-
목표 : 이미지를 질의로 받아 유사한 이미지를 검색하자.
-
논문
소개
- Instance-level image retrieval
- 간단하게 생각하면 이미지를 넣어 유사한 이미지를 반환해주는 검색
- 좀 더 구체적으로는 이미지 내 오브젝트와 가장 유사한 오브젝트를 찾아서 반환해주는 시스템.
- 단순하게 동일한 이미지를 찾는 문제 수준부터 시멕틱한 정보까지 활용하여 유사한 이미지를 찾는 것까지 고려할 수 있다.
- 보통 매우 큰 이미지 집합 내에서 검색을 해준다.
- 웹 환경에서 사용되거나 사용자 앨범 등의 이미지에서 검색을 제공하는 등 여러 응용 예제가 있다.
- CNN 응용 예제들.
- CNN을 이용하여 유사 이미지를 찾고자 하는 시도를 많이 했음.
- ImageNet 으로 학습된 분류용 pretrained Network 을 얻어다가,
- 분류 단계 이전 CNN Feature 정보로부터 유사한 이미지를 찾는 시도가 많았음.
- 물론 성능은 대부분 적당하지만 부족한 것도 사실.
- CNN을 이용하여 유사 이미지를 찾고자 하는 시도를 많이 했음.
- 왜 부족할까?
- 일단 데이터에 잡음이 많다. (유사 이미지를 찾기위해 사용되는 데이터로는 부족)
- 사용된 모델이 부적절하다. (유사 이미지용 모델이 아님)
- 잘못된 학습 방식 (기존의 분류 학습 방식으로는 유사 이미지를 찾지 못함)
- 다음은 흔하디 흔한 Transfer Leanring w/ CNN
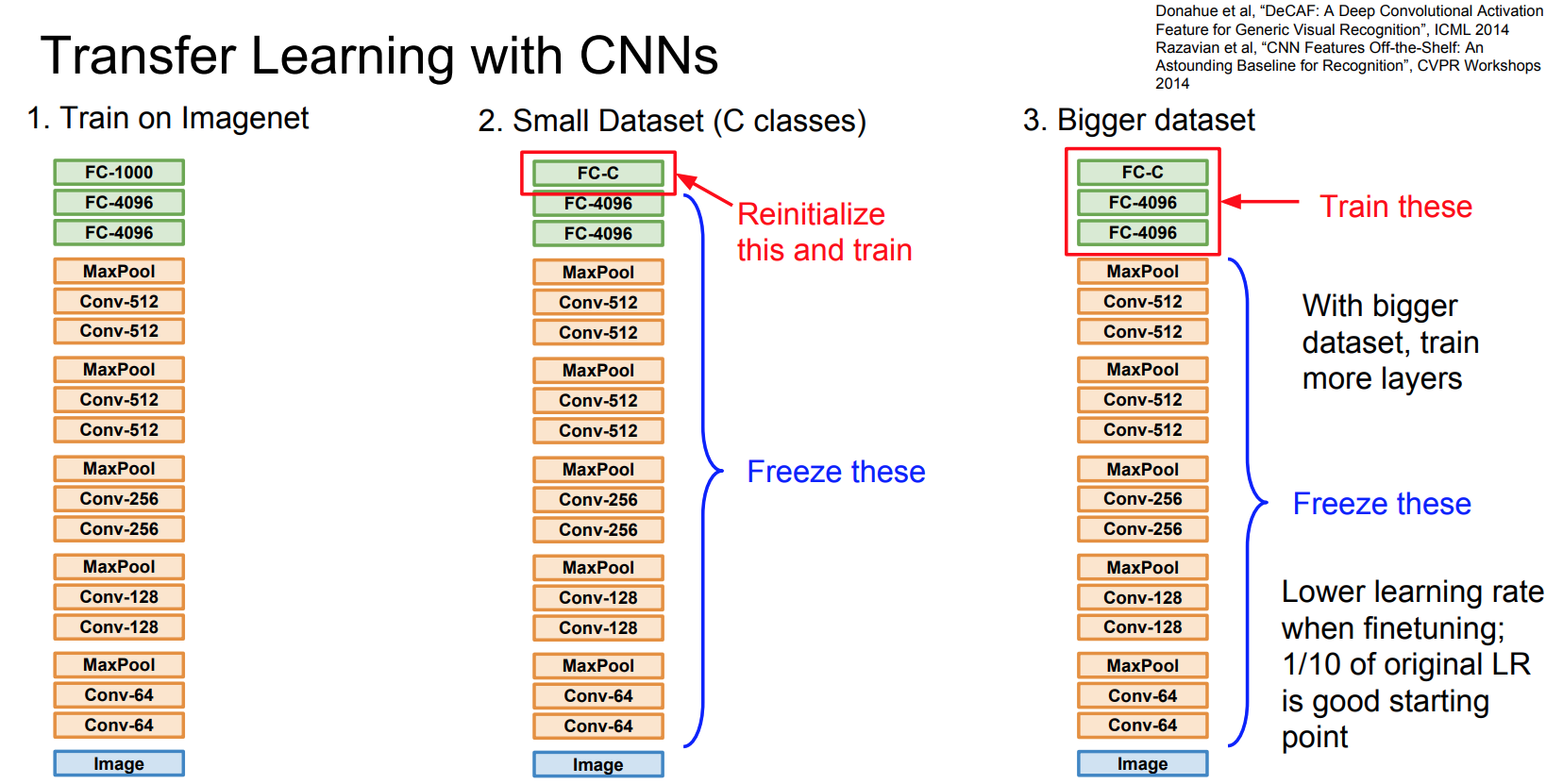
- 논문들에서는 검색 목적에 부합하는 Task로 정의하여 이 문제를 해결함.
