- 이미지넷을 이용한 모델의 성능 비교가 일반화의 측면에서 충분히 타당한 것인가에 대한 의문.
- 혹시 현재의 모델들이 이미지넷 레이블에 overfitting 되고 있는 것은 아닌가?
- 좀 더 강력한 검증 절차를 마련하고 싶다.
- 새로운 레이블을 제안하고 최근 제안된 모델에 대한 성능 측정을 다시 한번 해본다.
- 그 결과 제안된 모델에서 얻어지는 효과(이득)가 알려진 것보다 실질적으로는 더 적다는 것을 확인하였다.
Introduction
- 이미지넷은 사실상의 업계 표준 비교 데이터셋.
- 알렉스넷 시절부터 모두 이걸 기준으로 평가.
- 최근 결과들은 단순하게 이에 대한 성능 향상만을 보고하고 있기에 우리가 직접(
한땀한땀) 이 데이터가 충분히 일반적인가를 확인. - 사람이 직접 정답을 적어(annotation) 평가셋을 구축하고 이를 ReaL(Reassessed Labels) 로 명명.
- 그리고 최근 모델들을 이 데이터에 대해 다시 평가해 본다.
- 오리지널 ImageNet에 대한 평가 결과와 ReaL 로 평가한 결과가 대충 비슷한 경향성을 보이긴 하지만 최근의 모델일수록 그 효과가 약하다는 것을 확인하였다.
- 또, 놀랍게도 오리지널 ImageNet 정답 결과가 우리가 새로 만든 데이터에 대해 가장 좋은 결과를 내는 것이 아님을 확인했다. (그림.1 참고)
- 다음으로 두 데이터 간의 정확도 불일치를 분석하여 여러 모델들이 오리지널 ImageNet에 Overfitting 되어 있다는 것도 확인하였다.
- 마지막으로 이런 관찰을 토대로 두 가지 간단한 기법을 제안하여 두 데이터의 정확도 모두를 올릴 수 있다는 것을 확인한다.
Related work
- 다양한 벤치마크 결과를 재검토하였다.
- 하지만 그 어떠한 연구도 ImageNet 자체의 문제로 인한 영향을 조사하지는 않았다.
ImageNet 레이블이 뭐가 잘못 되었나?
- ImageNet 은 1000개의 분류 결과를 사람이 판단한 결과이다.
- 그럼에도 불구하고 몇 가지 문제점이 눈에 띈다.
- ImageNet 에 포함된 많은 이미지들은 단 하나의 물체를 표현하는 명확한 이미지인 경우가 많다.
- 하지만 어떤 이미지들은 다양하고 여러 물체가 포함된 이미지인 경우도 있다.
- 이런 경우에도 단 하나의 레이블만 기술되어 있다.
- 또 어떤 클래스는 본질적으로도 애매모호하여 두 그룹으로 나누기가 애매한 레이블이 포함되어 있다.
-
좀 더 명확하게 구분을 좀 해보자.
- Single label per image
- 현실 세계의 이미지는 주의를 집중시킬 여러 물체들이 하나의 이미지에 등장하는 경우도 많다.
- 하지만 ImageNet 에 정답을 달 때에는 오로지 하나의 레이블만을 기술할 수 있다.
- 결국 이미지를 표현하는 것에 대한 제약을 발생시킨다. (그림.2를 첫번째 줄을 참고하자.)
- 이 경우에는 이미지에 포함된 여러 물체에 대한 레이블을 달아야 한다.
- Overly restrictive label proposals
- 지나치게 제한된 형태로만 레이블을 달아야 한다.
- 그림.2 가운데 행을 보면 실제 정확한 레이블이 아님에도 적당히 잘 어울리는 레이블에 할당되어 있다.
- 이는 실제 존재하는 더 좋은 레이블로 수정되어야 한다.
- Arbitrary class distinctions
- ImageNet 레이블에는 시각적으로는 구분이 힘든 이미지 그룹에 대한 레이블이 중복되어 들어있다.
- 그림.2 맨 아래 행을 참고하자.
- 예를 들면 “sunglass” 와 “sunglasses” 가 모두 포함되어 있다.
- 이런 애매모호함이 성능에 영향을 미친다.

ImageNet validation set을 다시 만들기
- 이미지에 하나의 레이블만 표기하기 때문에 생겨나는 바이어스를 해결하기 위해 새로운 레이블링 방법을 제안한다.
- 추가적으로 알바(human annotators) 분들이 손쉽게 레이블을 기록할 수 있는 기법들을 고려한다.
