Introduction
- 최근 web-scale의 데이터를 이용하여 weakly supervised learning 을 시도하는 경우가 많아졌다.
- 하지만 데이터 노이즈(noise), 레이블 정보 누락, 잘못된 레이블 등으로 인해 특정한 조건 외에서는 대부분 성능이 좋지 못했다.
- 이 논문에서는 약 10억개의 unlabeled image를 이용하여 분류 문제에 적용해본다.
- 지금까지는 이 정도의 규모를 이용하여 semi-supervised learning 을 처리한 적이 없었다.
- 이를 위해 아주 간단한 방식의 학습 방법을 제시한다.
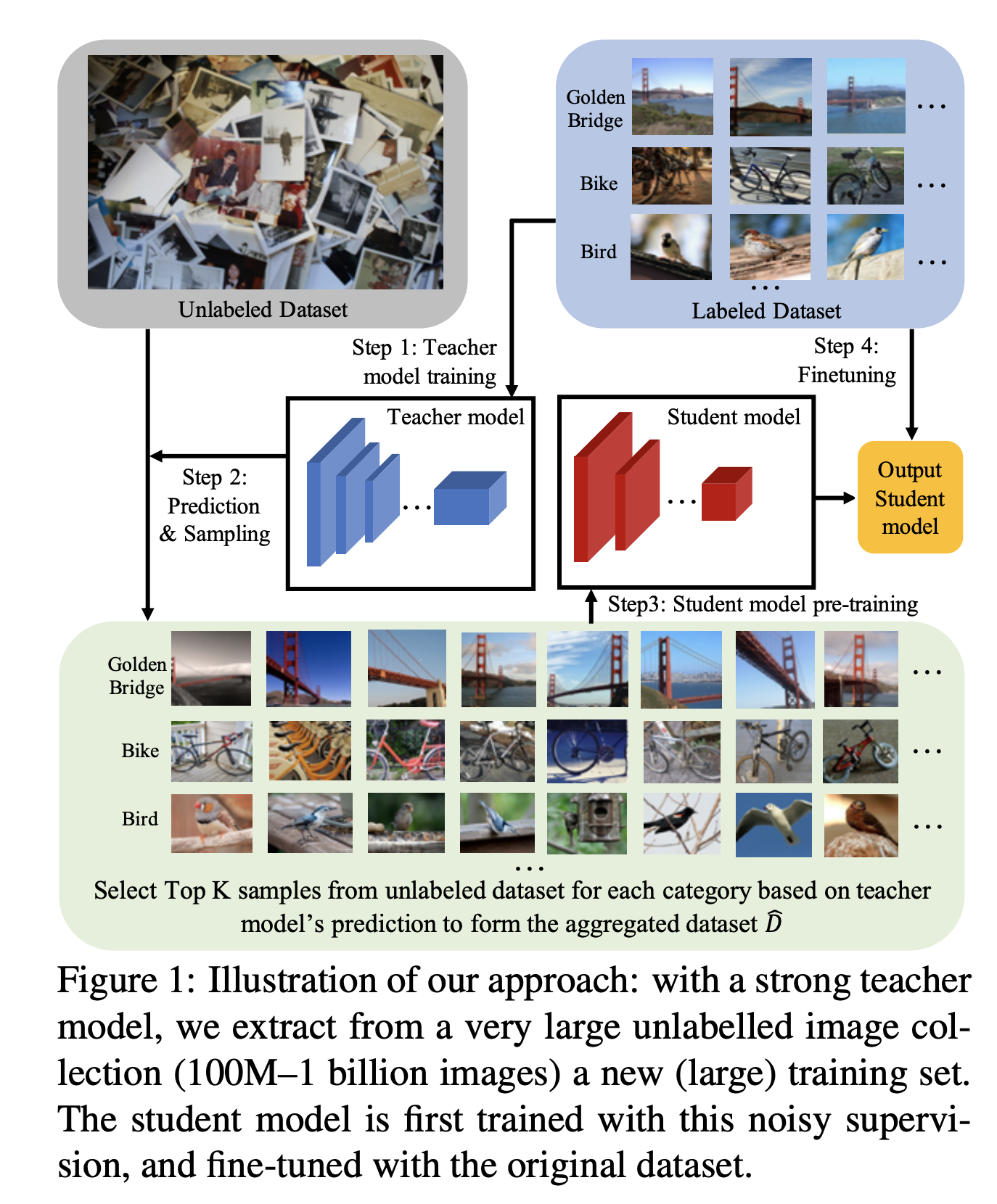
- 작업 절차
- Labeled Image 학습 데이터로 Teacher 모델을 학습한다.
