- 재미있는 논문을 좀 정리해야 하는데 매번 시간이 없다.
Preface
- 논문 제목보다는 그냥 DELF 라고 부르는 CNN 모델을 설명하는 논문으로 알려져있다.
- 포항공대 + Goolgle 콜라보의 논문이다.
- Google Vision API 에서 핵심적으로 사용되는 이미지 검색 기능이 아닐까한다. (추측이긴 한데 얼마전 세미나를 들었음…)
- 논문 작성자가 구글 인턴쉽 때 만든 내용으로 보인다.
- 2017년 논문이라 요즘 기준으로는 오래된 논문이다.
- 그런데 최근 Google Landmark 데이터가 공개되면서 새로 갱신되었다.
- 사실은 구글 Landmark 를 위해 만들어진 모델이었으나 최초 발표시에는 이걸 자랑할 수 없었다.
- 구글답게 데이터를 공개해버리고 논문을 새로 갱신하였다.
- 구글 Landmark Dataset 공개는 의미가 크다.
- 전통적으로 Image 검색 분야에서는 Oxford 와 Paris 라는 데이터가 많이 사용된다.
- 모두 Landmark 데이터이다.
- 하지만 학술용 데이터라 좀 많이 부족하다.
- 딱히 평가 기준으로 내세울 데이터가 없었던지라 부족해도 그냥 쓰던 상황.
- 이런 이유로 Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking 같은 논문도 나왔다.
- 여기서 구글이 표준이라 할만한 새로운 Landmark 데이터를 공개해버린 것.
- 전통적으로 Image 검색 분야에서는 Oxford 와 Paris 라는 데이터가 많이 사용된다.
Introduction
- 논문은 일단 광고로 시작
- local feature 를 활용한 킹왕짱 이미지 검색 시스템
- attention 메커니즘의 도입.
- 교체 가능한 키 포인트 디텍터 (keypoint detector)
- FP(false positive) 를 제거할 수 있는 능력
- 새로운 dataset 도 함께 드려요. (google landmark dataset)
- TensorFlow models 기본 탑재. (링크)
- 일단 Large-scale 이미지 검색 시스템을 염두해 두고 시스템이 개발되었다.
- CNN 이 모든 이미지 연구에 한 획을 그엇지만 부족한 점이 있는 것도 사실이다.
- 대규모 검색 시스템에 도입하기가 쉽지는 않다.
- 대규모의 이미지는 거의 쓰레기 수준. (clutter, occlusion, variations view-point, illumination)
- Global descriptor (즉, CNN feature) 는 이미지 부분 패치에 대한 정보를 가지지 못한다.
- 그래서 최근에는 CNN 을 사용하되 이미지 국소 영역에 대한 정보를 추출하는 local descriptor 에 대한 연구가 많아지고 있다.
- 하지만 성능은 믿을 수 없다.
- 대부분의 논문들이 소규모의 데이터 집합을 이용한 테스트만 수행한다.
- 제대로 하려면 (즉 유의미한 결과를 좀 만들어내려면) 대량의 학습 데이터를 활용해야 한다.
- 이 논문의 목적은 CNN을 활용한 대규모 이미지 검색 시스템.
- 하지만 품질을 양보하진 않을 거에요.
- 주요한 포인트는 attention 기능이 가미된 local feature 기반의 CNN 모델.
Related Work
- 기존의 데이터
- Oxford5k (5,062), Query 는 55개
- Paris6k (6,412), Query 는 55개
- 도대체 쓸데가 없다.
- 그래서 종종 Flickr100k (100k) 데이터를 섞어서 학습하기도 한다.
- Holday dataset도 조금 쓰는데 1491 개의 이미지와 500개의 Query.
- 검색 기법
- 예전에 사용되는 근사 검색 기법은(ANN) KD-Tree 를 활용. (당연히 지금은 아무도 안쓴다.)
- local feature
- VLAD 나 Fisher Vector 같은 전통 기법들.
- global feature
- pretrained 된 CNN 결과 등.