제안(proposal)된 결과들을 수집
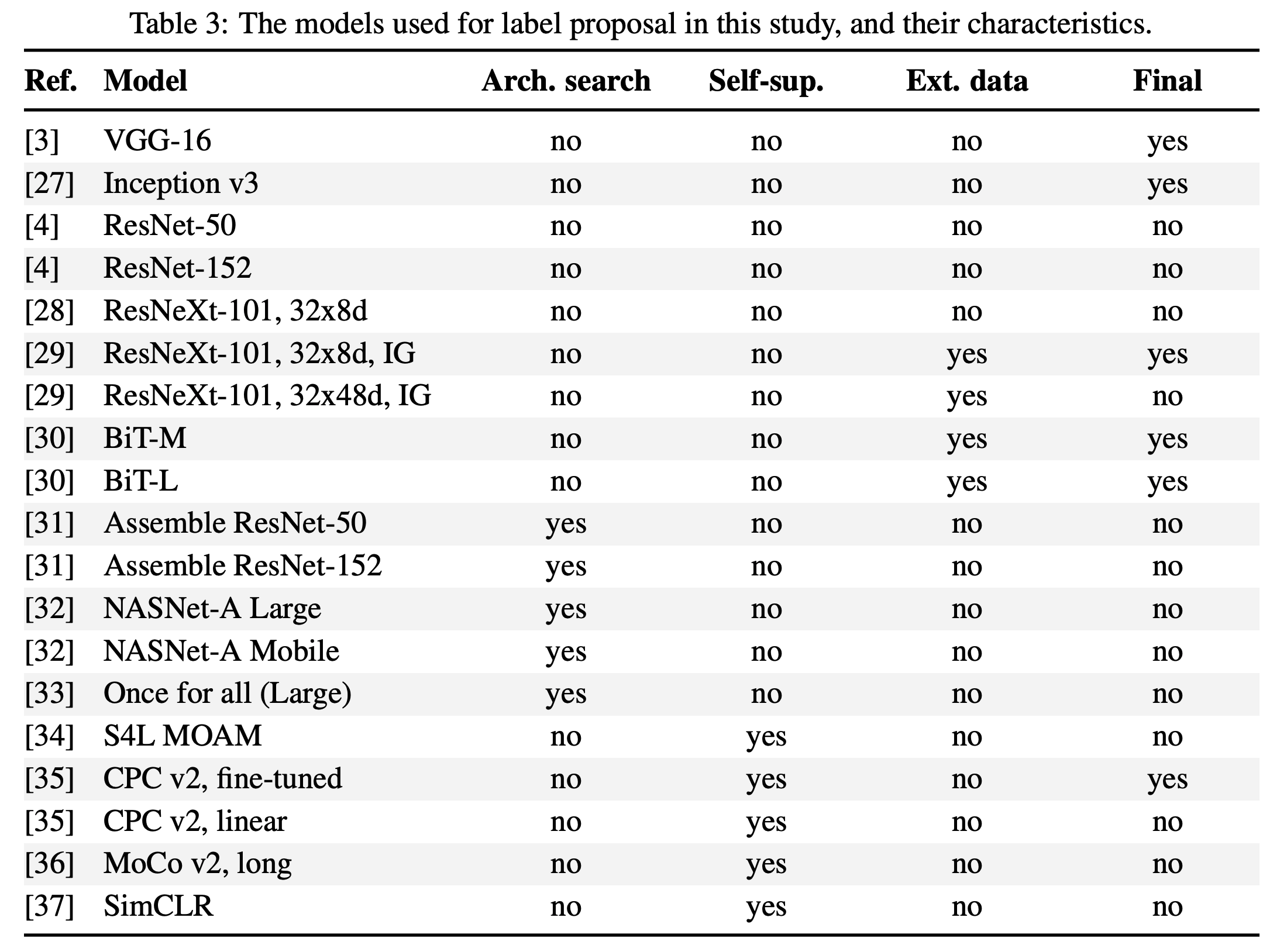
- 우선 다양한 모델(여기서는 19개의 모델)이 제공하는 예측 결과를 모으는 작업을 수행한다.
- 이 모델은 아키텍쳐, 차원(dim) 등이 전부 다르고,
- 학습시 ImageNet 외에 다른 데이터를 추가로 학습하기도 했다.
- 이 모델들의 분류는 Appendix. A에 정리해 두었다. (아래 Table.3 그림.)
- 각 모델들에 대해 우리는 논문 작성자들이 제공해주는 코드를 사용하였다.
- 최대한 일반화된 결과를 확인하기 위해 다음과 같은 기준을 사용한다.
- 동일한 이미지에 대한 ImageNet(ILSVRC-2012) 레이블에 대한 top-1 평가를 가져온다.
- 실제 이미지에는 하나 이상의 객체가 존재할 수 있기 때문에 해당 모델에서 제공하는 logit 결과도 가져온다.
- 구체적인 제안 방법
- 각 모델에 대해 logit 과 prob 를 추출한다. 50,000x1000x1000=50M 개의 결과
- 로짓을 150K 또는 prob 를 150K 추출
- 각 모델 결과를 하나로 pooling. 이 때 하나의 모델에서만 등장한 결과는 삭제
- 원래 ImageNet 의 결과도 추가
- 제안되는 레이블을 수를 줄이기 위해 우리는 일부 모델만 먼저 선정을해서 사용하기로 한다. 다음과 같은 작업을 수행한다.
- 비전 전문가 5명 (아마도 저자들??)이 256개의 이미지에 대해 정답 레이블을 구축해 놓는다.
- 이 모델에 대해 전체 정확도와 리콜을 적절히 보장할 수 있는 모델들을 선정한다. (Table.3 의 Final 영역)
- 뭐, 다양한 조합이 나올 것이다.
- 본문에는 선정된 6개의 모델이라고 되어 있는데 Table.3 에는 5개만 표기되어 있다. 왜일까???
- 이 모델로만 제안되는 레이블을 가지고 제안한다.
제안된 레이블에 대해 사람이 평가하기
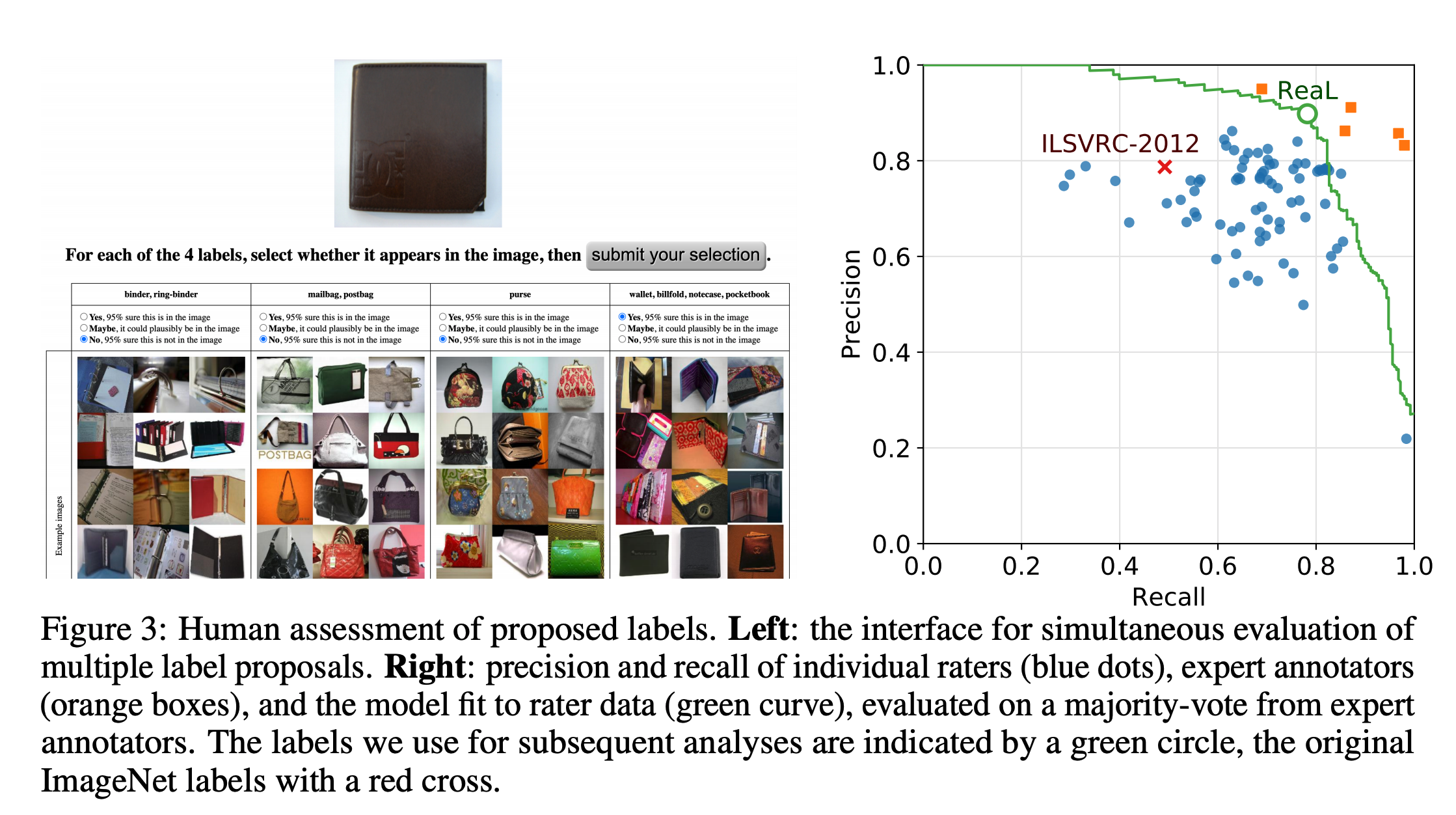
- validation 집합에 대해 새로운 레이블 후보를 얻은 뒤 이를 사람이 평가.