- 데이터를 최대한 유사 이미지 Task 에 맞도록 정제
- 유사 이미지 검색을 위한 모델 개발
- 검색에 유용한 정보를 추출하기 위해 R-MAC 과 같은 discriptor 를 사용
- 이는 CNN 계열의 discriptor로 서로 다른 스케일의 이미지 Region을 추출하여 sum-aggregate 하는 방식
- 물론 기존의 R-MAC 이론과는 조금 다르게 사용함.
- 새로운 Loss 의 제안
- Triplet 모델을 도입하여 유사 이미지 검색에 적합하도록 학습 구조를 변경
- 추가로 유사한 이미지를 잘 찾을 수 있는 정보들을 추가
- 이미지 서술 문장 등
- 먼저 각각의 모듈에 대한 기능을 살펴보고 전체 아키텍쳐를 조망해보도록 하자.
R-MAC (Maximum Activations of Convolutions) Descriptor
-
R-MAC을 이해하려면 먼저 MAC (Maximum Activations of Convolutions) Descriptor 가 무엇인지 알아야 한다.
-
논문 : Particular object retrieval with integral max-pooling of CNN activations

- 먼저 pretrained CNN 을 사용하되 FC 레이어는 제거.
- Conv 레이어는 (\(W \times H \times K\)) 크기가 된다. 모두 Relu Activator 를 사용한다고 가정한다.
- \(W \times H\) 를 새로운 변수인 \(X\) 로 표현해보자. \(X = \{ X_i \}, i= \{ 1, …, K \}\)
- 따라서 \(X_i\) 는 2D Tensor를 나타내게 된다.
- 추가로 Conv의 position 정보를 \(p\) 하고 하자. 이 때 \(X_{i}(p)\) 는 position \(p\) 에 해당하는 2차원 Tensor를 의미하게 된다.
- 새로운 feature vector \(f\) 를 정의한다.
- 결국
K크기를 가지는 1차원 벡터가 된다. -
가장 중요한 단점은 모든 지역(localization) 정보가 사라진다.
- MAC 을 이용한 유사도 평가
- 두 이미지로부터 얻은 MAC을 cos-sim 을 통해 유사도를 계산한다.
- 보통은 맨 마지막 FCN을 사용.
- 실제 얻어진 결과를 보자.
- 가장 활성화가 높은 위치의 정보만을 취득하여 유사도를 비교하기 때문에 거의 유사한 이미지에서는 동일한 지점에서의 Feature 값이 추출될 수 있다.
- 아래 예제는 두 이미지 사이에서 추출된 MAC이 일치되는 영역 5개를 출력하고 있다.

R-MAC
- Region feature vector
- 앞서 이미지를 나타내는 feature vector \(f_{\Omega}\) 를 살펴보았다.
- 이것을 어떤 특정 사각형 Region에 해당하는 feature vector로 나타내면 다음과 같다.
- \(R \subseteq \Omega = [1, W] \times [1, H]\)
- R-MAC
- R-MAC은 그냥 크기가 다른 여러 개의 Region 을 사용한 것이라 생각하면 쉽다.
- 일단 정사각형(square) 의 Region을 사용한다. (이미지의 \(W\) 와 \(H\) 가 다를 경우 짧은 쪽 기준)
- 여러 스케일 값으로 Region 을 생성하게 되는데 이 때의 스케일을 결정하는 값을 Layer 라고 한다.
- \(l=1\) 인 경우가 가장 큰 스케일을 가지게 된다.
- 이 Region은 가용한 최대 면적의 40% 이하로는 떨어지지 않는 크기로 결정하게 된다.
- 아래 그림을 보면 대충 어찌 뽑히는지 알 수 있다.
