저자 : Pete Warden
개론
- TensorFlow를 모바일에서 구동시킬 수 있는 방법을 이야기하고 있는 아주 간단한 책자이다.
- 하지만 Mobile 위주보다는 TensorFlow를 어떻게 독립적인 Application에 탑재하는지를 살펴보도록 하자.
- 참고로 TensorFlow-Lite 가 나오기 이전에 출판된 책이다.
- 이 부분은 뒤에 조금 더 언급하도록 하자.
- 참고로 초반부에 각 OS별 컴파일 방법은 공식 README.md 문서가 더 잘 정리되어 있다.
- 책보다 이 문서를 살펴보는게 더 좋을 수 있다.
- 이 책은 여러 README 문서를 하나로 잘 묶었다는 것 말고는 특별한 내용은 없다.
모바일 환경에 적합한 TensorFlow 활용처.
- Speech recognition
- Image recognition
- Object localization
- Gesture recognition
- OCR
- Translation
- Text classification
- Voice synthesis
Tensorflow 를 사용 가능한 Mobile Platform.
Android
- TensorFlow 가 가장 먼저 지원하는 것은 (당연히) Android.
- 개발 Tool은 Android Studio 쓰면 된다.
- 가장 손쉬운 방법은 새로운 프로젝트를 생성후
build.gradle에 다음 두 줄만 추가하면 된다. - 진짜 두 줄이 아닌 것은 그냥 넘어가자.
- 가장 손쉬운 방법은 새로운 프로젝트를 생성후
allprojects {
repositories {
jcenter()
}
}
dependencies {
compile 'org.tensorflow:tensorflow-android:+'
}
- Android Studio 에서는 (당연히) Bazel 도 지원한다.
- TensorFlow의 기본 Building Tool은 Bazel 이다. (그 모든 짜증의 근원.)
- Java랑 기타 여러 가지 다른 라이브러리와 Dependency 가 있는 Tool 이다.
- 처음 실행시 메모리를 디따 많이 쓴다.
- 따라서 Rasperry Pi 같은 저사양 환경에서 다이렉트로 컴파일하기 힘들다. (뭔들 안 힘들겠냐만은)
- 뭐 cross-compilation이 해결 방법이긴 한데 TensorFlow에 다른 Tool 이 있으니 그걸 쓰자. (뒤에 설명된다.)
- TensorFlow의 기본 Building Tool은 Bazel 이다. (그 모든 짜증의 근원.)
- 교재에는 Android Studio에서 Bazel을 이용한 TensorFlow Build 코드가 포함되어 있다.
- 우리에게는 별로 중요한 내용은 아니니 넘기도록 하자.
- 이미 TensorFlow 공식 매뉴얼에 추가되어 있다.
- 추가로 cross-complie 로 생성하는 것도 그리 어렵지 않다.
- 앞으로 계속 나올터이니 자세히 살펴볼 필요는 없다.
$ tensorflow/contrib/makefile/download_dependencies.sh
$ tensorflow/contrib/makefile/compile_android_protobuf.sh -c
$ export HOST_NSYNC_LIB=`tensorflow/contrib/makefile/compile_nsync.sh`
$ export TARGET_NSYNC_LIB=`CC_PREFIX="${CC_PREFIX}" NDK_ROOT="${NDK_ROOT}" tensorflow/contrib/makefile/compile_nsync.sh -t android -a armeabi-v7a`
$ make -f tensorflow/contrib/makefile/Makefile TARGET=ANDROID
- Android는 Java 베이스이고 Java 환경에서 어떻게 TensorFlow로 Inferece를 하는지 궁금할 수 있겠다.
- 그런 경우 이 코드를 살펴보자. Java에서 TensorFlow를 사용하는 예제 코드이다.
- 당근 Inference만 들어있다.
- Java 코드가 꽤나 잘 되어 있는 편이지만 제공되는 함수의 갯수가 아쉽다.
- pytnon 환경에서
sess.run()을 활용해서 호출하는 정도의 API만 사용 가능하다.
iOS
- 구글이 직접 만들어낸 프로덕트는 아닐지라도 외부에서 만들어낸 좋은 iOS Application 이 많다. (TensorFlow를 이용해서 만든)
- 이 말은 구글이 크게 신경을 쓰고 있지 않다는 의미랑 같다.
- cocoapods.org 같은 site에 가보면 TensorFlow pod 를 쉽게 다운로드 할 수 있다.
- 즉, XCode 프로젝트와의 연동이 쉽다.
- 시작은 쉽지만 universal binary framework 형태라서 Customize는 어렵다. (Binary 크기 조절이라던가..)
Makefile을 활용하기.
- Makefile은 진짜 구닥다리 Build Tool 이지만 생각보다 좋다. (유연한데다가 Cross-Compile이 잘 된다.)
- 그래서 Tensorflow 에서도 이런 방식의 컴파일을 지원하기 시작했다.
- 사실 많은 사람들이 TensorFlow 이슈란에 계속 요청을 했는데도 무시하다가 도입된지는 얼마 안된다.
- “Bazel 써라. 두번 써라” 드립만 냅다 했었다.
- 이것은
tensorflow/contrib/makefile을 살펴보면 된다.- 관련해서 오히려 README.md 에 잘 기술되어 있다.
- 이걸 이용하면 iOS 뿐만 아니라 Linux, Android, Raspberry-Pi 도 모두 사용 가능하다.
- 사실 많은 사람들이 TensorFlow 이슈란에 계속 요청을 했는데도 무시하다가 도입된지는 얼마 안된다.
- 한번에 Build 하기.
- iOS 에서 TensorFlow를 compile 하고 싶다면 다음 스크립트를 활용하자.
tensorflow/contrib/makefile/build_all_ios.sh- 참고로 2013 Macbook-Pro에서 한 20분 걸린다.
- 수동으로 Build 하기
- dependency 가 존재하는 3rd-party library를 사용자가 고려해서 직접 따로따로 Build할 수 있다.