- 만약 이렇게 사람이 다시 평가한 결과가 원래의 결과와 같다면 그냥 ImageNet 을 사용하면 된다.
- 이렇게 해서 50000개의 이미지를 24889개로 감소시켰다.
- 특정 어노테이터에 데이터가 쏠리지 않게 하기 위해서 WordNet 계층 구조를 기반으로 8개 이상의 레이블 작업으로 분리
- 5명의 알바가 작업을 수행한다.
- 평가자에게는 최대 8개의 후보 레이블이 주어지며 조건을 선택하게 되어 있다. (그림 3 왼쪽을 보자.)
- 다음 스텝은 이렇게 얻어진 결과를 최종적으로 합치는 과정이다.
- 어떤 데이터를 넣고 어떤 데이터를 폐기해야 하는가?
- 고전적인 방법론을 도입하여 MLE를 통해 오류율을 추론한다.
- 확인 결과 동물 클래스는 더 많은 불확실성을 내포하고 있으므로 전문가의 의견이 필요하다.
- 사실 ImageNet 에서 동물 영역의 레이블은 전문가가 달아둔 것이다.
- 따라서 ImageNet 결과 중 동물 레이블은 6번째 평가자가 기록한 것 처럼 사용하였다.
- 그림 3에서 부적절하게 판단되는 평가 결과는 모두 제거하였다. (3163개의 평가는 제거되었다.)
- 이제 새로운 Metric 을 제안할 차례이다.
- ReaL 이라는 평가 Metric 을 제안한다. (Reassessed Labels)
- 예측한 결과가 레이블 집합에 포함되어 있으면 정답, 아니면 실패로 간주한다.