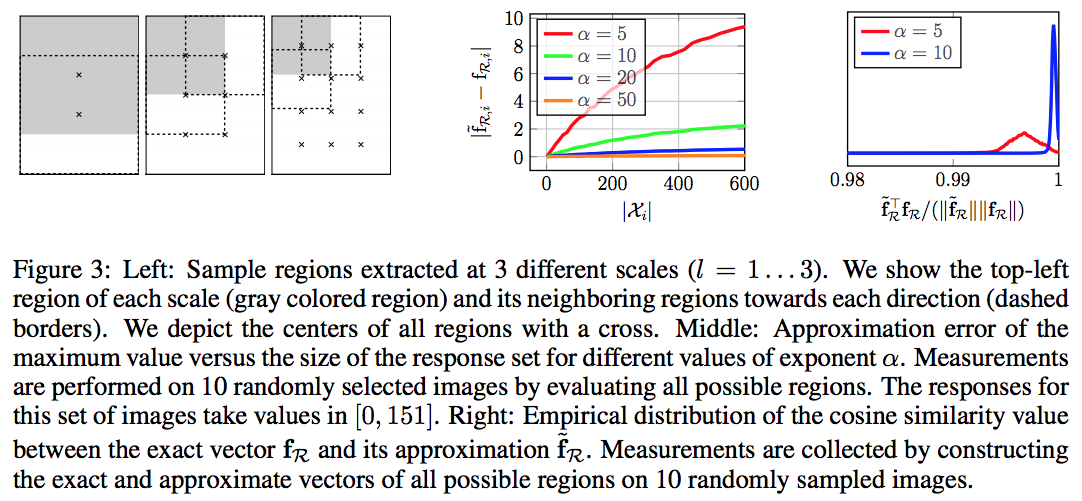
- 후처리로 각각의 Region별 MAC 을 합산한 뒤 Normalization 과정을 거치게 된다.
- 여기서는 PCA 를 이용하여 Whitening 작업을 수행하게 된다.
- 이후 DeepIR 에서는 이 부분을 따로 계산하는게 귀찮았는지 shift + FC 의 NN 모델로 대체하게 된다.
Object Localization
- Region 내에서 Max 값을 구하는 것은 비싼 비용이다. Approximate integral max-pooling 을 이용하여 근사하자.
- 제시된 Region 중 입력된 q 와 가장 유사한 Region 을 찾는 식은 다음과 같다.
- 실험 결과는 다음과 같다.
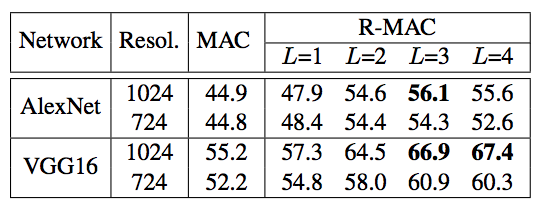
- 예제를 통한 결과는 다음과 같다.

DeepIR
- 이전에 사용하던 R-MAC 을 여기에서는 RPN (Region Proposal Network)으로 변경
- 그런데 기존의 R-MAC 도 테스트를 했음.
- 게다가 사실 성능이 그리 차이가 나지 않는다.
- 그래서 Resnet 버전에서는 다시 쉽고 편리한 R-MAC으로 변경
- 이 논문의 핵심은 Tripplet 임.
- 샴(Siamese) 네트워크의 일종.
- Query 이미지와 유사한 이미지 1개, 다른 이미지 1개를 이용하여 학습하는 구조.
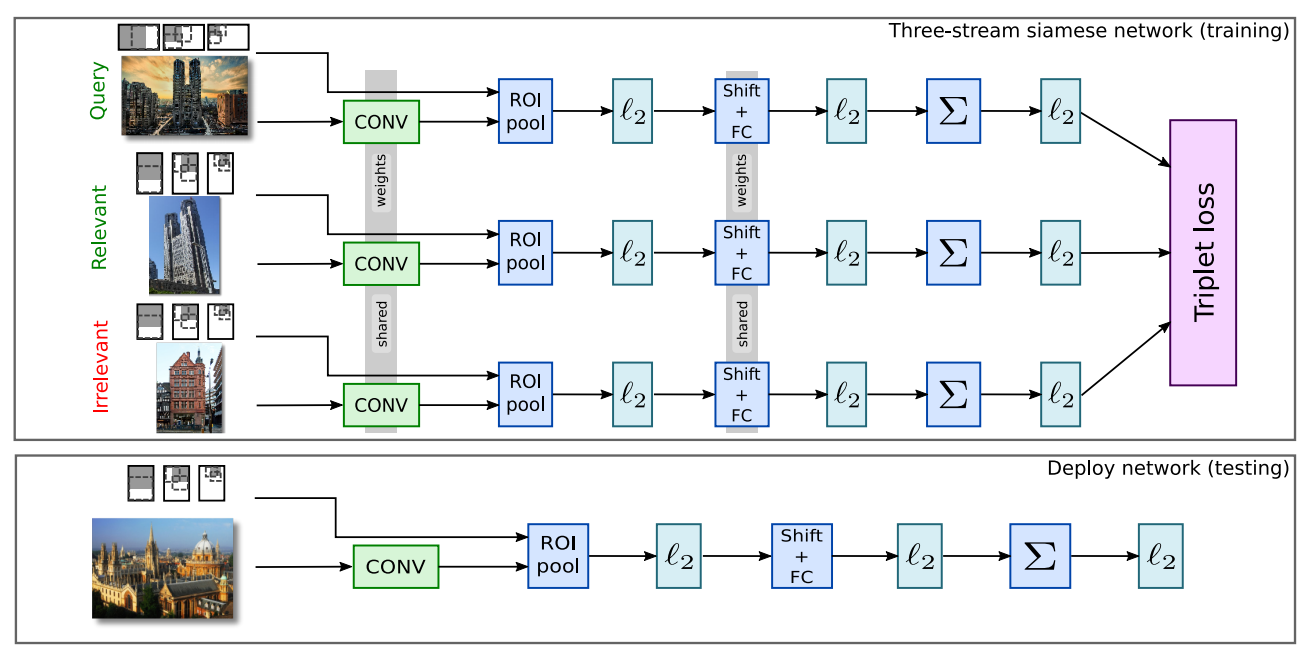