- 먼저 dependency libarary 를 다운받자.
tensorflow/contib/makefile/download_dependencies.sh
- 다음으로 protobuf 빌드가 필요하다.
tensorflow/contrib/makefile/compile_ios_protobuf.sh
- 이제 depencency libarary를 build하였으니 최종 build를 수행한다.
make -f tensorflow/contrib/makefile/Makefile TARGET=IOS IOS_ARCH=ARM64
- 이렇게 하면 최종적으로 다음 파일을 얻을 수 있다. (이게 중요)
tensorflow/contrib/makefile/gen/lib/libtensorflow-core.a*.a파일이 나왔으니 끝난게 아닌가 할 수도 있지만 실제로는 이게 시작.
Optimization
- compile 옵션을 통해 compile 시 사용될 옵션 값들을 조정 가능하다.
$ compile_ios_tensorflow.sh "-Os"
- 좀 더 자세한 내용은 옵션 flag 를 참고하도록 하자.
iOS example
- 이미 TensorFlow 에 iOS용 예제가 들어있다. (
tensorflow/contrib/ios_example)
Raspberry Pi
- TensorFlow 팀에서는 라즈베리파이에서 쉽게 TensorFlow를 돌릴 수 있는 방법을 제공한다.
- 무슨 일인지 모르겠지만 TensorFlow 개발팀에서 라즈베리파이에 꽃힌 것 같다. (대회도 열고 등등..)
pip install을 이용해서 pre-built 된 바이너리 파일을 제공한다.- 가장 손쉬운 방법이므로
pip를 활용하자.
-
물론 다음과 같이 작업을 해도 된다.
- 일단 dependency 라이브러리를 다운받고 필요한 tool 들을 설치한다. (Linux 장비에 받는다.)
$ tensorflow/contrib/makefile/download_dependencies.sh
$ sudo apt-get install -y autoconf automake libtool gcc-4.8 g++-4.8
$ cd tensorflow/contrib/makefile/downloads/protobuf/
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
$ sudo ldconfig # refresh
- 그 다음에 라즈베리파이 모드로 컴파일을 수행한다. (즉, cross-compile을 수행하는 것이다.)
$ make -f tensorflow/contrib/makefile/Makefile HOST_OS=PI TARGET=PI OPTFLAGS="-Os" CXX=g++-4.8
- 라즈베리-2 혹은 라즈베리-3 버전 만을 다룬다면 추가적인 optimizer 를 켤 수 있다.
$ make -f tensorflow/contrib/makefile/Makefile HOST_OS=PI TARGET=PI \\
OPTFLAGS="-Os -mfpu=neon-vfpv4 -funsafe-math-optimizations -ftree-vectorize" CXX=g++-4.8
- 한가지 주의할 점은 GCC 4.9 에서는 약간 문제가 있다는 것이다.
- 참고로 라즈베리파이 Jessie 버전의 이미지는 GCC 버전 중 4.9 가 default 버전이다.
- 이 경우에는
__atomic_compare_exhange에서 에러가 발생한다. - 그래서 위에서는 명확하게
g++4.8을 명시하여 사용한다. - 4.8 써라. 꼭 이거 써라.
- 라즈베리파이용 카메라나 이미지 처리 작업은 다음 경로에서 받도록 하자.
tensorflow/contrib/pi_example
두둥. TenorFlow Library 를 나만의 응용 어플리케이션에 넣어보자.
- 모델을 이용해서 학습을 하고 난 뒤 해야하는 당연한 수순은 자신의 어플리케이션에 이를 통합하는 것.
- 이 말은 TensorFlow 를 하나의 라이브러리로 보고 적당한 헤더를 넣어 컴파일하는 것.
- 즉, Library Linking 단계가 필요하다.
- 하지만 이를 위한 C++ 헤더는 TensorFlow Core에 없다.
- 즉, (라이브러리+노출헤더) 와 같이 간단한 형태로 구성된 최종 산출물을 만들어 낼 수 없다. (헉!)
-
하지만 앞서 공개된 iOS Build 버전이 힌트가 될 수 있다.
- 앞에서 언급한
tensorflow/contrib/makefile/gen/lib/libtensorflow-core.a파일을 다음과 같이 링크한다.-L/your/path/tensorflow/contrib/makefile/genlib/&-ltensorflow-core
- 물론 이것만으로는 해결되지 않는다. (헤더 문제 + dependency lib 문제)
- 먼저 프로토콜 버퍼, 너가 필요하다.
-L/your/path/tensorflow/contrib/makefile/gen/protobuf_ios/lib&-lprotobuf-lite
- Link시 헤더파일이 문제인데 앞서 언급한 3rd-party lib 의 헤더도 필요한 상황이다. 다음을 추가하자.
- 설정할 include 경로에 다음을 추가하면 된다.
tensorflow/contrib/makefile/downloads/protobuf/srctensorflow/contrib/makefile/downloadstensorflow/contrib/makefile/downloads/eigentensorflow/contrib/makefile/gen/proto
- 설정할 include 경로에 다음을 추가하면 된다.
- 모든 Binary 를 강제로 포함하여 빌드하는 옵션이 필요하다.
- iOS 에서는
-force_load라는 옵션이 필요하다. - 이는 각 os 마다 지원되는 방식이 상이하므로 자신의 os 컴파일러에 맞게 찾아봐야 한다.
- Linux 같은 경우 다음과 같이 표현 가능하다.
-Wl, --allow-multiple-definition -Wl, --whole-archive
- iOS 에서는
- 안드로이드는 좀 쉬운데 빌드 jar 파일이 이미 TensorFlow 에 포함되어 있다.
- 만약 없다면 nightly precompiled version 을 찾아보자.
Global Constructor Magic
- 링크시 가장 많이 발생하는 문제가
No session factory registered for the given session options이다. - 이런 에러가 나는 이유를 이해하려면 TensorFlow 내부를 조금 이해하고 있어야 한다.
- TensorFlow는 기본적으로 매우 가벼운 Core 라이브러리를 중심으로 여러 기능들이 모듈러한 형태로 개발되어 있다.
- 필요할 때마다 여러 모듈을 쉽게 섞고 합칠 수 있어야 한다.