- Teacher 모델을 이용하여 Unlabeled Image 데이터를 추론(inference)하여 top-K 이미지를 뽑아 새로운 학습 데이터를 생성한다.
- 이 데이터를 이용하여 Student 모델을 학습한다.
- 학습된 Student 모델에 처음 사용했던 Labeled Image 학습데이터로 Fine-tuning 을 수행한다.
- 다른 weakly-supervised 방식과 다른 점은, 모든 레이블마다 동일한 수의 학습용 이미지 데이터를 만들어낸다는 것이다.
- long-tail distribution 문제를 해결한다.
- 예를 들어 “Africal Dwarf Kingfisher” 라는 새(bird) 클래스는 tail class 에 속한다.
- 보통의 경우 weakly-supervised learning 에서는 이 클래스에 대한 학습이 어렵다.
- 하지만 매우 큰 수의 unlabeled 데이터에서는 이 데이터를 추출할 수 있다.
- 이 논문의 공헌(contribution)
- 10억 단위의 unlabeled 이미지를 활용하여 semi-supervised 학습을 수행하고 이로부터 좋은 성능의 모델을 얻을 수 있음을 확인.
- 이전 작업물에 영감을 받아 대량 이미지로부터 이미지 분류를 잘 할 수 있는 전략들을 제시하였다.
- 다양한 모델 디자인 전략을 제시하여 구체적인 분석 결과를 제시하였다. (실험 참고)
- 일반적으로 사용하는 모델들과 비교를 통해 이 방식이 SOTA임을 보였다.
- 제시한 방식이 FGIR 과 같은 다른 task 에서도 잘 통한다는 것을 확인하였다.
- 대규모 Semi-supervised learning을 위한 제언 (table.1)
- KD 러닝을 사용해라. (teacher/student 모델)
- 고정된 복잡도(fixed complexity) 를 사용할 수 있다.
- 심지어 teacher, student를 동일한 모델도 사용 가능하다.
- 정답 Label 데이터로 fine-tuning 을 해라.
- 대규모 Unlabeled 데이터가 성능의 핵심 요소이다.
- pre-traning 시에 많은 iteration 을 수행해라.
- vanilla 모델과 비교하여 충분히 더 많은 학습 시간을 소요
- label 을 만들 때 balanced distribution 으로 데이터를 생성해라.
- weak-supervision 을 이용해서 teacher 모델을 pre-training 하면 더 좋은 성능을 얻는다.
- KD 러닝을 사용해라. (teacher/student 모델)
Related Work
- Image classification
- 목표는 이미지 분류 문제.
- 최근 연구로는 인스타그램 해쉬 태그를 이용하여 pre-training 을 하는 방식 도 있다.
- Transfer learning
- 대규모 데이터로 pre-training 된 모델을 다시 풀고자 하는 문제의 데이터로 fine-tuning 하는 방식
- 추가로 unlabeled image 로 pre-training 을 하는 방법이나 low-shot learning 과 관련된 연구도 존재.
- Semi-supervised learning
- 최근 unlabeled 데이터를 기존 데이터에 추가하여 성능을 올리는 연구들이 나오고 있다.
- Distillation
- Tearcher/Student 모델
- Data Augmentation
- 이미지 분류에서 입력 이미지 데이터에 augmentation을 가해 일반화 성능을 올리는 것.
논문에서 사용된 학습 Pipeline
- 4개의 stage 로 구성된다.
- teacher 모델을 training 데이터 \(D\) 로 학습
- unlabeled 데이터 \(U\) 를 teacher 모델에 돌린 뒤 연관된 이미지 샘플을 추출하여 새로운 데이터 \(\hat{D}\) 를 생성
- 데이터 \(\hat{D}\) 를 student 모델로 학습
- 최초 데이터 \(D\) 로 student 모델을 fine-tuning.
- Data selection & labeling
- \(\hat{D}\) 데이터 생성시 목표는 noise 레이블을 최대한 없애는 것.
- 대용량 데이터이기 때문에 개별 클래스 데이터를 모으기에는 충분한 양이다.
- 여기서의 접근 방법은 각각의 target label에 대해 top-K 를 모으는 것이다.
- 먼저 teacher 모델은 각 이미지에 대해 softmax 결과를 내어놓는다.
- 이 중 가장 높은 P개의 score 를 가지는 레이블에 대해서만 값을 남긴다.
- P 는 어떻게 결정하는 것일까?
- 논문 뒷편에 간단한 실험을 두고 있다.
- 실제로는 어떠한 P 값을 사용하더라도 큰 차이는 없다. 논문에서는 그냥 \(P=10\) 을 사용.
- 각 클래스별로 top-K 개의 이미지를 선정하여 학습 데이터로 구성한다.
