Introduction
- OCR (Optical Character Recognition)
- 전통적인 OCR은 Text 문서를 Scan하여 얻어진 이미지로부터 Text를 추출하는 시스템을 의미
- 일반적인 이미지에 포함된 Text를 추출하는 문제는 visual artifact 때문에 훨씬 더 어려운 문제다.
- 문제들 : distortion, occlusions, directional blur, clutters background, different viewpoint
- 이 논문의 목적
- 지저분하고 개판인 이미지에서 중요한 부분에만 집중하여 Text를 추출.
- 당연히 CNN 쓴다. 그리고 추가로 RNN도 쓴다. 그리고 Attention도 쓴다.
Dataset
- 일반적인 이미지에 대한 OCR 데이터는 여러개가 있는데 이 논문은 구글이 자체 구축한 FSNS를 사용한다.
- FSNS는 별도로 자세히 설명하도록 한다.
- 다른 데이터와 FSNS 의 차이를 개략적으로 살펴보자.
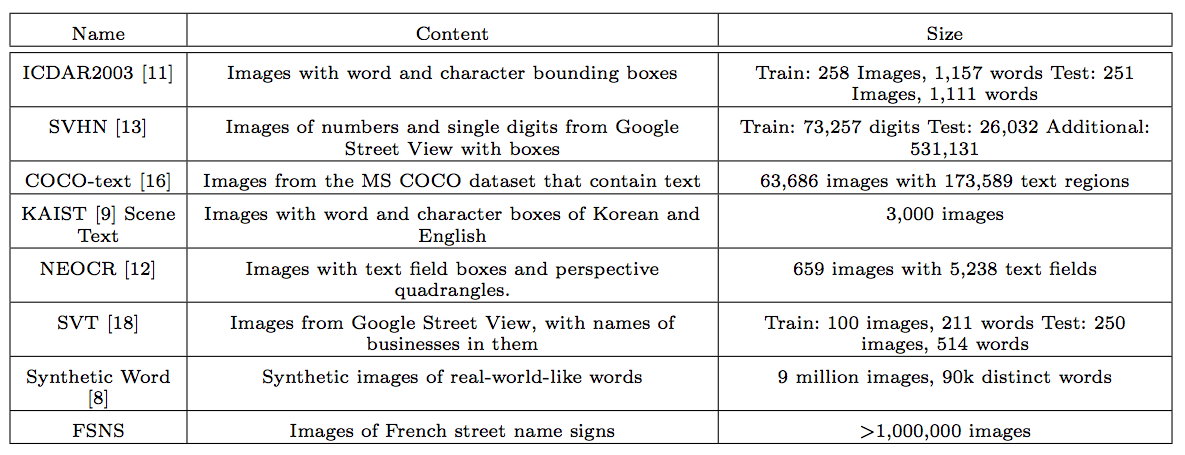
FSNS Dataset (French Street Name Signs Dataset)
- 프랑스 거리 이름 표지판 데이터
- 구글 스트리트 뷰(google street view) 데이터에서 추출되었다.
- 약 1M의 레이블된 이미지 데이터. (비교 대상인 COCO Text는 63K 데이터.)
- 이 데이터를 이용하여 이 논문에서는 84.2% 의 정확도(accuracy)를 얻었다. (이전의 state-of-arts 는 72.46%.)
- 추가로 정확도를 좀 더 올리기 위해 데이터에 대해 몇 가지 가정을 함. (뒤에 나옴)
- 그리고 추가로 Street View Business Names (아마도 상업용 간판) 을 추가 데이터로 사용
FSNS 상세
- OCR을 위한 프랑스 거리 주소 데이터
- 약 1M의 데이터 (큰 크기)
- 이미지 한 장은 150x150 pixel 로 구성. (실제로는 동일 그림 4장이 하나로 묶여 600x150 크기임)
- 이미지 내에 글자들이 적당히 위치함.
- 모든 글자는 여러 줄의 텍스트로 구성됨.
- 총 4장의 이미지가 하나의 그룹으로 편성되고 모두 같은 주소를 나타냄
- 하나의 동일한 물체를 다른 각도에서 촬영하거나,
- 크기가 다르기도 하고 투명도도 다름.
- 해당 sign이 배경 그림과 섞여 보이기도 함. (occlusion)
- 데이터 예제는 다음과 같다.

어떻게 만들었나?
- 다음과 같은 과정으로 FSNS 이미지를 생성함.