- 즉, 모듈 단위로 넣고 빼고 합치고… 하는 작업이 쉬워야 한다.
- 이를 위해 C++ 코드 패턴을 이용해서 각각의 모듈 구현 방식을 정형화시켜놓았다.
- 그리고 이에 맞추어 각각의 라이브러리도 따로 구현해서 업데이트하는 방식을 취한다.
- 필요할 때마다 여러 모듈을 쉽게 섞고 합칠 수 있어야 한다.
- 최종적으로
resistrationpattern을 이용해서 코드들이 구현되어 있다.- 아래 코드를 보자.
class MulKernel : OpKernel {
Status Compute(OpKernelContext* context) { … }
};
REGISTER_KERNEL(MulKernel, “Mul”);
- 이 코드는 독립적인 하나의
.cc파일에 기술되어 최종적으로 여러분의 라이브러리에 링크된다. - 여기서 중요한 부분은
REGISTER_KERNEL()부분으로 MACRO로 구현되어 있다. - 이 매크로에 기술된 함수는 반드시 동일한 파일에 구현체(implements)가 있어야 한다.
- 이 매크로는 대략적으로 다음과 같이 번역된다.
class RegisterMul {
public:
RegisterMul() {
global_kernel_registry()->Register(“Mul”, []({
return new MulKernel()
});
}
};
RegisterMul g_register_mul;
- 즉,
Mul연산에 대해 하나의 Global 변수g_register_mul을 생성하고 이 객체가 생성될 때 생성자에서Mul을 글로벌 레지스터에 등록하게 된다. - 이런 방식은 꽤나 괜찮은 전략이지만 한가지 문제가 있다.
- 만약 TensorFlow를 라이브러리화 하거나 컴파일 할 때에
g_register_mul변수는 생성만 되고 실제 어떠한 작업도 하지 않는다. (생성자 호출이 이 변수의 목적임을 상기하자.) - 따라서 Linker가 동작할 때에는 Binary 파일 생성시 사용하지 않는
g_register_mul객체를 아예 배제하게 된다. - 하지만 나중에 그래프를 구성할 때 사용자가
Mul을 사용하게 되면, TensorFlow는 Global Register 객체에서 이 Op 객체를 찾게 된다. - 이 때
g_register_mul이 코드에서 제거되어 있다면 이 객체의 생성자를 호출하지 않을 것이고 따라서 등록이 되어 있지 않게 된다. - 이런 이유로 TensorFlow 를 외부 모듈에 적재할 때에는 조금 어려움이 따른다.
- iOS에서는
-force_load옵션으로 이를 해결하고 Linux 에서는--whole-archive옵션으로 이를 해결한다.
- 만약 TensorFlow를 라이브러리화 하거나 컴파일 할 때에
Protocol Buffer 문제
protobuf라 불리우는 Protocal Buffer 는 구글이 만든 통신 프로토콜이다.- 이 프로토콜의 문제는 버전 차이로 문제가 발생한다는 것인데, 사용자가 작성한 pb 파일을 어떤 버전으로 생성했느냐에 따라 호환성이 달라지게 된다.
- 예를 들어
protobuf-3.0.1.a로 생성한 pb 파일을 읽어야 하는데 로컬 장비에는 protobuf-3.0.0 이 설치되어 있는 경우에는 지옥이 펼쳐진다. - 최선의 방법은 동일 버전을 사용하는 것.
- 예를 들어
- 또 다른 문제는 TensorFlow에서는 PB 버전을 Build 단계에서 요구한다는 것이다.
- 이 과정은 꽤나 복잡한데 먼저 protobuf 타입으로 정의된 파일을 해석해서 헤더(header) 파일을 만들고 난 뒤,
- 이를 이용해서 실제 컴파일 작업을 수행하게 된다.
- 일단 PB-version 1을 사용하는 경우 TensorFlow에서 사용하는 것은 포기해라.
- 이게 무슨말인고 하니 이미 사용하고 있는 응용 프로그램 에제가 PB-version-1 을 사용중인데,
- 여기에 TensorFlow 모델을 추가로 올릴 수 없다는 이야기다. (TensorFlow는 PB version 2 이상 사용 가능하다.)
- 물론 2/3 버전 호환도 개떡같기 때문에 그냥 동일한 PB 버전을 맞추는게 최고다.
이쯤에서 libtensorflow-core.a 를 만들어보는 예제를 확인하고 가자
TensorFlow API 를 여러분의 프로그램에서 호출하는 법
- 사용 가능한 환경을 갖추게 되면 이제 TensorFlow를 호출해서 사용하고 싶을 것이다.
- 보통 작업은 다음과 같이 진행될 것이다.
- 먼저 여러분이 만든 모델을 응용 프로그램에서 로드한다.
- 입력 데이터를 적당하게 전처리한 뒤 모델 입력에 넣는다. (예를 들면 이미지 등을 전처리 작업한다.)
- 그리고 모델을 구동해서 결과는 얻는다. (예를 들어 이미지 레이블 정보)
- 계속 반복
- 안드로이드의 경우 Java 로 작성된 Inference 용 코드를 제공한다.
- 반면 iOS와 라즈베리파이는 C++ API 를 직접 호출해야 한다.
Android
- 먼저 안드로이드에서 사용하는 inference를 살펴보자.
// Load the model from disk.
TensorFlowInferenceInterface inferenceInterface = new TensorFlowInferenceInterface(assetManager, modelFilename);
// Copy the input data into TensorFlow.
inferenceInterface.feed(inputName, floatValues, 1, inputSize, inputSize, 3);
// Run the inference call.
inferenceInterface.run(outputNames, logStats);
// Copy the output Tensor back into the output array.
inferenceInterface.fetch(outputName, outputs);
iOS
- iOS는 C++이다.
// Load the model.
