 성능은 pre-training 데이터에서 얼마나 target 과 비슷한 이미지에 대한 정보를 추출할 수 있는지가 관건.
Transfer learning 환경 세팅
- 실제 사용한 pre-training 데이터 집합은 ImageNet 과 JFT.
- JFT 는 구글이 내부적으로 사용하고 있는 이미지 학습 데이터이다.
- 구글 논문 등에서 JFT 와 관련된 발표는 오지게 하는데, 실제 데이터가 공개된 적은 없다.
- 스펙상 Google OpenImage 와는 조금 다르다. 아마도 서로 다른 조직에서 사용하는 데이터인듯.
- JFT 는 구글브레인, OpenImage 는 구글 이미지 검색 쪽인듯. 뇌피셜임
- 스펙상 Google OpenImage 와는 조금 다르다. 아마도 서로 다른 조직에서 사용하는 데이터인듯.
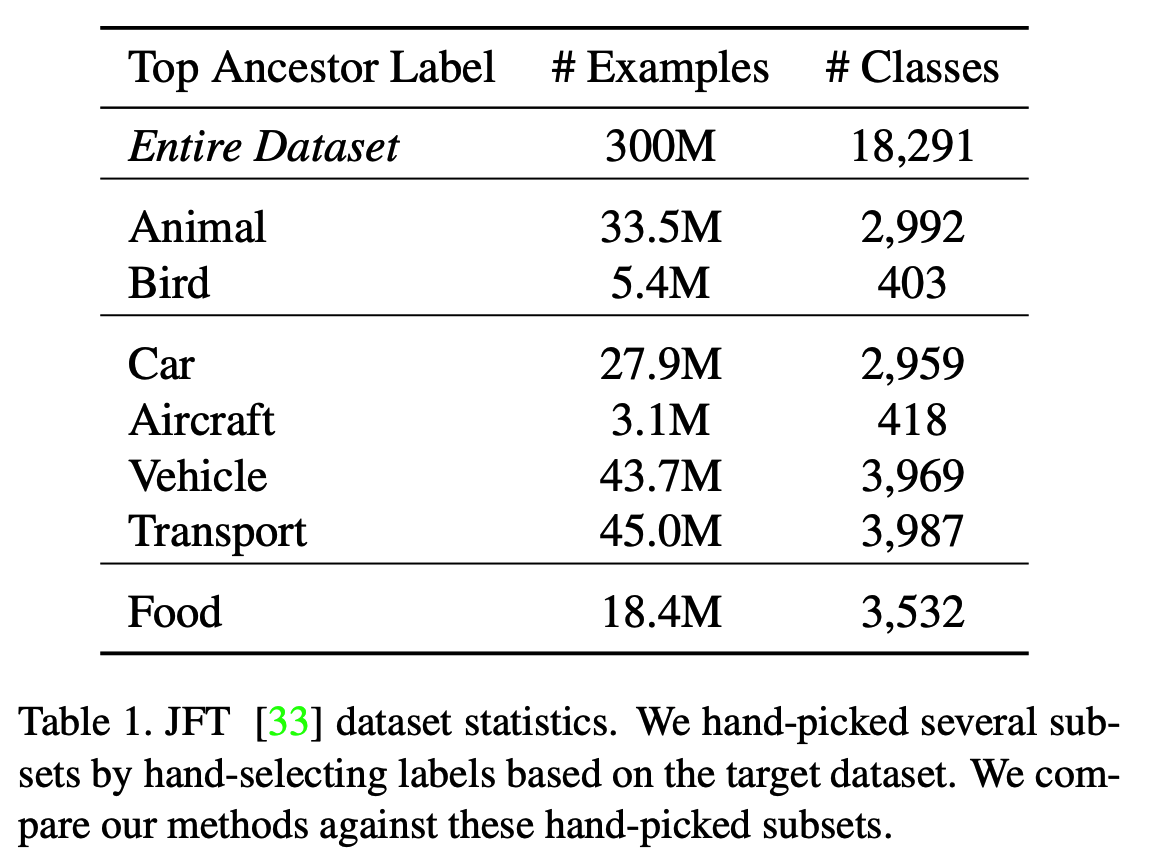
- JFT
- 3억개의 이미지와 18,291개의 클래스 레이블로 구성
- 참고로 ImageNet-ILSVRC-2012는 120만개, OpenImage는 약 900만개 이미지.