m은 margin 값을 의미하고+는 positive sample,-는 negative sample을 의미한다.- Loss 함수가 유사 이미지를 찾는 형태로 정의되므로 당연히 성능이 올라갈 것이라는 것은 예상할만 일이지만,
- 이 논문에서 품질 향상에 진짜 중요한 부분을 차지하는 것은 바로 학습 데이터 정제
학습 데이터 정제 과정
- 학습에 사용된 데이터는 Landmark 데이터. (이 논문 에서 사용된 데이터이다.)
- 약 214K 개의 데이터로 이루어져 있으며 672개의 명소로 이루어져있다.
- 검색엔진(아마도 구글) 등을 이용하여 수집한 데이터로 정제 과정을 많이 거치지는 못했다.
- DeepIR 논문에서의 전처리.
- 제공된 URL 리스트 중 URL이 깨진 데이터는 더 이상 받을 수 없기에 이를 제외함.
- 이미지 개수가 작은 특정 class는 모두 제외 처리
- 심혈을 기울여 Oxford5k 와 Paris6k, Holiday 데이터 집합과 겹치는 데이터는 모두 제외.
- 최종적으로 192K 개의 데이터, 586개의 레이블을 얻을 수 있었다.
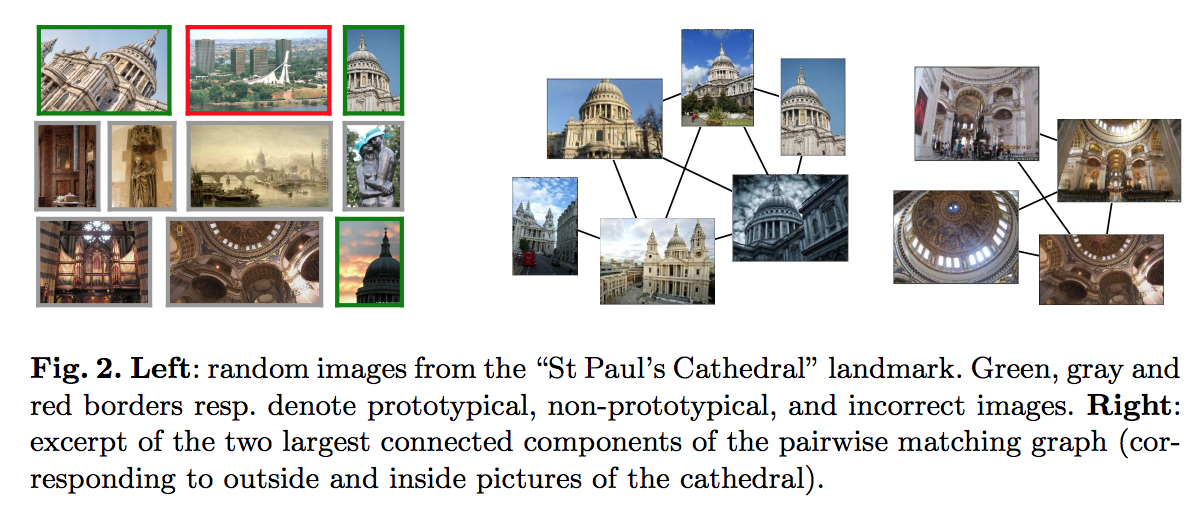
- DeepIR 논문에서의 학습 데이터 정제 과정.
- 주어진 학습 데이터는 동일한 레이블일지라도 다른 그림인 경우가 있음.
- 분류 문제에서는 뭐 큰 상관 없지만 Instance 레벨의 유사 이미지 분류에서는 큰 문제.
- 예를 들어 ‘성 바울 성당’ 이미지는 외부/내부 전경이 섞여있음.