PortableReadFileToProto(file_path, &tensorflow_graph);
// Create a session from the model.
tensorflow::Status s = session->Create(tensorflow_graph);
if (!s.ok()) {
LOG(FATAL) << "Could not create TensorFlow Graph: " << s;
}
// Run the model.
std::string input_layer = "input";
std::string output_layer = "output";
std::vector<tensorflow::Tensor> outputs;
tensorflow::Status run_status = session->Run({ {input_layer, image_tensor} },{output_layer}, {}, &outputs);
if (!run_status.ok()) {
LOG(FATAL) << "Running model failed: " << run_status;
}
C++
- 사실 일반 데스트탑 레벨에서는 C++ 만 이용해서 TensorFlow 모듈을 다 구현할 수 있다.
- 이 예제는 TensorFlow 내에 포함된
label_image예제를 참고하도록 하자.
Mobile Device 에서도 학습(training)이 가능한가?
- 대부분의 경우 TensorFlow 의 학습은 일반 장비나 클라우드에서 이루어지고 각각의 device에서는 오로지 inference만 수행하는 구조를 취한다.
- 하지만 Federated learning 이라는 방법도 있다.
- 이것은 device 에서 이루어진 학습을 모아서 통합하는 방법이다.
- 실제 구현 예는 Google Keyboard App. 이다.
- 하지만 device에서 학습을 한다는 것 자체는 무척이나 어려운 일.
- TensorFlow는 C++ API 자체에서 auto gradient 기능이 제공되지 않는다.
- 따라서 python 에 포함되어 있는 기능을 가져다 사용하거나,
- C++로 정의된
NodeDef로부터 gradient 를 계산하는GraphDef를 직접 만들어야 한다.
- 또 한가지는 Mobile 환경에서는 traning 용 op 가 지원되지 않으므로 이를 직접 구현해야 한다.
- 먼저 “그럼 mobile에서 지원되는 op는 무엇인가?” 를 알고 있어야 한다.
- 이건 뒤에 설명.
- 먼저 “그럼 mobile에서 지원되는 op는 무엇인가?” 를 알고 있어야 한다.
- TensorFlow는 C++ API 자체에서 auto gradient 기능이 제공되지 않는다.
TensorFlow를 돌리기위한 최소 요구 사양은?
- Mobile Runtime 환경에서 요구되는 최소 리소스 사양은 어떻게 될까?
- 정확히 이야기하기는 어려우나 일단 DSP 나 microcontroller 를 사용하는 Embedding 환경에서는 확실히 돌릴 수 없다.
- 게다가 성능(속도나 연산 가능성 여부)이 주요한 요소이므로 사용자의 어플리케이션 수준에 따라 요구되는 최소 리스스는 달라진다.
- 따라서 정량적인 한계를 바로 찾기는 어렵고, 그냥 제일 간단한 지표로 모델의 FLOPs를 생각해 볼 수 있다.
- 즉, 주어진 모델을 돌릴 때 몇 FLOPs가 소요되는가를 묻는 것이다.
- 예를 들어 최신의 핸드폰은 보통 초당 10 GFLOPs 의 연산 성능을 지닌다.
- 따라서 만약 5GFlOPs 가 소요되는 모델을 사용하고 있다면 초당 2 프레임 처리가 가능하다는 계산이 나온다.
- 하지만 실제 계산 패턴에 따라 이 수치는 변하기 마련이다.
- 모델마다 편차가 달라진다는 이야기는 결국 오래된 핸드폰까지 지원을 하고 싶다면 최대한 최적화를 수행해야 한다는 의미가 된다.
모델을 배포하기
-
모델에 포함된 내용을 device 에 배포하기 위해서는 먼저 어떤 정보가 포함되어 있는지부터 좀 알아야 한다.
- 여러 종류의 Saved File.
- TensorFlow 를 좀 돌려본 사람이라면 모델을
save할 때 여러 종류의 파일이 생겨난다는 것을 안다. - 그리고 대부분
protobuf를 통해 serialize된 형태로 저장되게 된다.
- TensorFlow 를 좀 돌려본 사람이라면 모델을
-
필요한 용어를 먼저 좀 살펴보자.
- NodeDef
- 모델 안에 하나의 연산(operation)으로 정의된다.
- 고유한 이름을 가지며 다음과 같은 정보를 저장하고 있다.
- 다른 노드(node)에 대한 이름 리스트
- 연산자 타입과 구현체 (예를 들어
Add,Mul등) - 연산자 제어를 위한 속성들
- 독특하게
Const라는 연산자는NodeDef에 값을 저장하고 있다.- 보통 정수나 실수, 문자열들을 포함한다.
- 그리고 Tensor 타입 저장도 가능하다.
- CheckPoint
- 데이터를 저장하는 다른 방법은
Variable연산자를 사용하는 것이다.- 하지만
Variable은Const연산자와는 다르게NodeDef에 이 값을 저장하지 않는다. - 따라서
GraphDef파일을 작게 유지할 수 있다. - 대신 실제 데이터 정보는 메모리에 상주하게 된다.
- 그리고 실제 저장이 필요한 경우
Variable에 담긴 값은NodeDef가 아니라CheckPoint에 저장되게 된다. - 학습 중에 업데이트가 필요한 경우 메모리에 있는 값을 변경하게 된다.
- 이는 학습 중에 매우 빈번하게 발생하는 작업이며 분산된 여러 worker에서 자주 접근하게 된다.
- 따라서 weight 업데이트는 time-critical 한 연산이라 할 수 있다.
- 이를 위해 실제 저장을 해야 하는 파일의 포맷은 아주 빠르고 유연한 형태로 구조화되어야 한다.
- 즉, weight 연산을 빠르게 저장, 접근하기 위한 파일 자료구조가 필요하다.
- 하지만
- 이로인해 모델은 여러 버전의 체크 포인트 파일(들)을 가지게 된다.
- 그리고 이 파일은 별도의 API로도 접근 가능하다.
- 저장되는 형식은 다음과 같다.
- 데이터를 저장하는 다른 방법은
/tmp/model/model-chkpt-1000.data-00000-of-00002
/tmp/model/model-chkpt-1000.data-00001-of-00002
/tmp/model/model-chkpt-1000.index
/tmp/model/model-chkpt-1000.meta
- GraphDef
GraphDef는NodeDef의 리스트(list)를 담고 있다.- 그리고 실행을 하기 위한 연산 그래프를 정의하고 있다.