최신 모델에 대해 다시 평가해보기
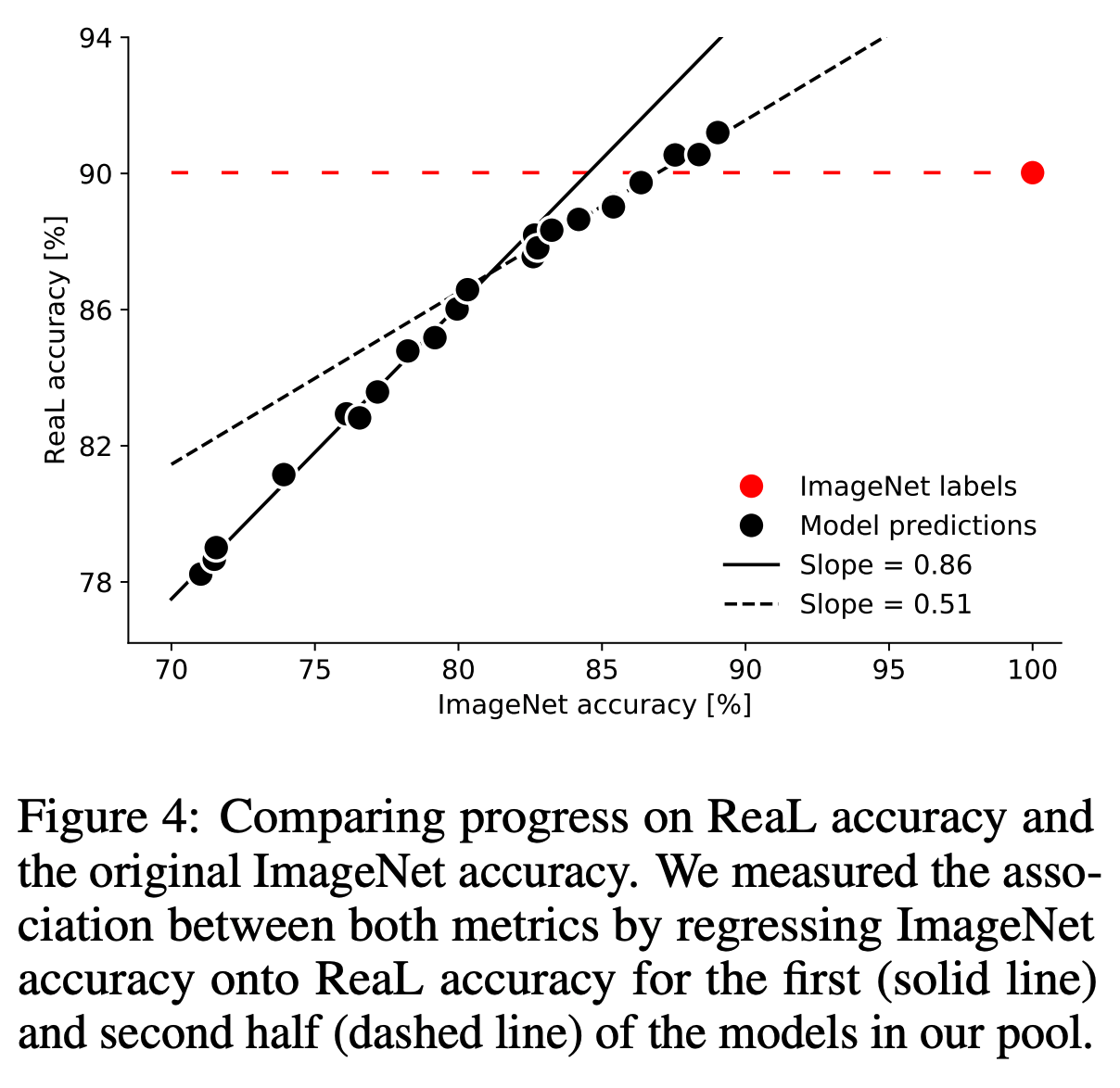
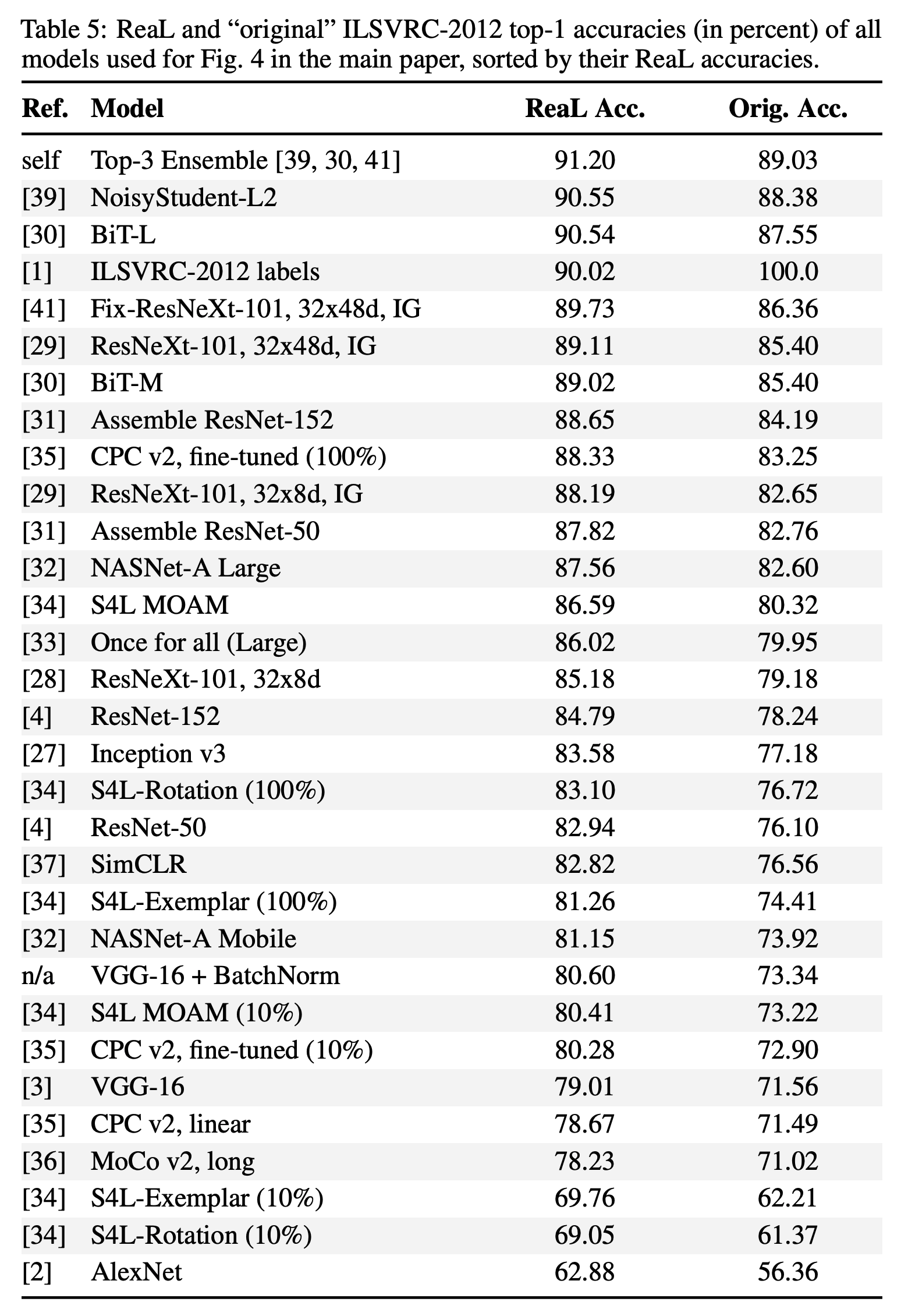
- 제안된 ReaL 데이터를 이용하여 최근 모델로 다시 평가해 본다.
- 각 모델에 대해 ReaL 과 ImageNet 의 평가 결과를 보면 상관 관계가 존재한다.
- 선형 회귀 사용.
- 초기 모델들은 강한 선형 관계를 가진다. (기울기 0.86)
- 최신 모델들은 선형 관계가 있지만 기울기가 상당히 감소했다. (0.51, p<0.001)
- 놀랍게도 2개의 모델은 원래 ImageNet보다 ReaL 에 대해 더 좋은 평가 결과를 가진다.
- ImageNet의 ReaL 정확도는 90%이다.
- 이것으로 보면 ImageNet은 평가 지표로서 가치가 거의 다 끝나간다고 생각할 수 있다.
- 이 추세를 명확하게 확인하기 위해 ImageNet 결과 또는 모델의 예측값이 ReaL 레이블을 잘 예측하는지 확인한다.
- Model:O, ImageNet: X
- Model:X, ImageNet: 0
- 비율 계산
- 초기 모델은 ImageNet 보다 결과가 안좋지만 최근 모델은 ImageNet 보다 좋다. (그림.1 참고)
- 이러한 추세가 계속 이어지는지 확인하기 위해 가장 좋은 모델 3개를 앙상블해보았다. 역시나 더 좋다.