- \(K\) 에 대한 값도 간단한 실험을 통해 추출 (하이퍼 파라미터다.)

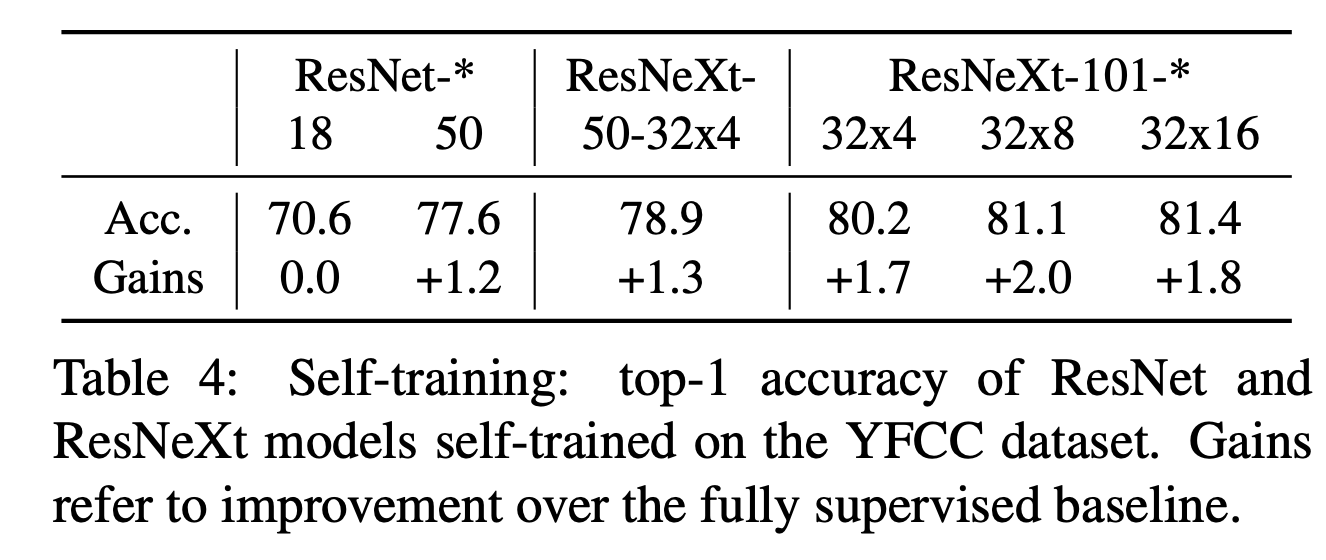
- YFCC 100M 데이터에 대해 ResNet-50 teacher 모델을 평가한 결과이다.
- teacher 모델은 5개의 클래스에 대해 ImageNet-val 로 학습한 모델이다. (정확히 무슨 의미인지 모르겠다. 진짜 이렇게 학습을 한것일까?)
- \(K\) 값을 어떻게 선정하느냐도 매우 중요. (뒤에 개별 실험을 한다.)
Student model
- 먼저 \(\hat{D}\) 데이터로 student 모델을 학습한다.
- 여기서 심지어 teacher 모델과 student 모델의 아키텍쳐가 동일해도 상관 없다.
- 이 때에는 multiple label 로 데이터를 활용한다.
- 이후에 원래 데이터인 \(D\) 데이터로 fine-tuning 을 수행한다.
- 학습 방법은 이전 teacher 모델에서 사용한 방식과 동일하다.
- 여기서 간단히 아이디어를 낸다면 \(D\) 와 \(\hat{D}\) 를 섞어 학습하는 방법도 고려해 볼 수 있다.
- 하지만 이러헥 하면 최적의 파라미터를 다시 구해야만 하는 불편함이 있다.
- 그냥 편하게 나누어 학습하면 이미 이전에 선정한 최적의 파라미터 값을 그대로 사용해도 된다.
Bonus
- 조금 더 특별한 방식으로 다음과 같은 작업을 수행한다.
- labeled data \(D\) 에 weakly-supervised data \(W\) 를 추가.
- 여기에 task-specific 데이터 \(V\) 를 추가한다.
- teacher 모델을 \(W\) 로 학습하고 \(V\) 로 fine-tuning
- 이전 연구에 따르면 이런 방식이 성능 향상을 가져온다.
실험 : 이미지 분류 문제
- 이미지넷1K 데이터로 실험을 수행한다.
- 데이터가 1K 라는 의미가 아니고 2012 이미지넷 데이터를 말하는 것 같다.(클래스 갯수가 1K)
환경 설정
Dataset
- YFCC-100M
- 약 9천만 개의 Flickr 이미지로 관련 태그가 부착되어 있다.
- 중복된 이미지를 제거 후 사용하였다.