- 학습 과정 중 완전한 그래프 구성을 위해서는 실제 weight 값도 필요하므로 check-point 파일도 함께 로드해서 사용해야 한다. (
GraphDef+CheckPoint)- 효율적인 학습을 위해 선택한 구조이지만 좀 불편하기는 하다. (2 종류의 저장 파일이 필요하다.)
- 학습이 끝난 이후에는 이를 편리하게 사용하기 위해 약간의 꼼수를 사용한다.
- iOS 등에서는
freeze_graph.py를 활용하여 이 문제를 해결한다. - 앞서 언급한
Const연산자를 활용하는 것인데Const연산자는NodeDef에 저장된다는 것을 이용한 것이다. - 학습이 끝난 뒤 모든
Variable노드를Const노드로 바꾸어 그래프를 저장한다.- 이렇게 하면 모든 weight 는
CheckPoint파일이 아닌NodeDef에 저장되게 된다.
- 이렇게 하면 모든 weight 는
- 그리고
GraphDefpb 로 serialize 될 수 있다.
- iOS 등에서는
- FunctionDefLibaray
FunctionDefLibaray는GraphDef에 존재하며 효율성을 위해 저장된 sub-graph 이다.- 입력(input)과 출력(output) 정보를 가지게 되며 기본이 되는 메인 그래프의 op 내에서 선별된 작은 그래프가 된다.
모바일에서 사용 가능한 모델 만들기.
- 학습이 끝난 모델은 2개의 산출물이 생성된다.
GraphDef(보통pb나pbtxt타입의 파일)CheckPointfile
- 이를 하나로 합치는 작업을 수행하여 최종 모델을 만들게 된다.
- 이 과정을
frozen이라고 한다. - 앞서 설명했듯 CheckPoint 에 있는 weight 값을
Const연산으로 변경하여 모두GraphDef로 넣어주는 과정이다. - 이를 위해
freeze_graph.py코드를 사용한다.- 코드는
tensorflow/python/tools/freeze_graph.py에 들어있다.
- 코드는
- 이 과정을
- 대충 이런 식으로 만들어낸다.
$ bazel build tensorflow/python/tools:freeze_graph
$ bazel-bin/tensorflow/python/tools/freeze_graph \
--input_graph=/tmp/model/my_graph.pb \
--input_checkpoint=/tmp/model/model.ckpt-1000 \
--output_graph=/tmp/frozen_graph.pb \
--input_node_names=input_node \
--output_node_names=output_node
- 여기서
input_graph는 반드시GraphDef파일이어야 한다.GraphDef는 2가지 타입 형태로 파일에 저장되기 때문에 (pb또는pbtxt) 추가적인 옵션이 필요하기도 한다.--input_binary=false를 이용해서pbtxt를 입력으로 삼을 수도 있다.
input_checkpoint는 가장 최근에 생성된 check-point 파일을 사용한다.- 보통 full-name 을 기술하기 보다는 prefix 이름으로 기술한다.
output_graph는 저장될 파일의 이름을 기술한다. (frozenGraphDef가 저장된다.)output_node_names는 결과를 얻고자 하는 리스트를 명시한다.- 이 필드는 반드시 필요한데, 이 정보를 바탕으로 freeze 시킬 그래프를 필요한 만큼만 추출해서 구성하기 때문이다.
- TensorFlow가 outut-format을 하도 자주 바꾸기 때문에 (인정) 기타 드물게 사용되는 옵션들은 되도록 쓰지 말도록 하자.
- 예를 들면
input_saver같은 거.
- 예를 들면
유용한 그래프 변환 툴(tool)
- 생각보다 많은 모델 변환 tool이 제공되고 이를 잘 활용해서 Mobile 에 올릴 수 있는 TensorFlow 모델을 구축할 수 있다.
- “최적화시켜서 Mobile에 올리기”라고 생각하면 된다.
학습(training) 시에만 사용되는 노드 삭제하기.
GraphDef에는 training 단계에서만 사용되는 노드에 대한 정보도 함께 포함되어 있다.- 물론 이 노드는 weight 업데이트를 위해서는 반드시 필요한 노드이다.
- 하지만 이런 노드들은 inference 시에는 더 이상 필요하지 않다.
- 이 때 사용할 수 있는 기능이
strip_unused_nodes이다. (이는 Graph Transform Tool 에 포함되어 있다.) - 이 때 입출력 노드를 이해하는 것이 매우 중요한데 Graph Transform 시에 이 입출력 노드를 바탕으로 Path 를 만들기 때문이다.
- 문제는 입출력 노드를 확인하기가 어려운 경우가 있음.
- 무슨 말인고 하니 학습시에는 입력이 Queue 등으로 부터 유입되어 사용자가 직접 입력 노드를 지정하지 않는 경우도 있다.
- 게다가 출력 또한 학습시에는 loss 계산 영역으로 흘러들어가기 때문에 어떤 output 노드가 inference 시 사용되는지 알기 어렵다.
- 그런데 이런 과정을 자동으로 detection 할수는 없음.
- 그래서 사용자가 입출력 노드를 지정하는 것이다.
- 모바일 환경을 생각해보자.
- 대부분의 데이터를 모바일 device 의 메모리로부터 입력 데이터를 받을 수 있다.
- 예를 들면 Inception-v3 모델의 경우 제공되는 구현 방식은
DecodeJpeg연산자를 이용해서 파일명으로 부터 데이터를 입력받게 된다. - 그런다음
BilinearResize연산자로 이미지 resize 후에 얻어진Tensor를 실제 입력으로 사용하게 된다. - Inception Input Module 은 아래 그림을 참고하자.
- 예를 들면 Inception-v3 모델의 경우 제공되는 구현 방식은
- 하지만 모바일에서는 이런 식으로 입력을 받지 않는다.
- 대부분 전처리 과정은 생략되어야 하고 이미지는 모바일에 달려있는 카메라로부터 직접 입력되게 된다.