Google-Landmark Dataset
- 원래 이런 데이터를 어떻게 생성하는지에 대한 논문도 낸 적이 있다. (2009년, 논문 참고)
- 어쨌거나 Landmark 데이터를 공개한다. 앞으로 이걸로 평가를 좀 하자.
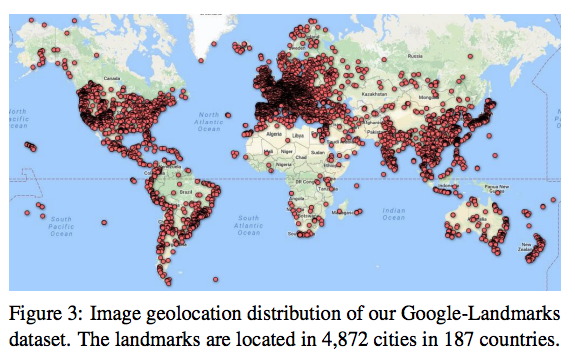
- 12,894 개의 명소가 포함. 총 1,060,709 개의 이미지. 111,036개의 Query 이미지.
- 전 세계를 대상으로 추출되었으며 GPS 정보와 연계되어 있다.

- Ground Truth 정보를 만들기 위해 다음 두 feature 정보를 활용한다.
- visual feature
- GPS coordinates
- 두가지 정보를 이용하여 클러스터를 구축한다. (클러스터마다 중심점과 고유 ID를 부여)
- 질의(query) 이미지와 클러스터 거리가 특정 threshold 이내로 들어오면 동일한 이미지라고 가정한다.
- 사실 정확한 Ground Truth 정보를 만드는 것은 매우 힘든 일이다.
- GPS 정보가 잘못될 수도 있다.
- Landmark 가 너무 다양한 각도에서 촬영되어 서로다른 구조물로 보일수도 있다.
- Landmark가 아주 먼 거리에서 촬영되기도 한다.
- 실측 거리가 25km 이내로 한정하여 구하면 적당한 결과를 얻을 수 있다는 것을 확인했다.
- 데이터에 에러가 좀 있더라도 결과는 괜찮게 나온다.
DELF
- 대규모의 이미지 검색 시스템은 다음 4단계 작업으로 나누어볼 수 있다.
- (i) dense localized feature 추출
- (ii) keypoint 선택
- (iii) dimensinality reduction
- (iv) 인덱싱 및 검색 시스템 구축
- 먼저 전체 구조를 보자.
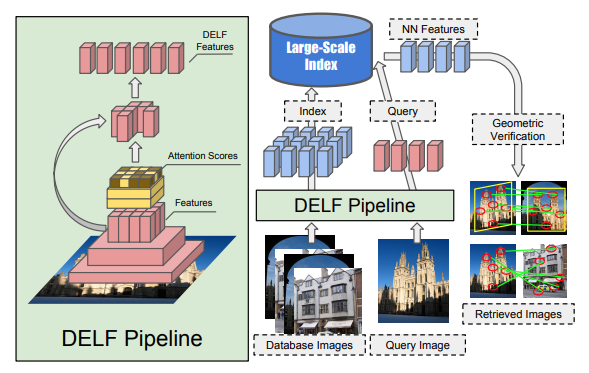
- ResNet50 모델이 기본 백본이다.
- imagenet 으로 pretrain 된 net. 이다.
- 이 중 conv4_x 레이어를 사용하게 된다. (링크)
- 즉, FCN 정보를 활용한다.
- 명시적으로 image pyramid 를 사용하여 여러개의 feature 를 추출한다. (각각의 FCN)
- 이건 데이터 구축시 사용하는 것으로 보임.
- 학습 단계에서는 고정된 입력 크기를 가지는 듯.
- landmark 데이터로 fine-tunning 과정을 거친다.
- 입력 이미지는 모두 center crop뒤 250x250 으로 rescale 된다.
- 여기서 224x224 크기로 랜덤 crop.
- 전체 과정중에 object 나 patch 레벨에서의 정보를 사용하지 않는다.
Attention-based Keypoint Selection.