- IG-1B-Targeted
- 10억 크기의 공개 이미지를 모은 데이터로 해쉬 태그가 부착되어 있다.
- 우선적으로 약 1500개의 해쉬 태그를 표기한 이미지를 추출한다.
- 1500개의 태그는 ImageNet1K 데이터의 레이블과 관련이 있는 키워드이다.
- 1000 class 의 ImageNet 데이터는 당연히 데이터 \(D\) 로 사용한다.
Model
- Teacher와 Student 모델 모두 Resnet 계열의 모델을 사용한다.
- ResNet-d ( \(d={18, 50}\) )
- ResNeXt-101 ( \(32XCd\) with 101 layers, \(C={4, 8, 16, 48}\) )
- ResNeXt-40 ( \(32x4\) )
- 학습 디테일
- SGD 를 사용
- 64 GPU (8개의 GPU 가 1대의 장비에 설치)
- 각 GPU 마다 24개의 batch 이미지를 사용 (64 * 24 = 1536)
- 모든 Convolution 연산에 BN 적용
- 0.0001 weight decay parameter
- Pre-training
- warm-up (from \(0.1\) to \(0.1/256 \times 1536) lr
- lr 은 한번 떨어질 때 2배씩 감소하도록 사용
- Fine-tuining (ImageNnet)
- lr : \(0.00025/256 \times 1536\)
- 3번 lr 을 감소한다. (30 epoch 당 1회씩 0.1 을 곱함)
Defalut param
- 학습을 얼마나 진행해야 하는가? (iteration 문제)
- \(n\;iter = 1B\) 가 기준
- \(P=10\) , \(K=16k\) 로 \(\hat{D}\) 데이터를 구성한다.
- 기본 teacher 모델은 ResNext-101 모델
- 기본 student 모델은 ReNet-50 사용
- unlabeled data \(U\) 는 YFCC100M 을 기본으로 사용.
분석
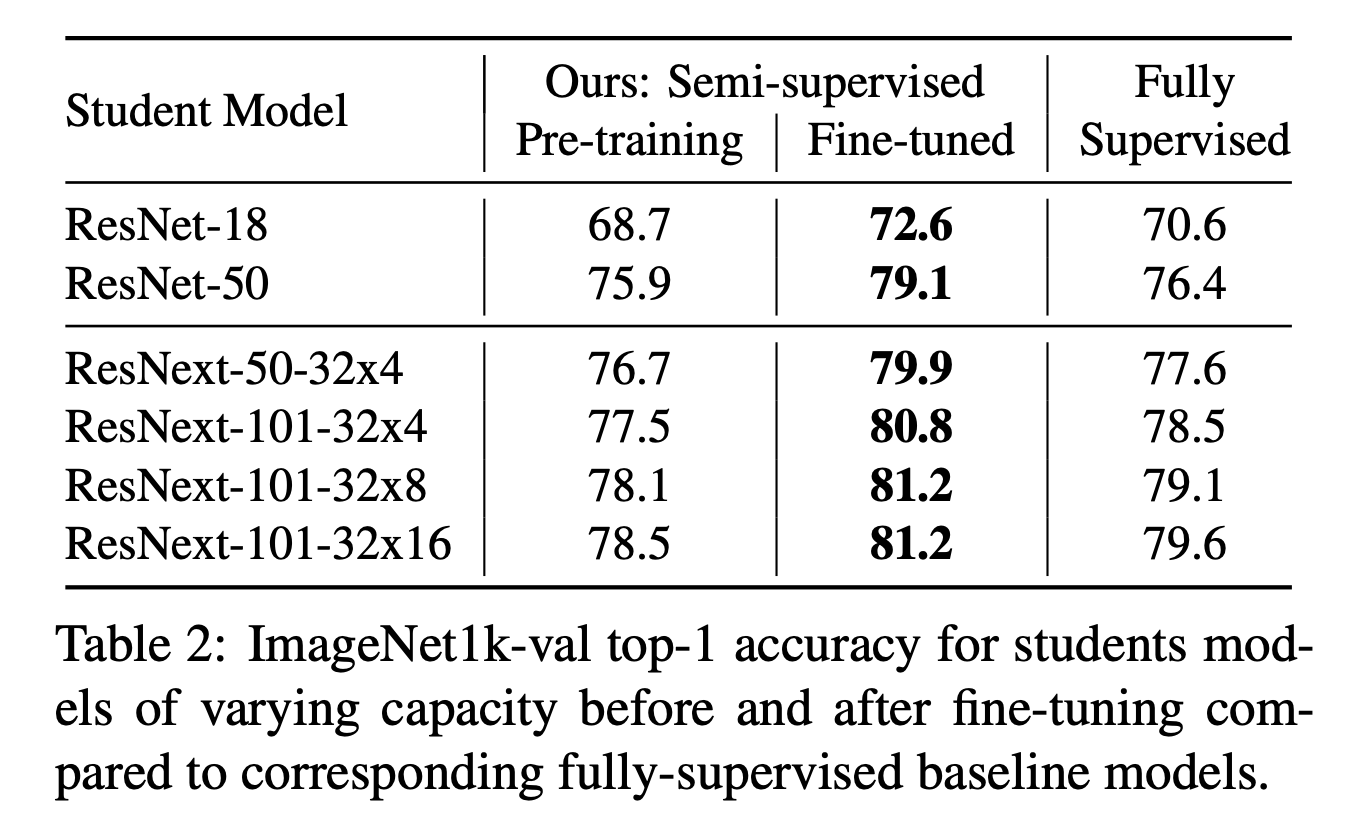
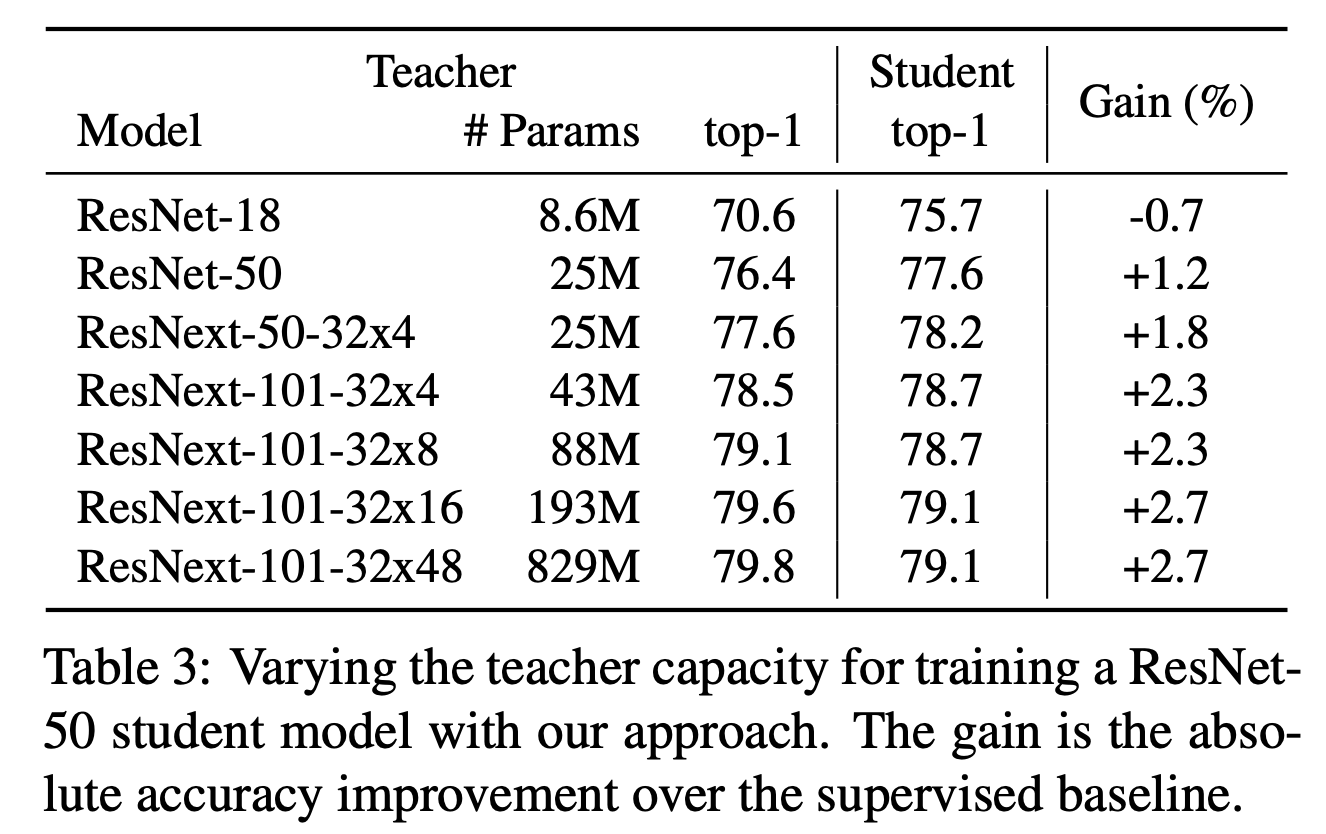
- 논문 vs. Supervised learning
- Table.2 를 보면 ImageNet 을 fully supervised learning 한 결과보다 성능이 더 좋다.