- 모든 이미지는 multi-label 구조 (이건 오픈이미지와 비슷하다.)
- 이미지마다 평균 1.26개의 label 이 있다.
- fine-grained label이 다량 포함되어 있다.
- 예를 들어 1,165개의 label 이 동물(animal)에 속함
- 의미론적인 계층구조(hierarchy)가 존재한다.
- 예를 들어 ‘model of transport’ » ‘vihicle’ » ‘car’
- 하지만 이러한 계층 구조를 활용하여 하위 레이블을 만드는 것은 제약이 존재한다.
- (a) 레이블 당 예제 수는 JFT 에 미리 정해져 있다.
- (b) 모든 하위 레이블이 관련성 있는 것은 아니다.
- (c) 계층 구조의 서로 다른 하위 트리에 대한 결합이 존재할 수도 있다.
- (d) 포함된 모든 레이블들이 충분히 다른 계층과 연관을 맺고 있는 것은 아니다.
- 3억개의 이미지와 18,291개의 클래스 레이블로 구성
- 우리는 다음의 데이터를 이용하여 fine-tuning 을 시도해본다.
- 이 때 전처리로 JFT 이미지에 target 학습데이터 내 이미지가 같거나 너무 비슷한 이미지가 있었다면 JFT 에서 모두 제거.
Domain adaptive transfer learning (importance weighting)
- 여기서는 domain-adaptive 방식의 transfer-learning 에 대해 살펴본다.
- 이 방법은 pre-training 과정 중 예제에 가중치를 넣을 수 있는 아주 간단한 방법이다.
- 일단 간단하게 살펴보기 위해 source와 target 이 동일한 데이터 집합 \((x, y)\)라고 생각해보자.
- 여기서 source 는 pre-training 을 과정을 의미하고 target 은 fine-tuning 과정을 의미.
- 즉, source dataset은 ImageNet, JFT 같은 데이터집합을 의미한다.
- 이렇게 가정하면 \(y\) 에 대해서 source와 target 의 레이브도 동일하다는 가정이 들어간다.
- 여기서 source 는 pre-training 을 과정을 의미하고 target 은 fine-tuning 과정을 의미.
- \(D_s\) : source dataset
-
\(L\) 은 보통 cross entropy loss 를 사용한다.
- 현실에서는 \(D_s\) 와 \(D_t\) 는 동일하지 않다.
- 여기서는 target data 와 비슷한 source 의 이미지들에 대해 가중치를 부여하는 방식을 취한다.
- 이 방식은 흔히
taget shift라고 알려져있는prior probability shift기법과 유사하다.
- 여기서 \(P_s\) 와 \(P_t\) 는 각각 source 와 target 의 확률 분포를 의미한다.
- 식을 약간 바꿔보자.
- 이 식에서 만약 \(P_s(x|y) \approx P_t(x|y)\) 라고 가정해보자.
- 이 말은 레이블 이 주어졌을 때의 source와 target 의 분포가 같다는 의미가 된다.
- 실제 현실에서도 이러한 가정이 타당하다고 확인되었다.
- 예를 들어 큰 데이터 집합에서 ‘불독’ 이미지의 분포는 동물 이미지를 모은 데이터 내의 ‘불독’ 분포와 실제 비슷할 것이다.
- 직관적으로 \(P_t(y)\) 는 target 데이터 집합의 분포를 나타내고 \(P_t(y)/P_s(y)\)는 해당 class의 reweights 요소라고 생각하면 된다.
- 따라서 \(P_t(y)/P_s(y)\) 를 importance weight 로 생각할 수 있다.
- 이런 방식을 Domain Adaptive Transfer Learning 이라 한다.
- 이 방식을 실제 적용하기 위해서는 가장 먼저 했던 source 와 target 의 레이블 공간이 같다는 제약 조건을 완화해야 한다.
- 목표는 source 데이터에 있는 모든 레이블에 대해 \(P_t(y)/P_s(y)\) 를 구성해야 한다는 것.