단일 레이블 예측 관련
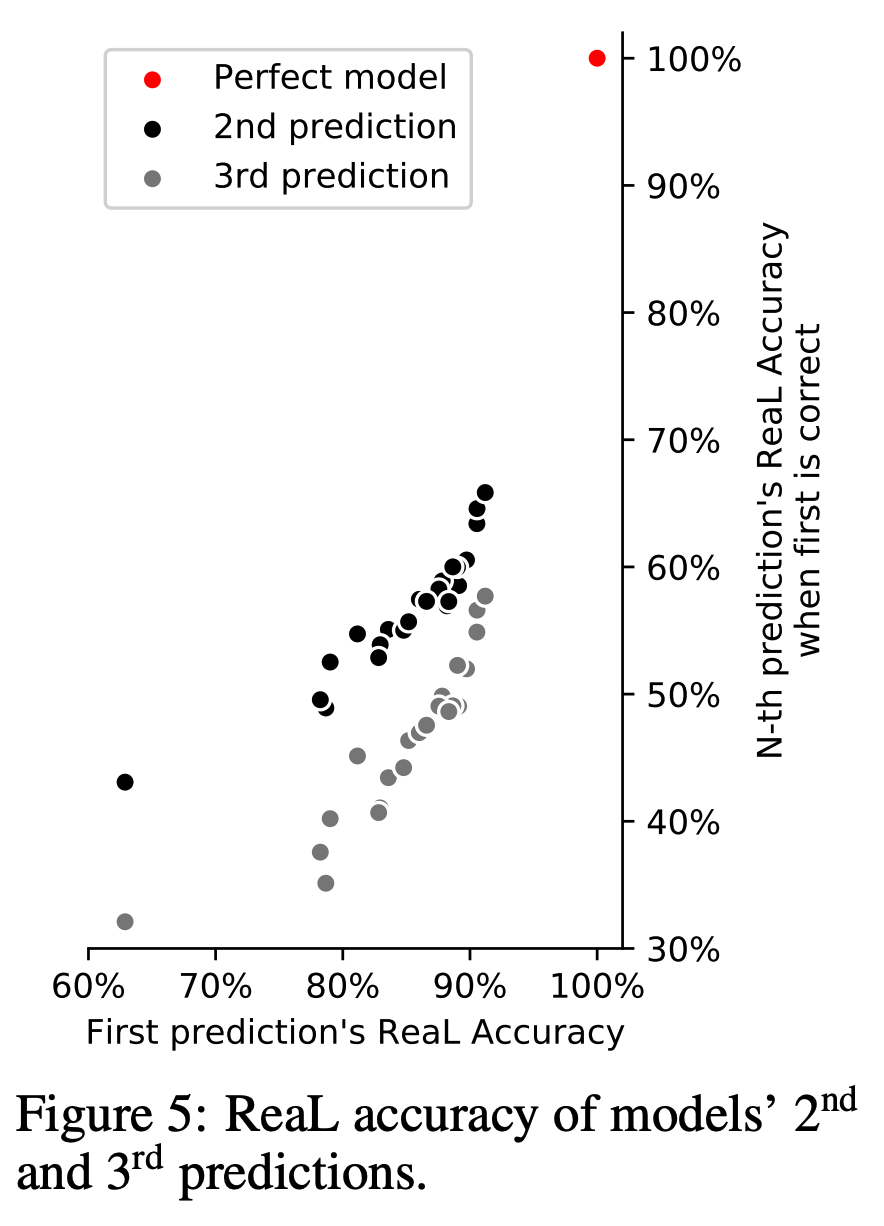
- ReaL 평가 방식은 단길 예측에 대해 실제 가능한 여러 레이블 집합 중 하나에 속하는지를 확인하게 되어 있다.
- 하지만 좀 더 엄격한 기준을 고려한다면 상위로 예측된 결과가 허용 가능한 범위에 속하는지를 보는것이 맞다.
- 사용하는 모델들이 단 하나의 레이블만 맞추도록 학습되었다는 것을 고려하면 2등의 결과를 확인하는 것은 의미가 없을 수 있다.
- 하지만 각 클래스 사이의 비주얼적인 유사성은 뒤 등수의 예측값을 증가시킬수도 있음을 의미한다.
- 그림 5는 2등, 3등의 에측 정확도를 보이고 있다.
- 당연히 1등의 에측보다는 결과가 낮음을 알 수 있다.
- 그럼에도 불구하고 이러한 예측은 예상보다 더 좋은 결과를 보인다.
- 즉, 클래스간의 상관 관계가 의미있는 2등 결과를 가능하게 함을 이해할 수 있다.
- 이를 이용해서 ReaL에 대한 metric 을 개선할 수도 있다.
- 즉, 2차 결과도 함께 고려해서 Metric 을 더 엄격하게 제어할수도 있다.
동시 발현되는 클래스 분석
- ReaL 에서 레이블을 단 ImageNet 이미지 중 약 29% 가 여러 레이블을 가지고 있다.
- 즉, 약 29%의 이미지들은 이미지 내에 여러 object 들이 존재한다는 것이다.
- 자연스럽게 떠오르는 의문은 과연 기존의 모델들은 이러한 이미지에 대해 어떻게 결과를 내어주고 있느냐는 것이다.
- 실제로 올바른 레이블 중 하나를 무작위로 예측하는가?
- 아니면 원래의 ImageNet 에 표기된 레이블에 대해 Bias 를 가지게 되는 것일까?
- 이에 대해 분석을 좀 해보자.
- 우선적으로 ImageNet 레이블이 포함된 ReaL 이미지 데이터만을 고려한다.