- fine-tuning 의 중요성
- Table.2 의 결과를 보면 Fine-tuning 의 중요성을 알 수 있다.
- Teacher, Student 모델의 capacities
- Table.2 를 보면 student 모델의 capacity 에 따른 성능 변화를 확인할 수 있다.
- 또한 Table.3 을 보면 teacher 모델의 capacity 에 따른 성능 병화도 확인할 수 있다.
- capacity 가 높은 모델일수록 더 좋은 성능을 낸다.
- 하지만 teacher 모델은 student 모델보다 더 높은 capacity 를 가져야 의미가 있다.
- Student 와 Teacher 를 동일하게 사용했을 경우의 성능 이득
Parameter 관련
- unlabeled data \(U\) 의 크기 문제
- YFCC100M 을 랜덤 샘플링하여 크기를 조절해가면서 실험한다.
- \(U\) 의 크기는 \(K\) 에도 영향을 미치므로 알맞게 조절한다.
- \(K\) 의 값이 \(16k, 8k, 4k\) 에 대해 데이터 크기를 \(100M, 50M, 25M\) 으로 설정
- 그림.3 에 결과를 표시하였다.
- \(25M\) 에 접근할 때까지 선형 증가한다. 이후로는 log-linear 증가.
- Pre-training iteration 횟수
- 그림.4 에서는 학습 iteration 에 따른 성능 측정을 보여준다.
- lr drop 은 모든 경우 동일하게 적용하였다. (13개의 구간으로 나누고 2배씩 drop)
- 비교를 위해 ImageNet 을 학습하는 것을 비교해 놓았다.