- 일단 이미지에서 주소 간판을 찾을 수 있는 Detector를 사용. 이를 프랑스 거리 뷰에서 찾음. Detector는 이미지 내에서 OD를 수행. (박스 위치 반환)
- 지정학적으로(geographic location) 동일한 위치에 있는 이미지를 그룹으로 묶은 과정을 진행 (spatially cluster)
- reCAPTCHA 를 이용하여 TEXT를 추출
- 알바생들이 후처리 작업을 통해 보정 작업을 진행.
- 이미지를 지리적으로 버킷 단위로 나누어 구성하고 train, validation, test가 서로 지역적으로 분리된 데이터로 생성되도록 구성. (서로 중복되지 않도록)
- 도로(Road)의 경우 지역적으로는 떨어져있지만 길게 이어지기 때문에 동일한 도로명이 여러 지역에서 노출될 수 있다. 이것은 후처리로 중복 제거.
- 최종 생성된 결과 중 이름이 37자 이상인 경우는 제거함. (즉, MAX character 수를 37로 제한함)
- 정규화 후처리
- 최종적으로 얻어진 결과에 대해 정규화(normalize) 과정을 수행함.
- 보통 표지 내용의 제목들은 모두 대문자임. 이를 다음과 같이 정규화함.
- au, aux, de, des, du, et, la, le, les, sous, sur 는 항상 소문자.
- prefix 로 등장하는 d’, l’ 도 항상 소문자.
- 그 외 첫 글자는 대문자, 이후에는 소문자. (d’, l’ 이 suffix로 등장하는 경우에는 이 룰을 적용)
- 또 다른 정규화로 기호(sign) 내부에 거리 이름이 아닌 것은 삭제.
- 이게 어려울 것 같지만 패턴이 좀 있음. 표지판에 더 작은 글씨를 가진 단어가 존재 한다거나…
- 문제 정의상 전통적인 OCR 문제라기 보단 Image Caption에 더 가깝다.
모델
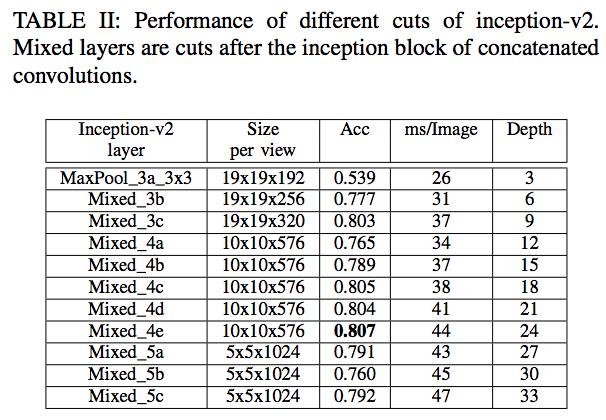
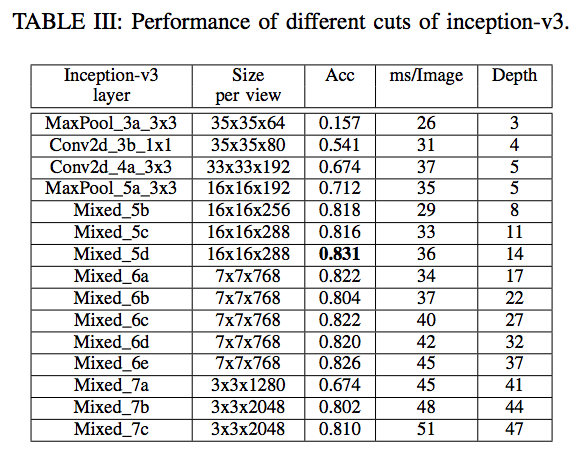
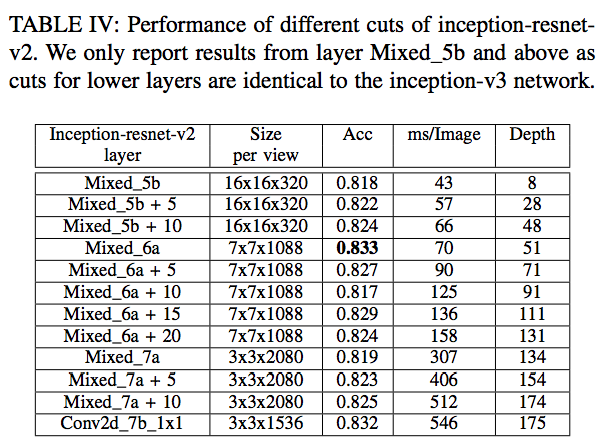
- 3개의 CNN 모델을 사용함. (각각을 테스트함)
- 성능 향상을 위해 일부 레이어(layer)를 제거한 버전(ablated version)을 사용
- 신기하게도 망이 깊을수록 초기에는 정확도가 증가하지만 이내 정확도가 감소하는 것을 확인하였다. (3개의 망 모두)
- 이는 Imagenet ILSVRC 로 학습한 일반적인 CNN 모델과는 정 반대의 현상
- 왜 이런 현상이 생길까 고민해봤는데 아마도 이미지 분류 문제는 복잡한 feature 를 사용하는 것이 주요한 요소임에 반해
- text 추출과 같은 비교적 단순한 task에서는 오히려 독이 되는 것으로 사료된다.