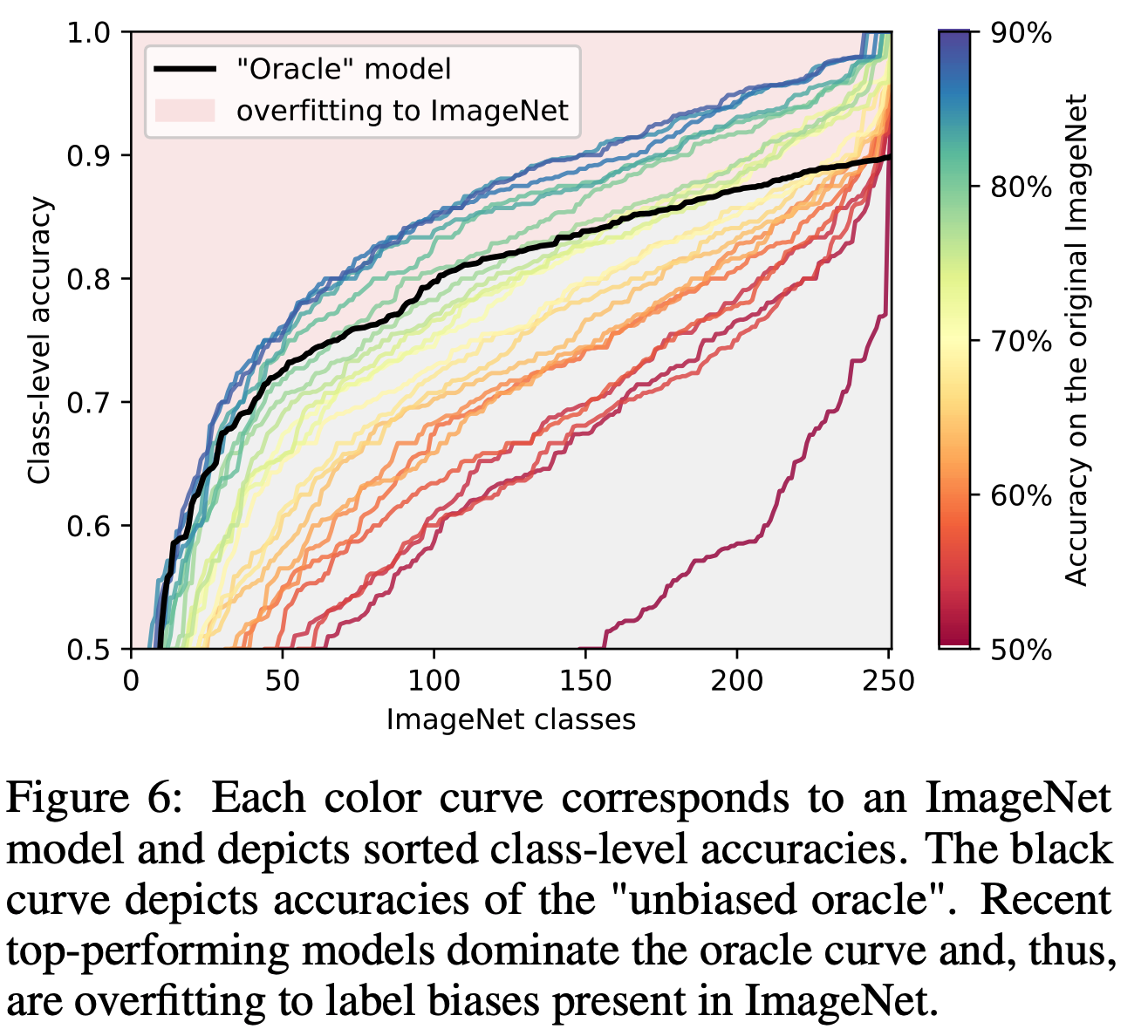
- 여기서 ReaL 레이블에 대해 각각의 클래스를 “unbias” 하게 예측하는 “unbiased oracle” 모델을 제시한다.
- 랜덤하게 ReaL 정답 레이블 중 하나만을 예측하는 모델이다.
- 만약 A라는 모델이 ImageNet 레이블에 bias 되어 있지 않다면 oracle 모델이 현재 ImageNet 에 대해 최고의 성능이라 할수 있다.
- 즉, upper bound 가 된다.
- 좀 애매한 레이블들만 집중적으로 보기 위해 oracle 모델의 정확도가 90% 이하인 class 들만 살펴보도록 하자.
- 그런데 사실 이런 클래스 중 일부는 실제 labeling noise 에 의해 발생될 가능성도 존재한다.
- 그래서 가장 애매 모호했던 동물(animal)에 속하는 클래스도 모두 제거.
- 이 기준에 맞추어 약 253개의 클래스만 남았다.
- 여기에는 (sunglass, sunglasses), (bathtub, tub), (promotory, cliff), (laptop, notebook) 등도 포함되었다.
- 그림 2의 첫줄, 세번째 줄 참고
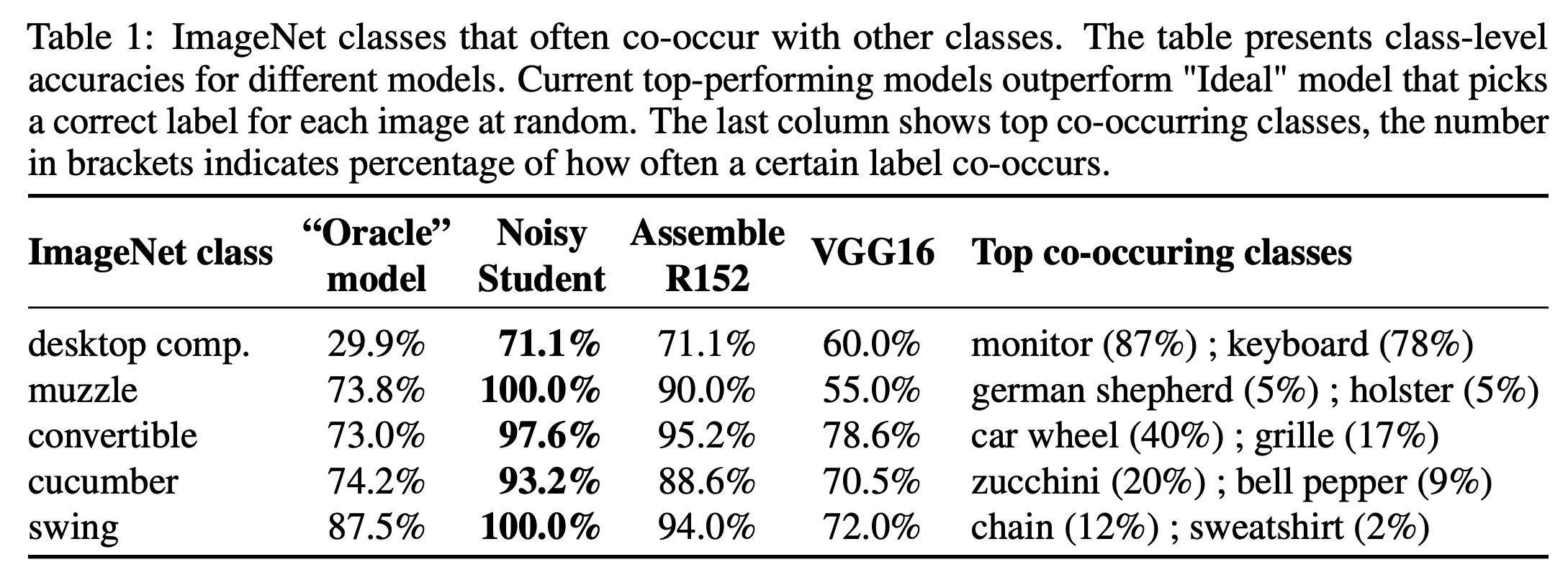
- 아래 Table.1 은 위 내용을 좀 더 자세히 기술한 것이다.