- 최종적으로는 성능과 리소스 사용의 타협점을 택해 1B 를 사용하였다.
- Parameter \(K\) 와 \(P\)
- 그림.5 는 최적의 \(K\) 값을 구하는 것을 나타내는 그림이다.
- 여기서 \(P=10\) 으로 고정하여 사용한다. (사실 \(P\) 에 대한 영향도는 작다.)
Semi-weakly supervised 실험
- 이전 논문 에서 성능 향상을 위해ㅔ 수행했던 실험들을 여기에도 적용해 본다.
- 한 가지 방법은 클래스와 관련있는 hashtag 정보를 이용하여 weakly-supervised dataset \(U\) 를 생성하는 것이다.
- 이를 위해 \(IG-1B-Targeted data\) 로 부터 데이터를 추출한다.
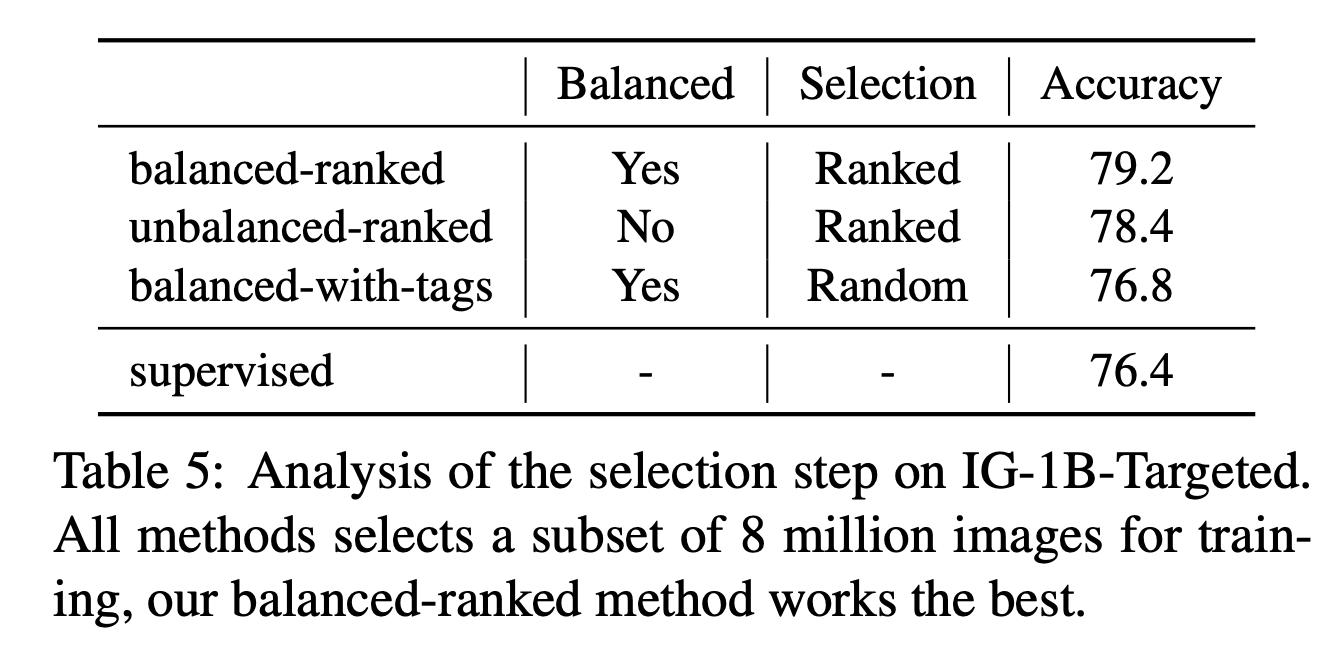
- 총 3개의 subset을 구성한다. (각각 800만개의 데이터를 구성)
- (1) balanced-ranked
- 앞서 사용한 방법으로 top-8k 데이터를 추출
- (2) unbalanced-ranked
- 동일한 방법이지만 Zipfian 분포를 이용하여 unbalanced 데이터를 추출
- (3) balanced-with-tags
- 클래스와 관련있는 해쉬태그가 달린 이미지로부터 랜덤하게 8K 데이터를 추출
- (1) balanced-ranked
hashtags 를 이용하여 pretraining 하기
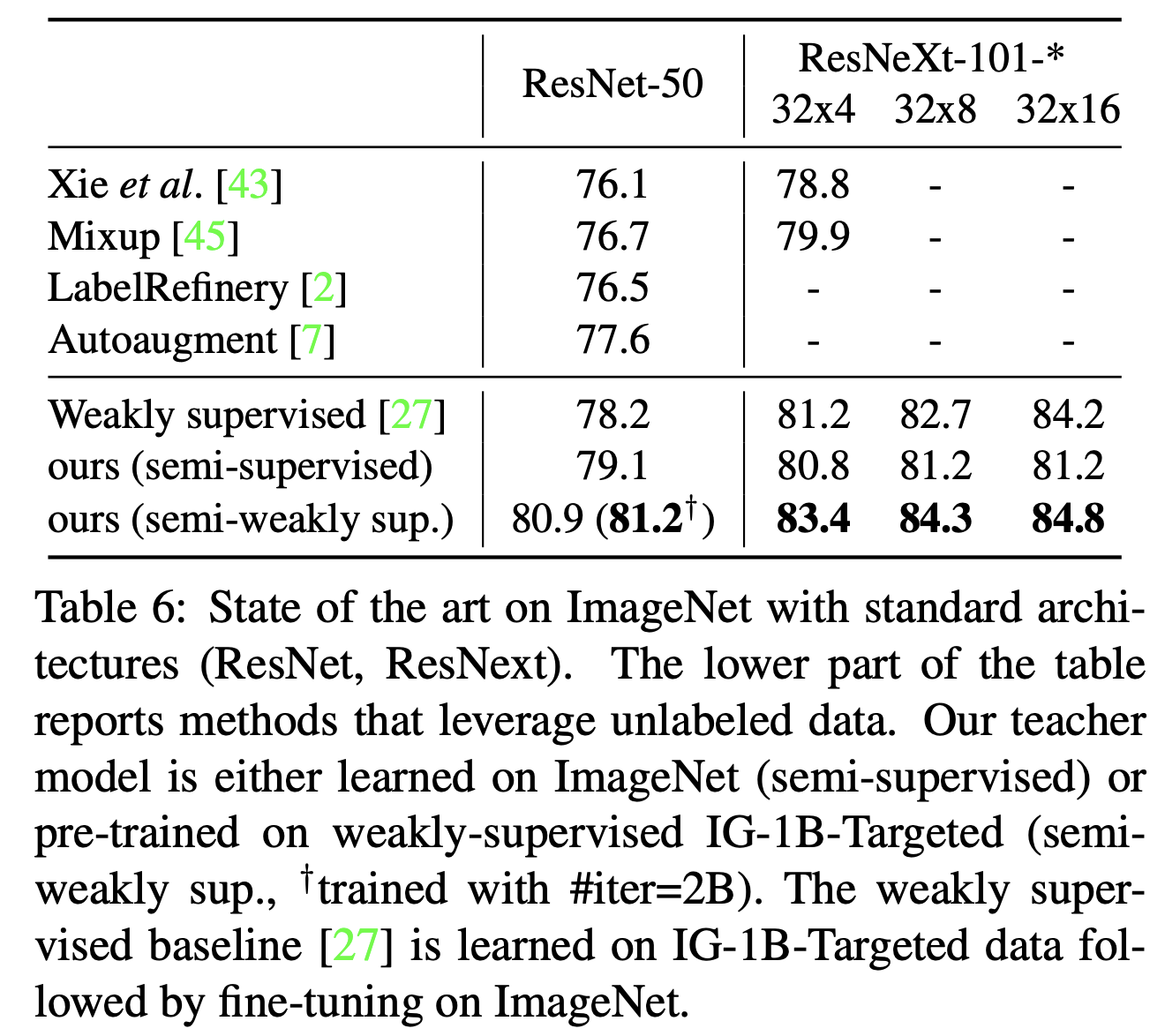
- 이전 연구에 영감을 얻어 실험.