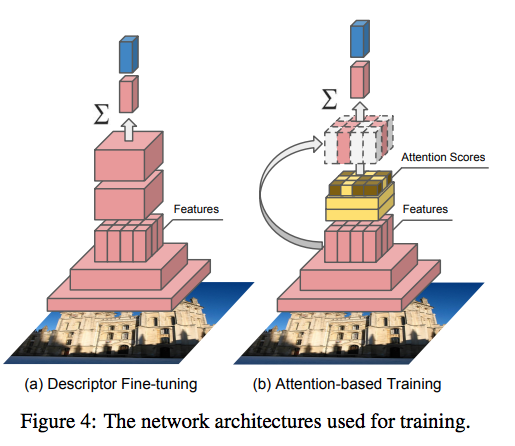
- 추출된 feature 를 모두 사용하는 것이 아니라 attention 을 이용해서 keypoint 만 추출한다.
- keypoint 를 추출하는 것은 품질 뿐만 아니라 시스템 효율화에도 매우 중요한 요소이다.
Learning with Weak Supervision
- weighted sum 을 이용한 방식. (pooled by a weighted sum)
- 그림 4(b) 를 참고하자.
- \(\alpha(f_n;\theta)\) 는 score 함수이고 이 때 파라미터는 \(\theta\) 가 된다.
- \({\bf W}\) 는 \( {\bf W} \in R^{M \times d} \) 이고 \(M\) 은 클래스 갯수이다.
- 로스 함수는 cross entropy loss 를 쓴다.
- 여기서 \({\bf y}^*\) 는 ground-truth 이고 \({\bf 1}\) 는 one vector.
- score 함수 \(\alpha(\cdot)\) backpropagation시 학습이 된다.
- 여기서 \(\alpha(\cdot)\) 는 음수가 되지 않도록 강제한다.
- 실제 score 함수 구현은 2개의 conv 레이어와 softplus 비선형 함수로 구현되어 있다.
- 이 때 1x1 conv 를 사용하게 된다.
def _attention(self, attention_feature_map, feature_map, attention_nonlinear, kernel=1):
with tf.variable_scope('attention', values = [attention_feature_map, feature_map]):
with tf.variable_scope('compute', values = [feature_map]):
conv1 = slim.conv2d(feature_map, 512, kernel,
rate=1, activation_fn=tf.nn.relu, scope='conv1')
score = slim.conv2d(conv1, 1, kernel,
rate=1, activation_fn=None,
normalizer_fn=None, scope='conv2')
with tf.variable_scope('merge', values=[attention_feature_map, score]):
prob = tf.nn.softplus(score)
feat = tf.reduce_mean(tf.multiply(attention_feature_map, prob), [1,2])
feat = tf.expend_dims(tf.expaned_dims(feet, 1), 2)
return feat, prob, score
Tranining Attention
- 제안된 모델은 feature 와 attention 모듈이 모두 함께 학습되는 구조.
- 학습이 잘 안될 수 있다.
- 그래서 2-step 방식의 학습을 제안.
- 먼저 descriptor 부터 학습을 한다.
- 이후에 descriptor 를 고정하고 score-function 을 학습한다.
- 성능을 올리기 위해 attention 을 학습할 때 다양한 scale 로 학습한다.
- 일단 center-crop 을 수행한뒤 (squre) 900x900 으로 rescale.
- 랜덤하게 720x720 을 크롭한 뒤 r <= 1 범위의 축적으로 최종 rescale.
Characteristics
- 전통적인 KeyPoint 추출로 SIFT나 LIFT 등을 들 수 있다.
- 여기서 사용되는 방법은 이것들과는 다른 방법이다. (descriptor 생성 후 선택)
- 기존의 방법은 낮은 수준의 특징들을 추출하는 기법이다.
- 반면 우리가 필요한 것은 객체 단위 keypoint.
- 제안된 방법은 이미지 분류 작업을 통해 feature map으로부터 좀 더 높은 수준의 정보들을 가려내게 된다.
Dimentionality Reduction
- 검색 성능을 올리기 위해 최종 차원(dim)을 줄인다.