- 이를 Instance 레벨로 그룹을 할 필요가 생김. (애초에 목표가 Instance Level의 유사 이미지 검색임)
- 그룹핑을 위한 이미지 매칭 작업에서 가장 먼저 수행한 것은 SIFT + Hessian-Affine keypoint detector.
- 이런 식으로 하나의 레이블에 여러 그룹이 생기는 경우 가장 많은 데이터를 보유한 그룹만을 남김.
- 최종적으로 49K 의 이미지만을 학습에 사용함. (training : 42,410, validation : 6382)
- 주어진 학습 데이터는 동일한 레이블일지라도 다른 그림인 경우가 있음.
-
Bounding Box Estimation
- R-MAC 을 사용하는 방식에서는 특정 객체의 박스(Box)가 필요 없다.
- 하지만 RPN 을 사용하려면 학습 집합에 반드시 동일 Object 는 동일한 Bounding Box를 가지고 있어야 한다.
- 일단 데이터 전처리 과정으로 동일한 Object 에 대해 여러 이미지들을 확보한 상태이지만 Bounding Box는 존재하지 않는다.
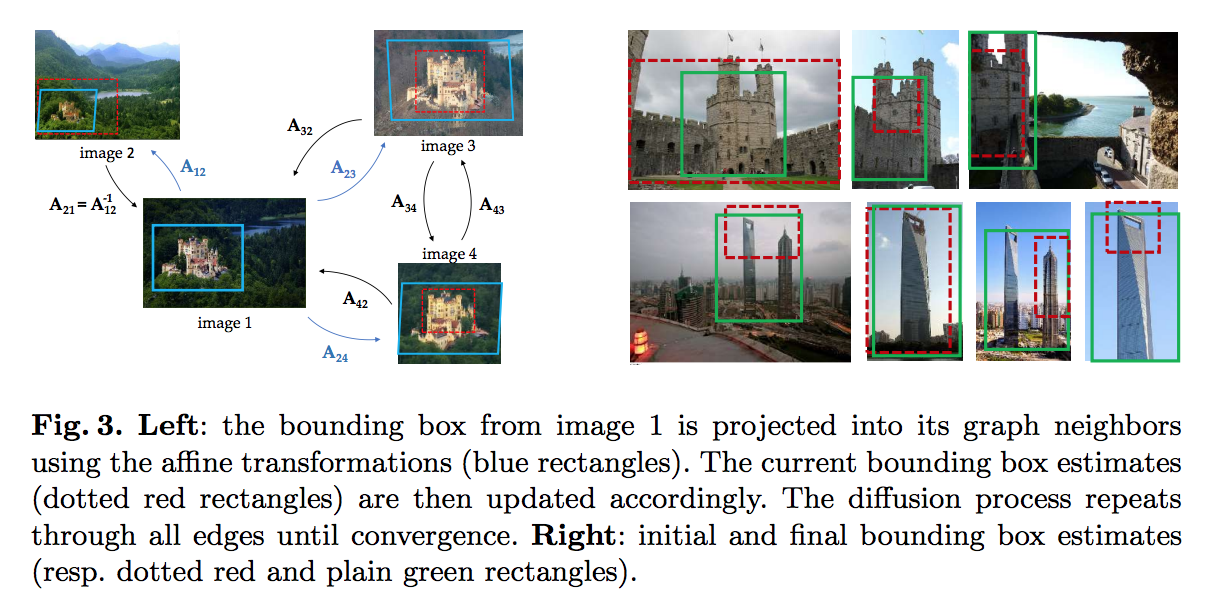
- 여기서는 자동으로 Bounding Box 를 생성하는 법을 다룬다.
- 일단 Keypoint Matching 방법을 통해 (Grouping시 사용되는 기법) 대략적인 Boxing 은 가능하다.
- 하지만 정확도를 위해 동일 그룹 내 각 이미지마다 비슷한 Object가 비슷한 형태로 Boxing 되어야 한다.
- 이를 위해 Boxing 을 후처리로 보정하는 기능을 추가함.