- 정리하자면 이 논문에서는,
- End-To-End 기법을 활용하여 기본적인 attention 모델을 사용하는 아키텍쳐를 설계하고
- 물론 이전에 활용되던 SOTA 방식보다 좀 더 단순화된 모델을 적용하여
- 이 모델일 얼마나 좋은 결과를 제공하는지를 설명한다.
- 마지막으로 다양한 CNN 변형체(variants)를 테스트해보면서 각각의 정확도를 고찰해본다.
- End-To-End 기법을 활용하여 기본적인 attention 모델을 사용하는 아키텍쳐를 설계하고
- 전체 아키텍쳐는 다음과 같다.
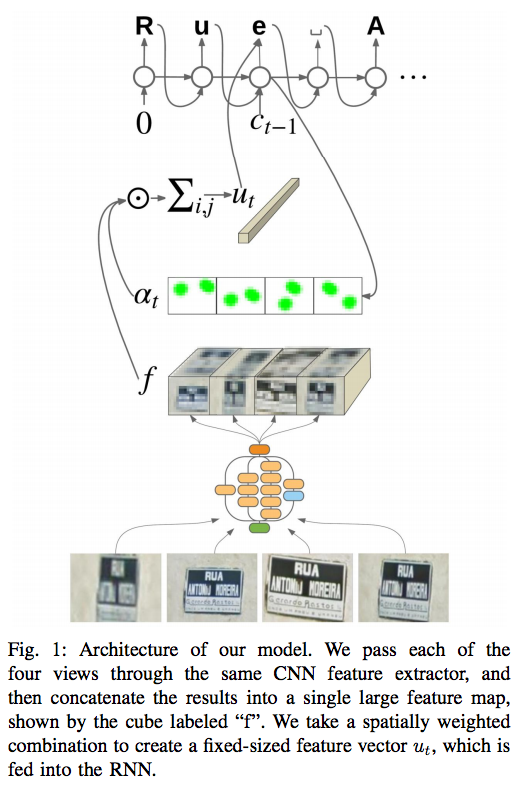
CNN-based feature extraction
- 사용되는 CNN은 3가지 종류.
- inception-v2
- inception-v3
- inception-resnet-v2
- 사실 이 모델은 이미지 분류(classification) 문제를 해결하기 위한 모델
- 물론 중간 레이어 정보를 이미지 feature로 사용하는 것이 요즘 추세.
- 하지만 어떤 layer가 좋은 이미지 feature인가는 말하기가 쉽지 않음. (이건 뒤에 다시 설명)
- 추가로 pretrained vs. training w/ random-init 를 비교.
- 출력 함수 \(f\) 를 \(f=\{\;f_{i, j, c}\;\}\) 로 정의. (\(i\) 와 \(j\) 는 위치정보, \(c\) 는 채널 정보)
RNN
- feature map 정보를 하나의 단어에 매핑하기 위한 방법으로 RNN을 사용함.
- 그냥 일반적인 char-RNN 을 생각하면 된다.
- attention 모델을 적용하였다.
-
이 때 사용되는 attention mask는 다음과 같이 정의된다. \(\alpha_{t} = \{ \; \alpha_{t, i, j} \; \}\)
- 실제 이 값을 생성하는 식은 뒤에 언급된다.
- 최종적인 출력 결과는 다음과 같다.
- 타임 \(t\) 시점에서의 RNN 입력값은 다음과 같다.
- 이 때 \(c_{t-1}\) 은 (one-hot 인코딩으로 처리된) 문자의 값을 의미한다.
- 당연히 학습(training) 단계에서는 정답 문자를 사용하고, 추론(inference) 단계에서는 예측된 이전 문자를 사용한다.
- RNN을 통과한뒤 얻어지는 결과는 다음과 같다.
- 출력값 \(o_t\)는 특정 문자를 의미하는, softmax 결과값이다. 생성시 RNN Cell 결과 뿐만 아니라 \(u_t\) 값도 함께 사용한다.