- 물론 source 와 target 는 서로 다른 레이블이 존재.
- 여기서 제시하는 방법은 source 레이블에 대해 \(P_t(y)\) 와 \(P_s(y)\) 를 모두 구하는 것
- 따라서 \(P_t(y)\) 를 추정(estimate)해야 할 필요가 있다.
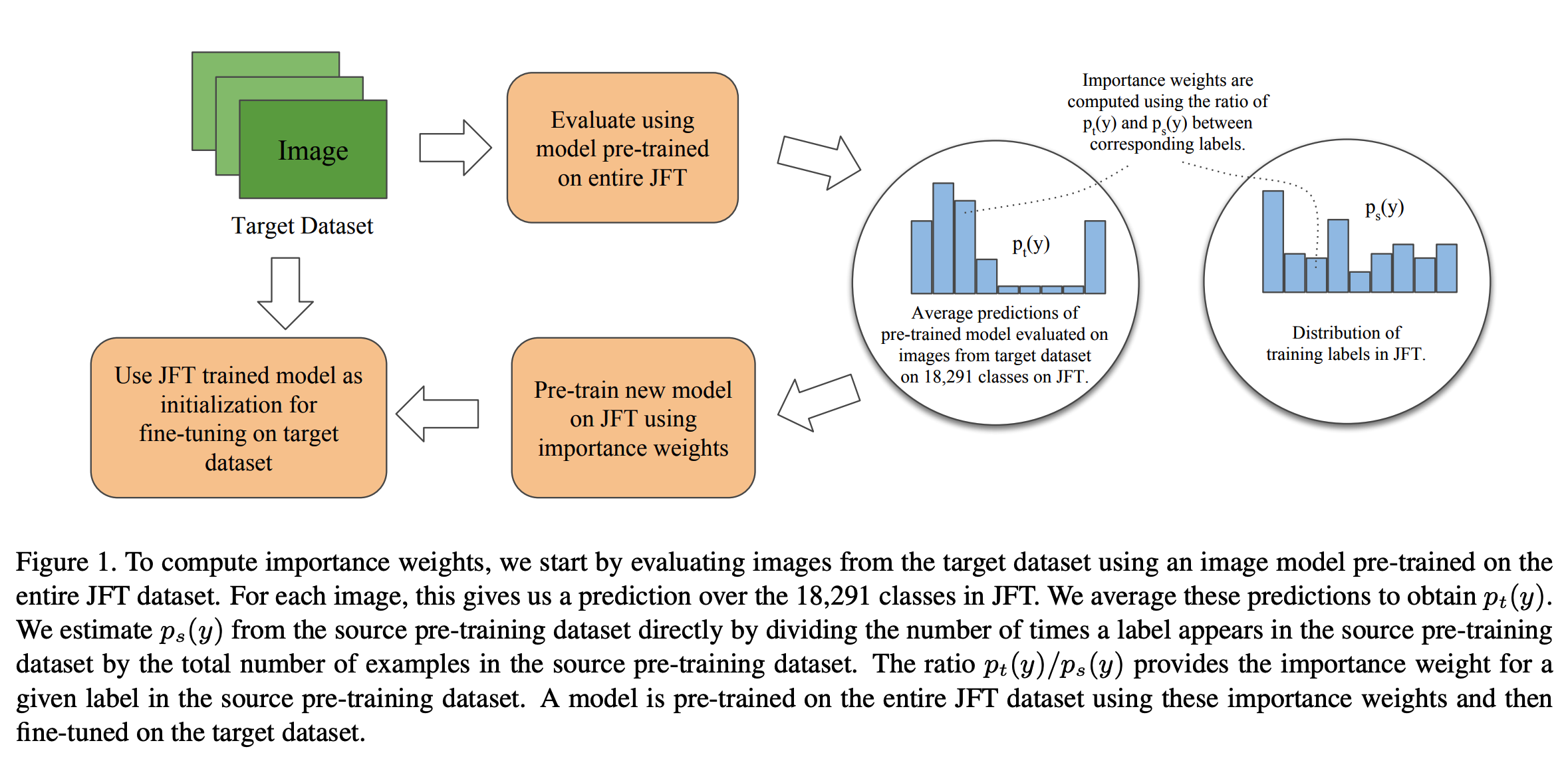
- 먼저 source 데이터로 분류 모델을 학습한다.