- 따라서 TensorFlow 를 모바일 버전에서 사용하기 위해서는 TensorFlow 가 Graph 형태로 지원했던 전처리 과정을 직접 사용자가 구현해야 한다.
- 대부분의 데이터를 모바일 device 의 메모리로부터 입력 데이터를 받을 수 있다.
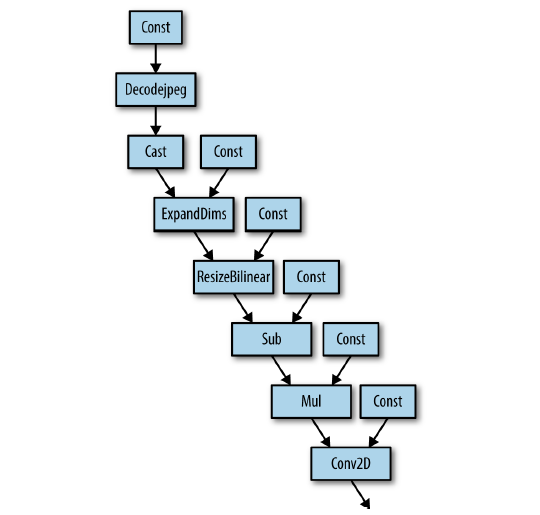
- 현재 사용자에게 단순히
GraphDef파일만 주어진 상태라면summarize_graph라는 tool 을 이용해서 입력과 출력 정보를 찍어보자.
bazel run tensorflow/tools/graph_transforms:summarize_graph --in_graph=tensorflow_inception_graph.pb
- 기존의
GraphDef를 변환하는 Tool는 아래와 같이 사용할 수 있다.
bazel run tensorflow/tools/graph_transforms:transform_graph \
--in_graph=tensorflow_inception_graph.pb \
--out_graph=optimized_inception_graph.pb --inputs='Mul' \
--outputs='softmax' --transforms= \
'strip_unused_nodes(type=float, shape="1,299,299,3") \
fold_constants(ignore_errors=true) \
fold_batch_norms \
fold_old_batch_norms'
모바일 환경에서 사용 가능한 Ops 들은 무엇인가?
- 학습한 모델을 바로 모바일 디바이스에 넣고 돌릴 때 가장 많이 보는 에러는 바로 “
No OpKernal was registered to support Op” 이다.- 즉, 모바일에서 지원하지 않는 Op를 사용하고 있다는 것이다.
- 이 때 가장 먼저 해야 할 일은
strip_unused_nodes이다.- 에러가 나오는 Op가 strip으로 날라가기만 하면 해결되는 문제가 아니던가!!
- 하지만 이 작업을 마친 후에도 동일한 메시지를 얻는다면 다음을 고민해보자.
- 먼저 op 를 다음 4가지 중 하나의 카테고리로 분류해볼 수 있다.
- 이게 Backprop 시 사용되는 op인가? 즉, training 시에만 사용되는 op 인가? (이건 날려도 된다.)
- Backprop에 사용되는 op는 아니지만 inference 에서는 필요가 없는가? (CheckPoint 관련 op 등) (이것도 날려도 된다.)
- 진짜 모바일에서 사용이 불가능해서 그런건 아닌가? (예를 들면
DecodeJpeg노등 같은) - 혹시 거의 사용하지 않는 타입(type)을 사용하는 op인가? (예를 블면 boolean 을 입출력으로 사용하는 op)
- 일반화시킨 TensorFlow 버전에서는 모든 사용자 요구사항을 만족시키기 어렵다.
- 그래서 만약 사용자가 어느 정도 제어를 하기 원한다면 추가적으로 build 작업을 좀 수행해 주어야 한다.
- Op를 포기하던지 아니면 어떻게든 포함 시키던지…
구현체(implementation) 위치
- 연산자(Operation)는 구현시 크게 2가지 파트로 나뉘게 된다.
- op definition : 연산자에 대한 signature 라고 생각하면 된다. 크기가 작으므로 라이브러리에 모두 포함되게 된다.
- op implementation : 실제 구현 코드. 대부분
tensorflow/core/kernels하위 디렉토리에 구현되어 있다.- 만약 C++ 을 컴파일할 때에 실제 필요한 연산을 제어할 수 있다.
- 예를 들어
Mul이라는 연산은 실제로tensorflow/core/kernels/cwise_op_mul_1.cc에 기술되어 있다.- 만약 코드 상에서 검색 등을 해보고 싶다면 다음과 같이 하도록 하자.
$ grep 'REGISTER.*"Mul"' tensorflow/core/kernels/*.cc
필요한 연산자를 Build시 추가하기.
- 만약 Bazel 을 쓰고 있다면 필요한 파일을 적절한 위치의 build 파일에 기술하면 된다.
- 만약 makefile 을 쓰고 있다면
tensorflow/contrib/makefile/tf_op_files.txt에 추가로 기술하고 빌드하면 된다.
최적화 (응답속도, 메모리, 모델 파일 크기, Binary 크기)
- 지금부터는 최적화 내용을 다루도록 하자.
모델의 크기
- device에 여러분의 모델을 올리려면 모델의 크기가 주요한 이슈가 된다.
- 왜냐하면 보통 큰 네트워크 모델은 몇백메가 정도 되기 때문이다.
- device에 충분한 여유가 있다면 뭐 큰 상관은 없을 것이지만 현실은 녹록치 않다.
- 당연히 크기를 줄여야 한다.
GraphDef를freeze_graph와strip_unused_nodes작업 후 크기를 좀 살펴보자.
bazel build tensorflow/tools/graph_transforms:summarize_graph \
&& bazel-bin/tensorflow/tools/graph_transforms/summarize_graph \
--in_graph=/tmp/tensorflow_inception_graph.pb
- 결과
No inputs spotted.