- 예를 들어 “desktop computer” 가 포함된 이미지에 대해 oracle 모델이라면 실제 약 30%의 정확도만 가지게 된다.
- 하지만 실제 모델들은 더 높은 score 를 가진다.
- 그림.6은 모들 모델에 대한 클래스별 정확도를 나타낸다.
틀린 것에 대한 분석
- 아무리 좋은 모델일지라도 약 11% 는 틀린 결괄ㄹ 내고 있다.
- 도대체 왜 이런 결과를 얻은 것일까?
- 이 질문에 답을 하기 위해서는 예측이 틀린 이미지들을 골라 분석을 해야 한다.
- 그리고 이 이미지에 대해 원래 정답을 표기해 둔다.
- 그 다음 알바(raters) 들에게 이 이미지가 왜 잘못 예측되었는지에 대해 식별해보라고 지시한다.
- 진짜 모델이 못 맞춘 것일까? 아니면 다른 이유가 있을까? 혹시 평가자도 이를 구별할 수 있을까?
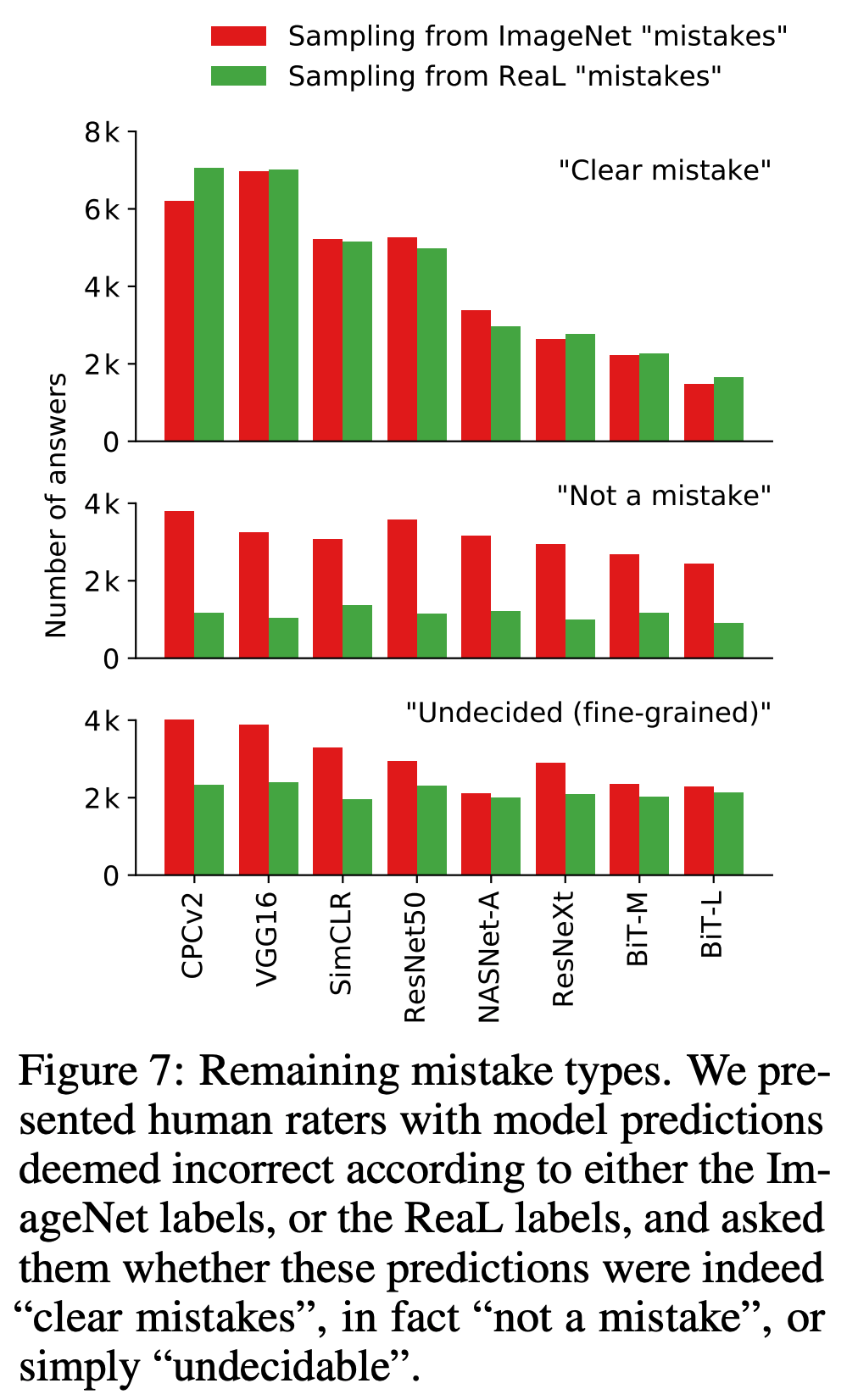
- 이 연구에 사용된 모델을 ImageNet 정확도 순으로 정렬하여 표기힌다. (그림.7)
- 이렇게 정렬을 하면 명확하게 실패한 예측에 대한 감소를 확인 가능하다. (첫번째 줄)
- 그런데 놀랍게도 평가자가 보기에 실수가 아닌 케이스도 발견된다. (두번째 줄)
- 중요하게도 이러한 경우는 ImageNet 에서 샘플링했을 때 더 많이 발생한다.
- 즉, ReaL 데이터가 이런 문제를 상당 수 수정했음을 알 수 있다.
- 마지막 줄은 절대 무시할 수 없는 수치를 가지는 “undecidable” 경우이다.
- 이 분류는 사람이 판단하기 어렵거나 불가능한 경우를 의미한다.
- 따라서 전문가가 레이블링을 해야 하는 영역이다.