- 다음으로 target 데이터 집합으로 이 모델을 돌려 분류 결과를 얻어낸다.
- 예측값에 대한 평균 값을 예측하게 된다.
- 이 방법으로 \(P_t(y)\) 값을 만들 수 있다.
- 이 방법을 사용하면 target 의 레이블 을 고려할 필요 없이 \(P_t(y)\) 를 얻을 수 있게 된다.
실험 (Experiments)
- 이 실험에서는 Inception.V3 와 AmoebaNet-B 를 사용하였다.
- Inception.V3
- random-init. 로 2,000,000 step 을 돌렸다. (SGD & Nesterov momentum)
- Batch 크기는 1,024
- 동일한 weight regularization & lr 을 사용 (linear ramp-up 과 cosine-decay 를 사용)
- AmoebaNet-B
- ranodm-init. 로 250,000 step 을 돌렸다. (SGD & Nesterov momentum)
- Batch 크기는 2,048
- 동일한 weight regularization & lr 을 사용
- AmoebaNet-B 설정을 사용 (N=18, F=512)
- FC(fine-tuning) 단계
- random init.
- 20,000 step. (SGD w/ momentum)
- 256 batch
- 초기 2,000 step 은 linear ramp-up (then, cosine decay)
- 추가로 레이블 smoothing 을 넣으면 성능이 올라가는 것을 확인. (\(P_t(y)\) 에 대해)
- 자세한 내용을 레이블 smoothing 을 참고 (temperature 는 2.0 사용)
Pre-training setup
- Importence weight 값을 가지고 다시 pre-training 을 할 수 있지만 그렇게 안 함.
- 큰 데이터에서 batch 작업시 많은 예제가 존재하는 weight 쪽으로 skew 되는 현상이 있다.
- 설명이 좀 이상한데 보통 큰 데이터 집합에서는 특정 레이블의 이미지가 과하게 많다.
- 이런 경우 학습시 weight 쏠림 현상이 생겨난다.
- 또 weight 가 매우 작은 예제들은 아주 작은 gradient 를 가지기 때문에 학습에 기여를 거의 못함.
- 큰 데이터에서 batch 작업시 많은 예제가 존재하는 weight 쪽으로 skew 되는 현상이 있다.
- 위와 같은 문제로 인해 impotance weight 를 바탕으로 데이터들을 sampling 함.
- 최종 8천만건의 JFT 데이터와 200만건의 ImageNet 데이터를 구축함.
- 동일한 데이터를 Inception.V3 모델과 AmoebaNet-B 에 대해 실험
Transfer learning 결과
- 결과를 살펴보도록 하자.
(1) Domain Adaptive Transfer Learning 이 좋다.
불만있어요? Google로 오십시오. I also D.A.T.L 좋아.