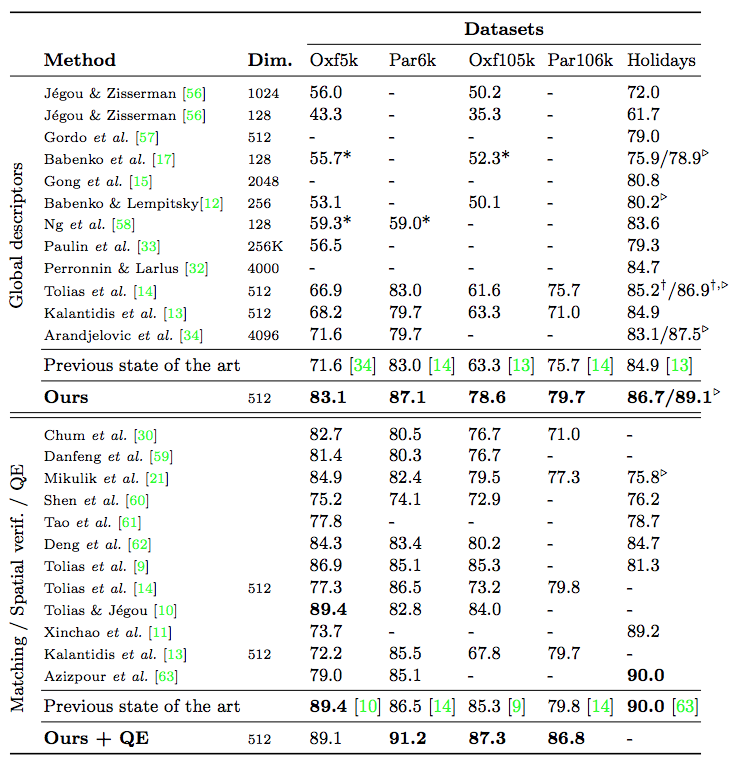
DeepIR 실험 결과
- 어쨌거나 유사 이미지 검색에서 가장 좋은 품질을 보임.
- 실제 구현체는 Caffe로 되어 있는 것을 구할 수 있다.
- 그런데 코드를 약간 수정해서 재컴파일하여 사용해야 함.
- 고민해 볼 만한 점
- 학습 데이터는 보통 건물 등인데 이런 스타일이 아닌 Object 가 두드러지는 예제들 (예를 들면 물건 등)에서는 품질이 어느정도 될까?
- 2017년 5월에 개선판이 arxiv에 올라옴. (링크)
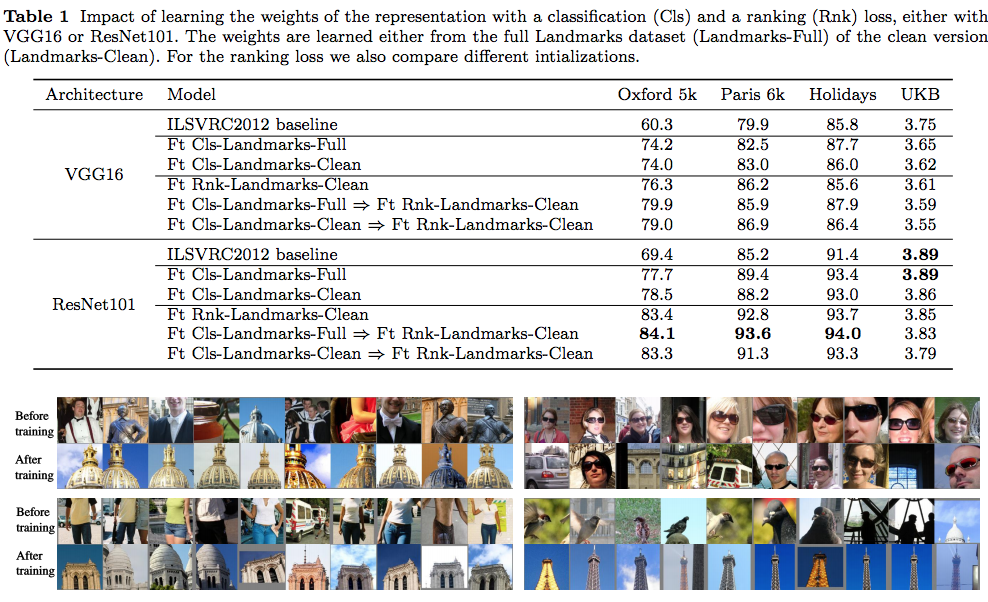
- VGG16 대신 ResNet 을 쓰면 성능이 더 올라간다. (ResNet101)
- 게다가 ResNet을 쓰면 힘들게 RPN을 할 필요 없이 R-MAC만으로 충분하다. (성능 향상의 효과가 없음)
- 이미지의 여러 Resolution 을 사용하여 학습하면 성능이 올라간다. (Query와 학습 집합 둘 다에 대해 각각 테스트)
- Query와 Dataset 모두에 Multi Resolution을 사용하면 성능이 올라감.
- 최종 이미지를 압축해서 사용하는 방식도 실험해 봄. (PQ가 가장 좋음)
- (참고)
- 최근 Postect 한보형 교수님 랩에서 이 성능을 넘는다는 유사 이미지 검색 관련 논문을 발표.
Semantic-DeepIR
- 지금까지는 Instance 레벨의 이미지 검색에만 중점을 두고 있었음.
- 하지만 이미지의 부가 정보를 활용하면 이미지 검색을 더욱 풍성하게 만들 수 있음.
- 하지만 자연스럽게 Deep Learning 으로 한번에 이걸 다 해보고 싶다.