Found 1 possible outputs: (name=softmax, op=Softmax)
Found 23885411 (23.89M) const parameters, 0 (0) variable
parameters, and 99 control_edges
Op types used: 489 Const, 99 CheckNumerics, 99 Identity,
94 BatchNormWithGlobalNormalization, 94 Conv2D, 94 Relu,
11 Concat, 9 AvgPool, 5 MaxPool, 1 Sub, 1 Softmax,
1 ResizeBilinear, 1 Reshape, 1 Mul, 1 MatMul, 1 ExpandDims,
1 DecodeJpeg, 1 Cast, 1 BiasAdd
- 여기서
Const연산자의 수가 매우 중요하다.- 대부분의 경우 이 연산의 타입은
float32이다. - 그래서 이 값(Const 갯수)에 4를 곱하면 대충 전체 파일 크기를 가늠할 수 있다.
- 대부분의 경우 이 연산의 타입은
- 파일 크기를 줄이는 방법은
quantize_weights이다.
bazel build tensorflow/tools/graph_transforms:transform_graph \
&& bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
--in_graph=/tmp/tensorflow_inception_optimized.pb \
--out_graph=/tmp/tensorflow_inception_quantized.pb \
--inputs='Mul:0' \
--outputs='softmax:0' \
--transforms='quantize_weights'
- 파일 크기를 살펴보면 최초 파일의 1/4 정도로 줄게 된다. (처음 크기는 23M 이었다.)
- 일반적으로
float타입의 데이터는 잘 압축되지 않는다.- 실수 값이 조금만 차이가 나도 실제 저장되는 형식 데이터는 크게 다르게 되므로 압축이 어려워진다.
round_weights등도 단순하게 round 하는 방식이지만 압축율을 크게 높일 수 있다.- 실제로는 실수 값으로 (4byte) 저장되지만 압축시 더 좋은 효율로 압축할 수 있다.
속도
- 당연히 속도가 중요하다.
- 속도는 벤치마크 tool 로 확인 가능하다.
bazel build -c opt tensorflow/tools/benchmark:benchmark_model \
&& bazel-bin/tensorflow/tools/benchmark/benchmark_model \
--graph=/tmp/inception_graph.pb --input_layer="Mul:0" \
--input_layer_shape="1,299,299,3" --input_layer_type="float" \
--output_layer="softmax:0" \
--show_run_order=false --show_time=false \
--show_memory=false --show_summary=true --show_flops=true \
--logtostderr
- device 마다 처리되는 속도가 다르다. (아까 설명했다.)
- 2016년 상급 폰이 대충 초당 20 billion FLOPs 정도 나온다.
- 따라서 모델이 대충 10 billion FLOPs 정도 성능이 나온다면 이 폰에서는 초당 2번 처리가 가능하다.
프로파일 (Profile)
- 이건 그냥 문서를 참고하자. (정리하기가 귀찮다.)
- 위 benchmark tool 를 쓰면 대충 망 내부의 세부 성능을 확인 가능하다.
- 작성한 모델을 프로파일링하는 것은 그냥 예제만 보고 넘기자.
tensorflow::StatSummarizer stat_summarizer(tensorflow_graph);
tensorflow::RunOptions run_options;
run_options.set_trace_level(tensorflow::RunOptions::FULL_TRACE);
tensorflow::RunMetadata run_metadata;
run_status = session->Run(run_options, inputs, output_layer_names, {}, output_layers, &run_metadata);
assert(run_metadata.has_step_stats());
const tensorflow::StepStats& step_stats = run_metadata.step_stats();
stat_summarizer->ProcessStepStats(step_stats);
stat_summarizer->PrintStepStats();
Visualizing Models
- 모델 코드를 효율적으로 구성하기 위해 가장 먼저 해야 할 일은 여러분의 모델을 이해하는 것이다.
- 이를 위한 첫 발자국은 모델을 눈으로 확인하는 것이다.
- 그래프 전체를 조망하기 위한 방법으로 Viz’ Dot 을 사용하면 된다.
bazel build tensorflow/tools/quantization:graph_to_dot
bazel-bin/tensorflow/tools/quantization/graph_to_dot \
--graph=/tmp/tensorflow_inception_graph.pb \
--dot_output=/tmp/tensorflow_inception_graph.dot
Threading
- 데스크탑 버전의 TensorFlow에서는 threading 모델이 적용되어 있다.
- 이 말은 병렬적으로 여러 Operation을 수행 가능하다는 의미이다.
- 두가지 parallelism 이 지원된다.
- inter-op
- intra-op
- inter-op
- 특별히 세션(session) 옵션에 설정되는
interop_threads를 의미한다. - 한번에 돌아가는 최대 op 개수를 의미한다.
- 보통 모바일 환경에서는 이 값이 1로 설정되어 있다.
- 이런 경우 순차적으로 작업이 수행된다.
- 왜냐하면 모바일에는 cache가 충분하지 않아서 동시에 돌리면 더 손해다.
- 참고로 엄밀하게 말하면 excutor 하나당 할당되는 thread-pool 크기다.
- 특별히 세션(session) 옵션에 설정되는
- intra-op
- 하나의 op들을 여러 thread로 실행.
- 사실 이해하기 어려운데 쉽게 생각하면 내부에서 Eigen 연산 하나에 적용될 thread 개수를 의미한다.
- 예를 들어 Eigen에서는 큰 행렬 두개를 곱할 때 thread로 나누어 연산이 가능하다.
Binary Size
- 모바일 환경과 서버 환경의 가장 큰 차이는 binary 크기이다.
- 서버 환경에서 몇 백메가 정도 쓰는건 이상한 일이 아니지만 모바일 환경은 다르다.
- TensorFlow에서는 모바일에서만 사용할만한 볼륨으로 컴팩트하게 만들지만 그래도 12MB나 된다.
- 따라서 가장 좋은 방법은 실제 모델에서 사용하는 코드만 추가하는 것.
python tensorflow/python/tools/print_selective_registration_header.py --graphs="xxx.pb" > ops_to_register.h"
- 이렇게 만들어진
ops_to_register.h헤더를 삽입하여 코드를 재컴파일 한다.
cp ops_to_register.h tensorflow/core/framework/
- bazel로 빌드할 때
--copts=-DSELECTIVE_REGISTRATION추가 - android studio로 빌드할 때
- build.gradle 파일의 buildNativeBazel > commandLine 에
--copts=-DSELECTIVE_REGISTRATION추가
- build.gradle 파일의 buildNativeBazel > commandLine 에
메모리 적제 문제.