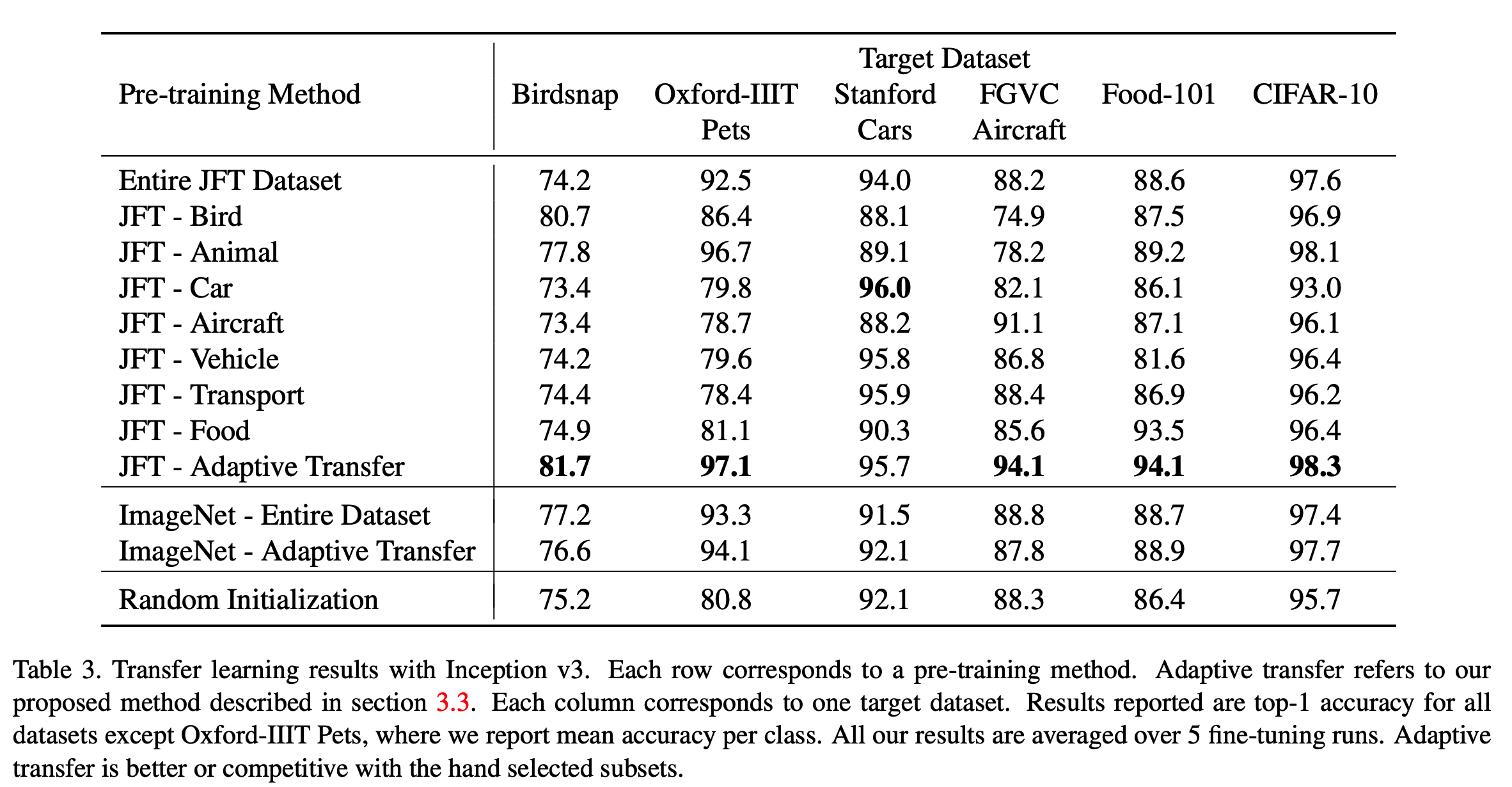
- Domain 이 비슷한 경우 결과가 좋다.
- Domain 이 완전히 다른 경우 성능이 많이 하락한다. (JFT-Bird 와 JFT-Cars 를 보자)
(2) 더 많은 데이터가 꼭 필요한 것은 아니다.
- 놀랍게도 데이터가 더 큰 경우 Transfer Learning 시 성능이 더 저하될 수 있다.
- 모든 경우 JFT로 학습한 pre-trained 모델은 특정 카테고리만을 추출하여 학습한 모델보다 성능이 안 좋았다.
- 일반적인 통념상 pre-training 데이터가 더 많을수록 성능이 향상된다고 생각되어지는데 실제로는 그렇지 않다.
- 대신 target 데이터와 관련있는 데이터를 얼마나 더 선별하는가를 판단하는게 매우 중요하다고 확인되었다.
- Adaptive Transfer 학습에서는 이게 더 두드러진다.
- ImageNet 결과를 보면 Adaptive Learning 을 위해 추출한 ImageNet 의 학습 데이터는 약 45만개.
- 즉, 120만개의 전체 데이터에 비해 절반도 되지 못하는 데이터로 학습했는데도 전체적인 성능이 더 낫다.
(3) Domain adaptive transfer가 더 효율적이다.