-
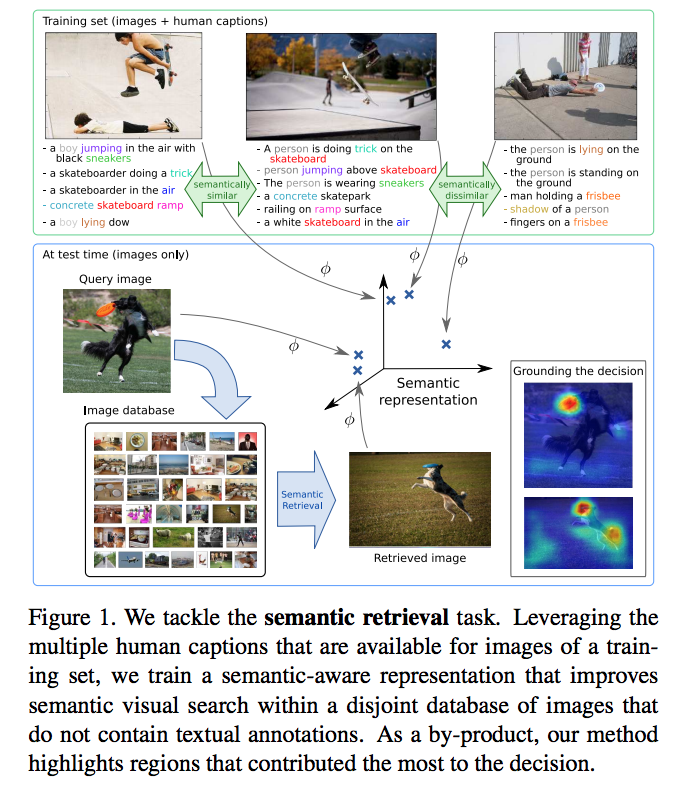
이 논문에서는 좀 더 복잡한 형태의 이미지(예를 들어 Object가 다수 등장하는 이미지)에서 좀 더 정확한 이미지 검색을 수행할 수 있는 방법을 다룬다.
- 사실 이 그림만 봐도 대략적인 방법을 이해할 수 있다.
Dataset
- ImageNet 등으로 학습된 결과로 얻어지는 유사 이미지의 결과를 일반 사용자에게 제시했을 때 별로 좋은 소리를 못들음. (복잡한 이미지의 경우)
- 이 말은 Semantic 유사성을 가지는 이미지를 얻어내기 위한 다른 방안이 필요하다는 이야기.
- 일단 이를 위한 학습 데이터를 어떻게 모으는지를 논의해보자.
- 사실 재료가 될만한 데이터는 좀 있기는 하다.
- MS-COCO (이미지 뿐만 아니라 caption 데이터도 포함)
- VQA 데이터
- Visual Genome 데이터 (108k 크기인데다가 caption도 포함)
- 이게 참 어려운 데이터이다. ( 관련 논문 )
- 현실적으로 Semantic Image 를 위한 학습용 데이터를 구축하기란 쉬운 일이 아니다.
- 복잡한데다가 시간이 엄청나게 소요된다.
- 그래서 좀 더 쉬운 방향으로 접근하기로 함. (Triplet 데이터)
- 3 개의 이미지를 사용자에게 제시하고 이 중 더 가까운 이미지를 고르게 한다.
- 주어진 쿼리 이미지에 대해 동일한 카테고리 이미지 하나와 무작위 추출 이미지 하나로 구성된 Tuple.
- 이를 35명의 연구자가 평가함. (남자 22, 여자 13명) 데이터는 약 3,000개의 triplet을 구성함.
- 추가로 50 개의 triplet을 표준 집합으로 정의하고 25명으부터 평가를 얻음.
- 이 때 ‘더 유사하다’ 라는 의미를 애매하게 사용하지 않고 구체적으로 명시해서 최대한 bias가 없도록 한다.
- 3 개의 이미지를 사용자에게 제시하고 이 중 더 가까운 이미지를 고르게 한다.
- 랭킹 평가를 위해서 추가 작업을 진행
- 적당한 평가 지표를 만들어 사용자들이 평가한 것을 다른 사람과 비교해 볼 수 있도록 평가 지표를 만듬. (합의 스코어)
- leave-one-out 이라는 방식이라고 함.
- 순위 질문을 이용해서 사용자가 평가를 내리면 이와 동일한 평가를 한 다른 사용자의 비율로 측정
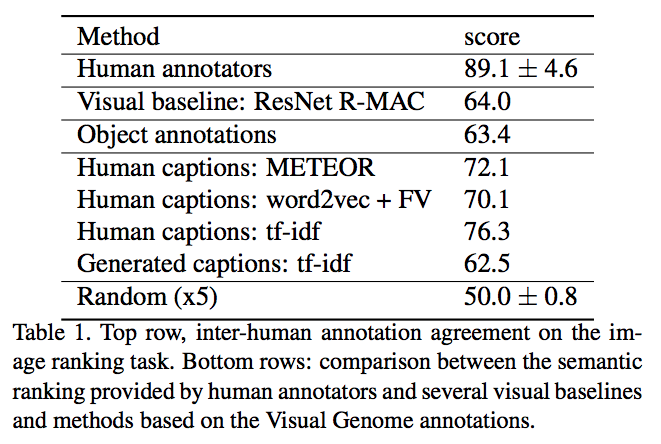
- 자세한 방법은 생략하고 어쨌거나 도출된 합의 평가 스코어 (agreement score) 는 89.1 (표준편차는 4.6)
- 대충 의미하자면 두 이미지 사이의 유사도를 약 89% 정도는 같다고 생각한다는 것.