- 출력 글자는 다음과 같다.
Attention (Spatial attention)
- 이 문서의 핵심 contribution은 당근 attention 모델의 도입이다.
- 근데 이전의 show attend & tell 같은 방식과 크게 다를바 없다.
- 예전 attention 방식과 약간 다른것이 있는데 데이터 자체에 위치 정보를 추가한다.
- 먼저 예전 모델들이 사용하던 일반적인 attention 식을 보자.
- 여기서 \( \circ \) 은 element 단위로 곱(multiplication)을 하는 것을 의미한다.
- 이 식을 해석(?)해 보자면,
- \(W_f f\) 는 이미지로 부터 얻어지는 컨텐츠 정보를 의미하고,
- \(W_s s_t\) 는 시퀀스 데이터를 이용해서 컨텐츠 중 어느 곳에 집중을 해야 하는지를 나타내는 정보가 된다.
- 위의 식은 permutation invariant 한 속성을 가지고 있음.
- \(f_{i,j,:}\) 에 대해 \(W_{f}\) 가 FC 를 이루므로 지역적 정보는 존재하지 않는다.
- 그래서 위치 정보 (spatial coordinates) 를 데이터에 추가함.
- 따라서 다음의 식을 사용한다.
- 여기서 \(e_{i}\)와 \(e_{j}\) 는 각각 \(i\) 와 \(j\) 에 대한 one-hot 인코딩 값이다.
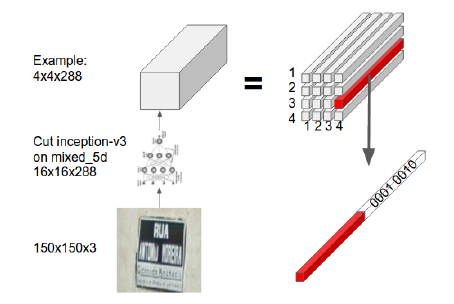
학습 (training)
- 입력 데이터는 4개의 이미지가 같이 들어간다.
- 따라서 하나의 feature map 의 크기는 16x16x320 이고 4장이므로 64x16x320이 된다.
- MLE를 최대화하는 식을 목적 함수로 사용한다.
- 따라서 \(\sum_{t=1}^{T}\log p(y_t|y_{1:t-1}, x)\)를 최대화하는 형태로 구현한다.
- 이 때 \(x\) 는 입력 이미지가 되고 \(y_{t}\) 는 \(t\) 위치를 가지는 문자를 의미한다.
- \(T=37\) 을 사용한다. (FSNS Dataset)
- 보통 이러한 스타일의 학습에는 CTC(Connectionist Temporal Classification) loss를 사용한다.
- 이와 관련된 내용은 이 문서 를 참고하자.
- 하지만 여기서는 autoregressive connection을 사용하기 때문에 CTC는 사용할 수 없다.
- autoregressive 는 중간 출력의 결과가 입력으로 활용된다고 생각하면 된다.
- 하지만 실제 해보니 autoregressive 방식이 성능도 좋고 (6% 성능 증가) 학습 속도도 빠르다. (2x)
- 학습과 관련된 Hyper Parameter
- lr : 0.002
- decay factor : 0.1 after 1,200,200 step
- total step : 2,000,000
- data augmentation 사용
- 랜덤 크롭.
- 원본 이미지의 0.8% 면적을 가지는 이미지로 크롭
- aspect ratio 는 0.8~1.2로 유지 (xy비)
- 크롭된 이미지를 resize
- 랜덤 distotion 추가
- contrast, hue, brightness, saturation 변환
- 랜덤 크롭.
- Weight decay : 0.0000004
- Label-smoothing : 0.9
- LSTM Clipping : 10
- LSTM Unit : 256
- BatchSize : 32 (12 for resnet-v2 due to GPU MEM.)
- Sync mode : Asynchronous Update on 40 Maching.
- 사용된 데이터 집합
- FSNS Dataset
- SVBN (Street Business Names) Dataset
- 이미지의 크기는 352x352x3
- 모든 단어 집합은 33개의 symbol + 128 영어 글자
실험 결과
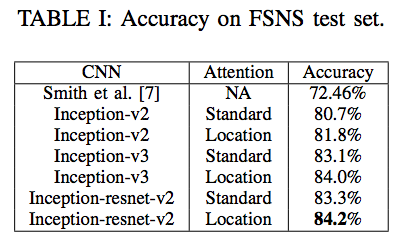
- 간단하게 attention 결과를 보자.