- JFT 와 ImageNet 을 사용하여 pre-training 을 수행할 때 레이블을 선별하여 학습하는 것보다 Adaptive Transfer 하는 것이 성능이 더 좋다.
- CIFAR-10의 경우 ‘동물’(animal)과 ‘차’(car) 가 모두 포함되어 있다.
- 이 데이터의 결과를 보면 상이한 카테고리를 포함하고 있는 데이터에 대해서도 잘 학습이 되는 것을 확인할 수 있다.
- 다음으로 ImageNet 을 사용한 모델에서 각 target class 의 importance sampling 결과를 출력해 보자.
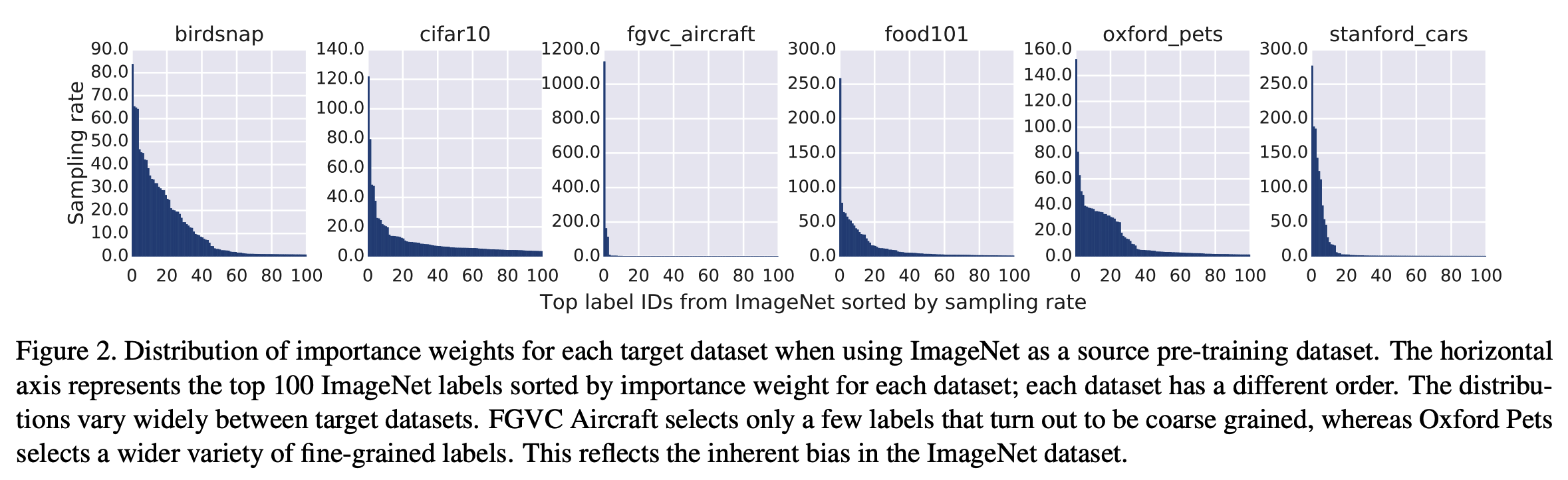
- 위 그림을 보면 FGVC Aircraft 와 Cars 는 분포가 급격하게 몰려있는 것을 확인할 수 있다.
- 이 의미는 ImageNet 의 경우 aircraft 와 cars 에 대해서는 coarse-grained 레이블만 존재한다는 것.
- 결국 ImageNet 기반의 모델에서는 Aircraft 와 Cars 에 대해 다양한 차별요소를 수집하지 못한다는 의미.
Sampling 방법에 대한 비교
- 앞서 pre-training 과정에 샘플링 작업을 추가하였다고 언급했다.
- 여기서는 이에 대한 비교를 다룬다.
- 여기서는 2가지 샘플링 기법을 살펴본다.
- sampling with replacement (same distribution matcher)
- 분포에 대한 변화가 없음.
- sampling without replacement (elastic distribution matcher)
- 동일한 이미지가 추출되지 않도록 작업을 한다.
- 대신 impotance sampling 분포와 많이 달라질 수 있다.
- 논문 설명이 좀 이상하긴 하다.