- device에서 여러번 모델을 적재해야 하는 경우가 발생할 때.
- 그런데 사실 이건 서버 환경에서도 고민을 해봐야 하는 문제이기도 함.
- 내용이 주저리주저리 많으나 그냥 mmap 을 지원한다는 내용이다.
- mmap 적용이 가능한 모델을 구성하기 위해
tensorflow/contrib/convert_graphdef_memmapped_formatTool을 이용한다. - 하지만 이렇게 되면 더 이상 표준적인
GraphDef파일로 저장되지는 않는다. - 따라서 별도의 Loading 코드가 필요하게 된다.
- 로링 코드는 교재를 참고하자.
모델 보호
- 기본적으로 모델을 저장할 때 표준적인 방식으로 protobuf를 serialze 해서 저장한다.
- 하지만 상업용 모델의 경우 weight 를 제공하고 싶지 않은 경우가 있다.
- 이 때 암호화 기법을 사용하면 된다.
- 적당히 encoder, decoder를 만들면 된다.
- protobuf 타입의 파일을 암호화하는 방법을 다룬다.
Status ReadEncryptedProto(Env* env, const string& fname,
::tensorflow::protobuf::MessageLite* proto) {
string data;
TF_RETURN_IF_ERROR(ReadFileToString(env, fname, &data));
DecryptData(&data); // Your own function here.
이런 식으로 사용하면 적당히 해결된다.
Quantization
- 사실 가장 중요한 부분이다.
- 이에 대한 흥미로운 논문들이 많이 나와 있다.
- 기본적으로 손실을 최소화하면서 실수(float32) 값을 8bit 데이터로 변형하는 내용들이 많았다.
- 앞서
quantize_wieghts를 좀 살펴보았다.- 마찬가지로 이것도 실수를 8-bit 정수 값으로 변경하는 기법이다.
- 쓸데없는 이야기가 많으니 다 생략하자.
Quanized Representation
- 우리는 매우 큰 실수 array를 다루고 있다.
- 따라서 이 실수 값의 분포를 활용해서 인코딩하는 기법을 다룬다.
- 예를 들어 다음과 같은 데이터가 있다고 해보자.
[-10.0, 20.0, 0]
- 이 array를 스캔하면 min 값은 -10.0이고 max 값은 20.0 이다.
- 이 두값을 서로 뺀 뒤 normalize한다. norm 크기는 달라질 수 있지만 일단 256개로 해보자.
- 그럼 일정한 크기의 구간으로 변경할 수 있다.
[((-10.0 - -10.0) / 30.0) * 255, ((20.0 - -10.0) / 30.0) * 255, ((0.0 - -10.0) / 30.0) * 255]
- 짜잔 결과는 다음과 같다.
[0, 255, 85]
- 원래 있던 값을 min/max 를 이용해서 인덱스화 했다.
- 다시 복원하기 위해서는 원래 사용했던 min/max 값만 알면된다. (norm 크기는 고정이라고 가정)
- 물론 손실 복원이다.
-
이제 원래 모델에 2개의 Tensor만을 추가함으로써 (min/max용) 원래 값들을 int8 타입으로 변경 가능하다.
- 이런 이야기만 들으면 다 해결된 것 같다.
- 하지만 현실은 언제나 그렇지 않다는 걸 잘 안다.
- 가장 큰 문제로 0의 존재.
- 값 0.0 은 정확도에 가장 영향을 많이 주는 요소이다.
- 왜냐하면 Relu 등을 통과할 때 음수는 모두 0이 되기 때문이다.
- 문제는 이러한 indexing화를 거치고 난 뒤 복원되면 0.0의 값은 0.1 등의 0과는 매우 가깝지만 0은 아닌 값이 될 가능성이 크다.
- 이런 경우 정확도가 대폭 떨어진다.
- 다른 문제로 min과 max 값이 같다거나 min이 max 보다 더 큰 상황이 생길 수 있다.
- 이건 부호 문제일 가능성이 크다. (오버플로우, 언더플로우)
- 해결 방법은 1을 더한 값을 인코딩한다. (대충 될 것 같은데 귀찮아서 생각 정지 후 넘김.)
- 0의 부정확성 문제는 구간을 나누어 본다.
- 음수~0, 0~양수 로 두 구간을 나누고 127 단계로 분할한다.
- 어쨋거나 0을 잘 살리도록 노력. 그리고 혹시나 min~max 사이의 값이 너무 작다면 작은 단위로 나눈다. (?)
- 뭐 여러가지 노력을 하고 있다.
- 음/양 나누어진 구간을 symetric 하게 만든다거나 등.
TensorFlow에서 Quantize 하는 방법
- graph transform tool에 포함된
quantize_nodes옵션을 사용한다. - 일단 다음 연산에 대해서만 수행한다. (이건 업데이트 될 수도 있는 내용이다. 언제나 최신 문서를 참고하자.)
BiasAdd,Concat,Conv2D,MatMul,Relu,Relu6,AvgPool,MaxPool,Mul
- 그런데 이것 만으로 Inception 등은 거의 전체를 충분히 Quantize 가능하다.
- 만약 다음과 같은 그래프가 있다고 해보자.
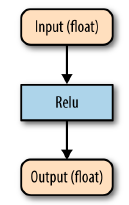
- 이를 다음과 같이 변경하게 된다.
quantize_nodes옵션을 사용한다.
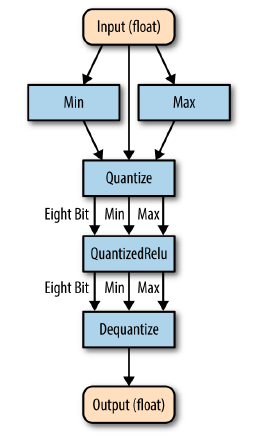
- 이것 말고도 그래프 최적화 방법은 추가적인게 더 있다.