- 먼저 L2 norm 을 적용 후 PCA를 돌린다. (40dim 까지 줄인다.)
- 그리고 다시 L2 norm.
IR System
- 기본적인 검색 방식은 ANN
- 보통 PQ (Product Quantization) 가 많이 사용되는데 여기서는 KD-Tree 를 혼용해서 사용한다.
- 추출되는 feature 의 크기는 40D 이고 이를 최종 50bit 화 시킨다.
- 기존의 PQ 를 개선하였다.
- residual 에 대한 PQ 색인 부분을 KD-Tree 로 대체.
- PQ 에 대한 설명을 자세히 할 수 없기 때문에 그냥 넘어가자.
- 의문점.
- 겨우 100만개의 이미지를 위해 PQ를 쓸필요가 있나?
- Random Projection Tree 같은게 더 편할 것 같은데…
Experiments
- 평가 방법
- IR의 전동 measure 방식인 mAP (mean average precision)
- 모든 쿼리마다 얻어진 결과를 relevance 순으로 정렬한뒤 측정된 ap의 평균값을 의미
- 이 논문에서는 평가 방법을 약간 바꿈.
- \(R_q\) 는 쿼리 \(q\) 로 얻어진 검색 결과를 의미한다.
- \(R_q^{TP}(\in R_q)\) 는 true-positive 결과를 의미한다.
- 이러한 방식은 micro-AP 라 부르는 평가방식과 유사하다.
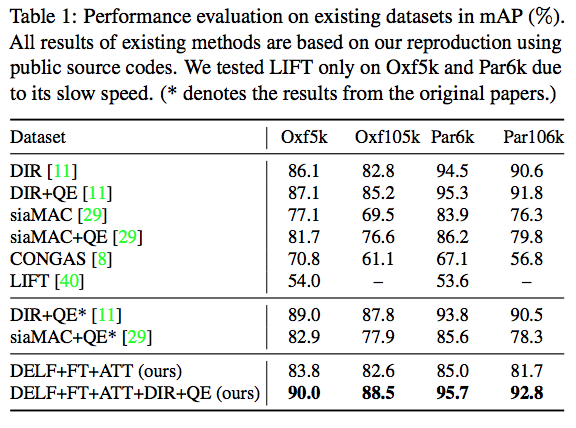
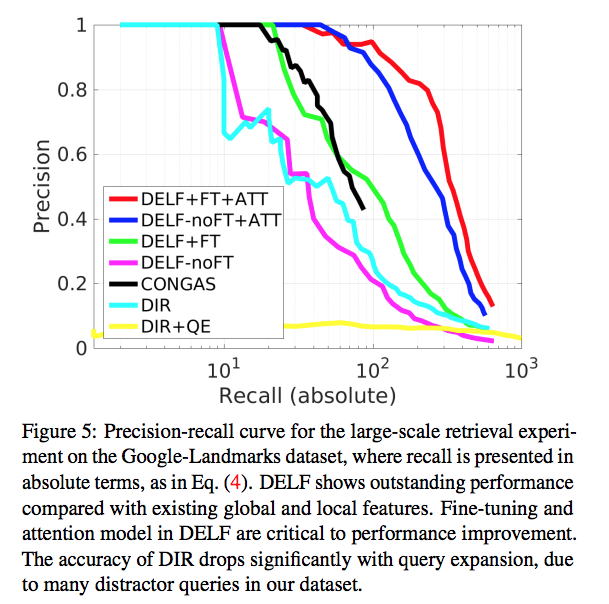
- FT 는 fine-tuning 이라는 의미.
- ATT 는 attention 이라는 의미.
Qualitative Results
-
DELF vs. DIR
-
그림 6이 DELF와 DIR 차이를 보여준다.

-
왼쪽은 Query, 중간은 DELF, 오른쪽은 DIR.
-
반대의 케이스도 좀 보자.

-
DELF vs. CONGAS
-
그냥 뭐 DELF 가 더 좋다.

-
DELF 나온 결과를 RANSAC 을 돌려 확인해봄.
-
Attetion 결과들