- importance weight 가 가장 높은 클래스부터 전부 take 하여 수집.
- sampling with replacement (same distribution matcher)
- 확인해볼 수 있는 것들
- unique example 이 더 많은 경우 성능은 어떠한가?
- pre-training 으로 사용되는 데이터의 분포가 importance weight와 차이가 많이 나는 경우엔 어떠한가?
- 별로 중요한 것은 아니니 간단하게 정리하자.
- 결론은 동일한 분포를 맞추는 것이 좋다.
- same distibution matcher 는 높은 성능에서 saturation 된다.
- elastic distribution matcher는 초기 성능이 높지만 이후 성능이 낮아짐.
- 샘플링 후반부에서 얻어지는 데이터 분포는 비슷한데 이런 현상이 생긴다.
- 이는 최초 선별된 분포에서 크게 차이가 생기면서 발생하는 문제라고 생각할 수 있다.
- 따라서 unique 샘플을 모으는 것보다 분포를 맞춰 샘플링하는 것이 더 중요하다.

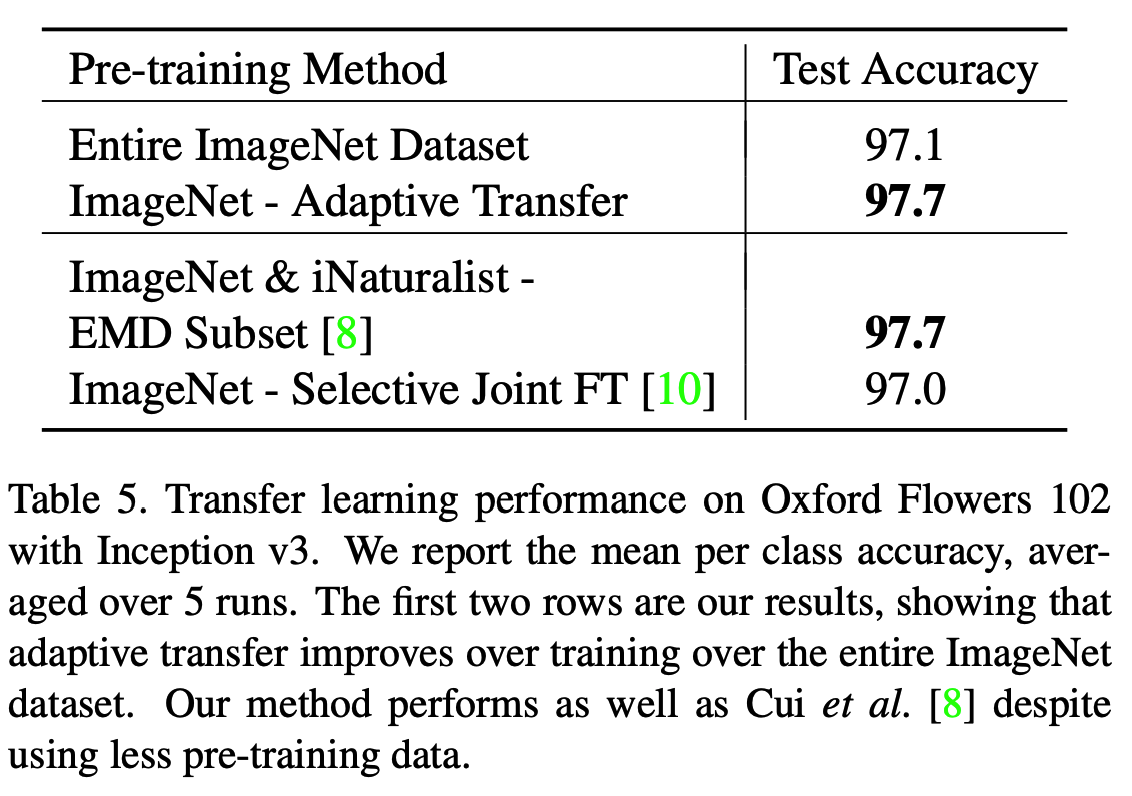
최종 결과
- 동일한 실험을 AmoebaNet-B 로 해본다. (w/ 550M 파라미터)
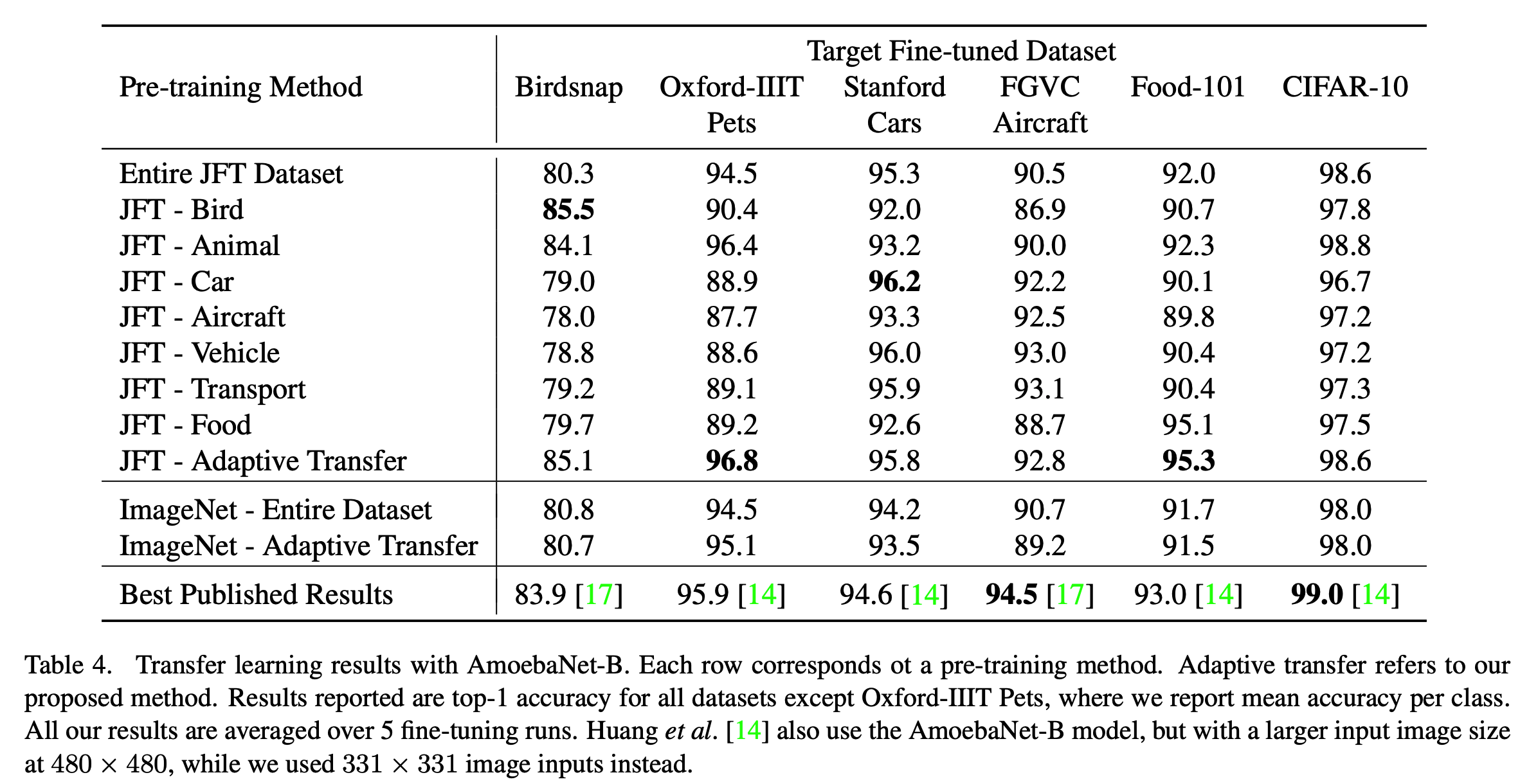
- (다른 논문에서) source 데이터로부터 target 데이터와 관련된 이미지를 추철하여 학습 성능을 올리는 기법이 제시되었다.
- 이와 비교해봐도
이 논문이 짱짱맨좋다.
- 이와 비교해봐도