- 이제 Base 결과를 확인해보고 시작하자.
- 사람이 내린 평가는 89% 정도라고 앞서 이야기했고,
- 이전 논문에서 사용한 ResNet + R-MAC 성능이 약 64% 정도이다. (이는 랜덤 결과인 50% 보단 높다)
- 이로부터 0% 부터 시작이 아니라 50% 부터 성능 지표의 시작 임을 감안해야 한다.
- Human captions 영역
- Semantic 정보에 대한 이미지 유사도를 비교하기 위한 Base Line으로 활용된다.
- Visual Genome 데이터에는 각 object별로 특정 단어들이 기술되어 있다. (Visual Genome 사이트를 방문해보자)
- 이 단어를 WordNet synset(동의어)에 매칭하여 이미지를 기술한다.
- 이로부터 이미지에 대한 히스토그램을 만들게 됨. (synset에 등장하는 단어별로 count한 뒤 tf-idf 및 l2 정규화를 진행)
- 두 이미지에 대해 dot product를 수행하여 유사도를 비교하게 된다.
- 이런 방식으로 semantic 유사도를 평가하게 된다.
- 자세한 내용은 시간이 없으므로 생략하자. (논문을 참고하자)
Visual Embedding
- Visual 정보에 대한 표현(representation)은 앞서 이야기한 대로 RetNet101 + R-MAC 을 사용한다.
- Semantic 유사성에 대한 학습은 End-to-End 방식으로 학습하게 된다.
- 별로 어려운게 없으니 그냥 바로 Loss를 보자면,
- 단, \(\phi(q)=\phi_q\), \(\phi(d^+)=\phi_+\), \(\phi(d^-)=\phi_-\)
-
\(\phi : I \rightarrow R^D\)
- 여기서 \(\phi\) 자체는 이미지 representation 이다.
- 하지만 두 이미지간의 semantic 유사성을 확인하는 방법은 (즉, \(+\)와 \(-\)는) tf-idf를 활용하여 선정하게 된다.
- 이런 방식으로 이미지 representation을 semantic embedding 공간에 사상하는 형태로 구성하게 된다.
- Word2Vec 방식을 한번 생각해보자.
Joint Visual & Text Embeding
- 앞서 사용한 방식은 단순히 Text 정보로 Loss 를 구성하는 것이나 마찬가지.
- 하지만 visual representation 과 text semantic 정보를 적절히 혼용한 방법은 존재하지 않는 것일까?
- 왜 없겠나. 두 정보를 적절하게 섞은 Loss를 만들면 되지.
- 단, \(\phi : I \rightarrow R^D\) , \(\theta : T \rightarrow R^D\)
- \(\theta\) 의 경우 Embeding 크기를 맞추기 위해 \(\frac{W^{T} {\bf t}}{\|W^{T} {\bf t}\|_2}\) 를 사용한다. (\(t\) 가 그 역할을 수행)
실험
- 이미지 크기를 W/H 중 긴쪽이 576이 되도록 resizing.
- 2 Layer의 R-MAC 적용
- tf-idf를 활용한 caption encoding (NLTK를 활용해서 word stemming 과정을 거침)
- 64 batch (triplet)
-
ADAM optimizer를 사용하고 lr은 \(10^-5\) 에서 8k 반복 후 \(10^-6)으로 줄임
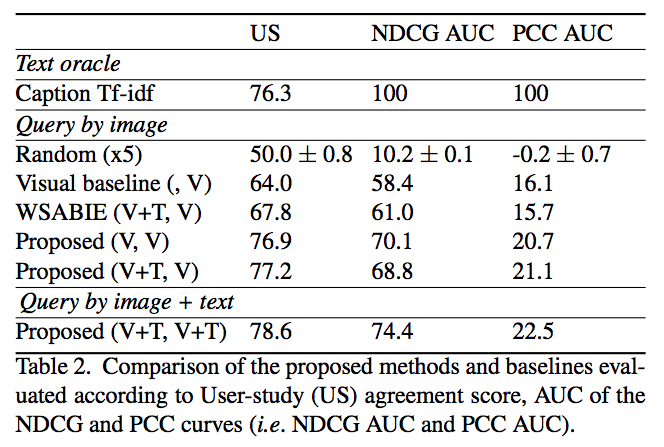
- 측정지표
- NDCG (Normalized discounted cumulative gain)
- PCC (Pearson’s correlation coefficient)