- 일단 85.4% top-1 정확도를 가지는 ResNext-101 를 teacher 모델로 삼는다.
- pre-trainind 데이터로 IG-1B 를 사용하고 ImageNet 으로 fine-tuning 한다.
- \(K=64k\) 를 사용한다.
다른 분야에 적용
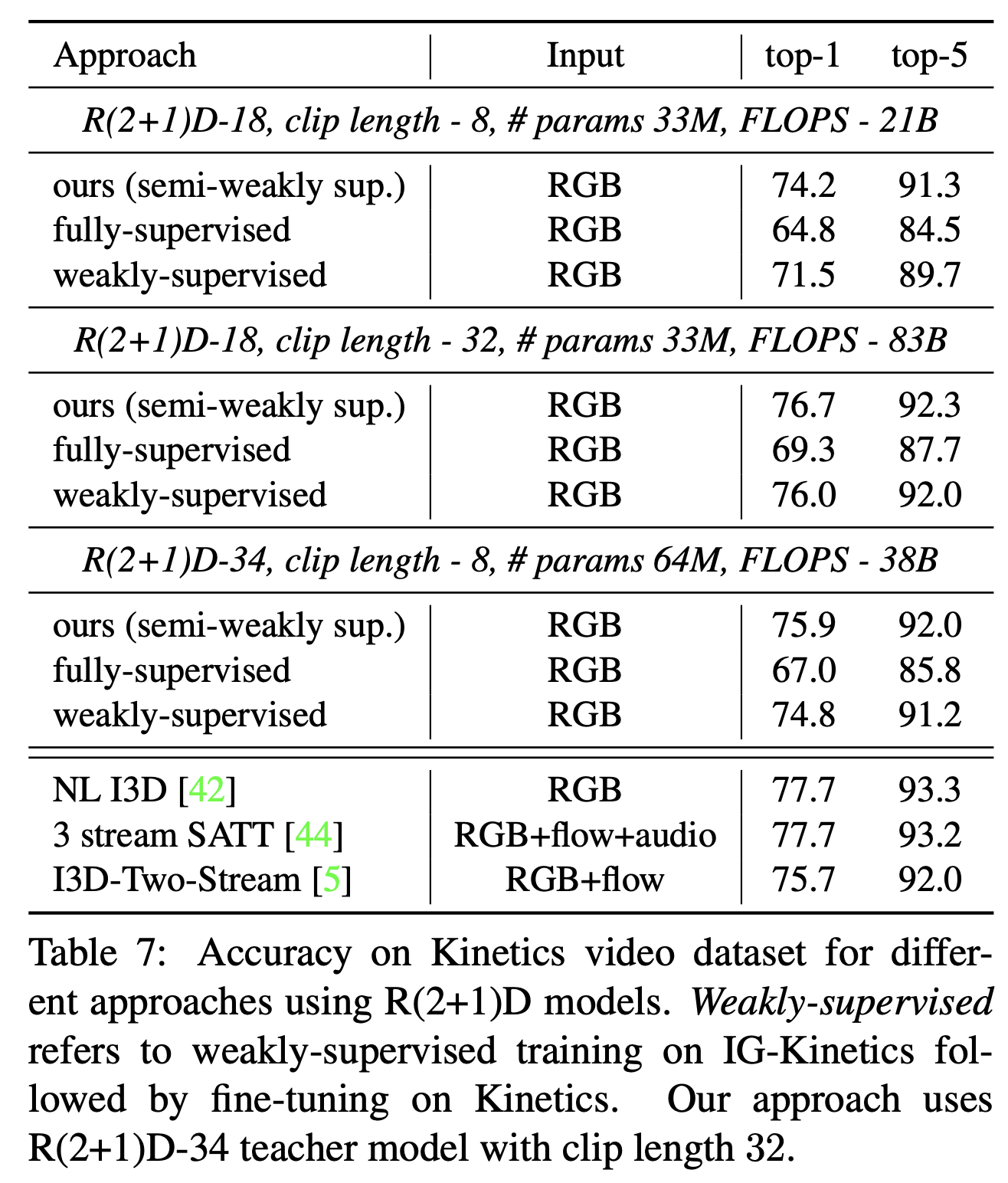
- Video classification
- Transfer Learning