- ReaL 은 ImageNet 보다는 낫다.
ImageNet 학습 성능 올리기
- ImageNet 레이블링에는 다음과 같은 문제가 있다.
- 여러 레이블이 필요한 이미지에 단일 레이블만을 기술했다.
- 그런데 학습 데이터에도 이런 식으로 레이블링을 수행했기 때문에 학습 데이터에도 동일한 문제가 존재한다.
- 이 문제를 해결할 수 있는 방안은?
- 먼저, 모델이 주어진 이미지에 대해 여러 개의 예측값을 내도록 훈력하도록 제안한다.
- 이를 위해 multy-way 분류 문제를 독립적인 이진 분류 집합 문제로 다루고 sigmoid cross-entropy 를 사용하는 모델을 제안한다.
- 이 모델은 클래스간 상호 배타적인 결과를 예측하지 않도록 한다.
- 다음으로 요즘 최신의 모델들이 원래의 ImageNet 성능을 능가한다는 관찰을 통해 ImageNet 결과의 노이즈를 필터링할 수 있는지 고민한다.
- BiT-L 모델을 사용하여 학습 데이터를 정제한다.
- 10-fold 로 학습 데이터를 나누어 사용한다.
- 학습 방법
- 9-fold 를 학습한 뒤 나머지 1-fold 를 예측.
- 그런다음 BiT-L 과 일치하지 않는 이미지를 제거.
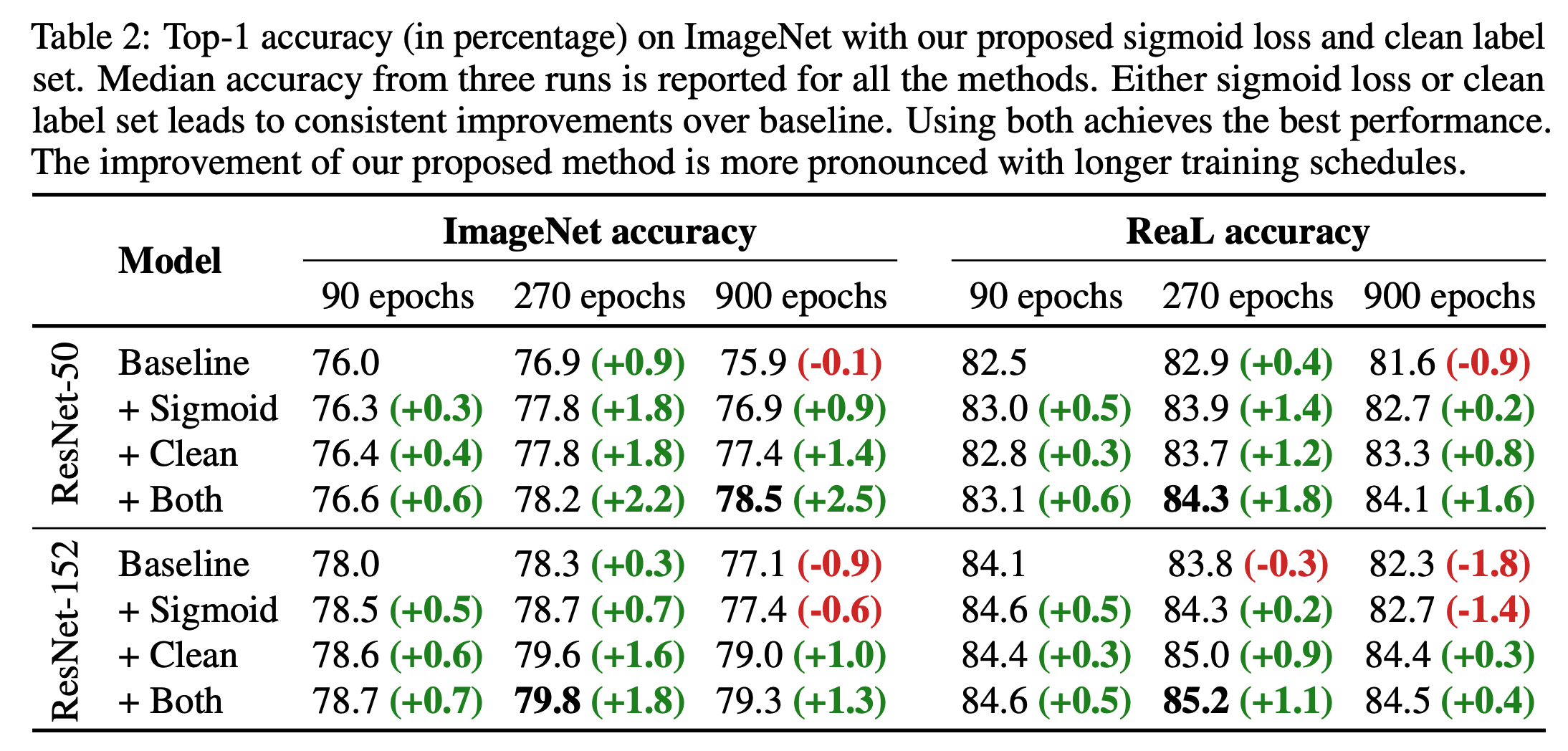
- Table.2 는 ResNet-50/152에 대해 ImageNet 을 학습하는 결과를 기술합니다. (softmax vs. sigmoid)
- 이를 통해 여러개의 인사이트를 얻는다.
- 보다 정제된 ImageNet 데이터셋에 대해 모델의 정확도가 향상된다. (softmax 사용시 더 두드러짐)
- softmax 대신 sigmoid 가 성능 향상이 두드러짐
- 둘 다 쓰면 더 좋아진다.
- ResNet-50 에 대해 900 epoch 결과는 무려 78.5%.
결론
- 이 논문에서는 ImageNet 벤치마크 데이터에 대한 분석을 시도했다.
- 모델들이 이 데이터에 대해 과적합(overfitting)하기 시작했는지를 확인했다.
- 이를 위해 새로운 데이터를 제안하였다. (ReaL)
- 최근 모델은 이미 ImageNet 레이블 성능을 능가하기 시작했다.
- 추가로 ImageNet 의 단점을 확인하고 학습시 성능을 개선하기 위한 2가지 방법을 제안하였다.
- 이를 통해 더 좋은 정확도를 어등ㄹ 수 있었다.
Appendix
- 좀 더 자세한 ImageNet 학습 결과
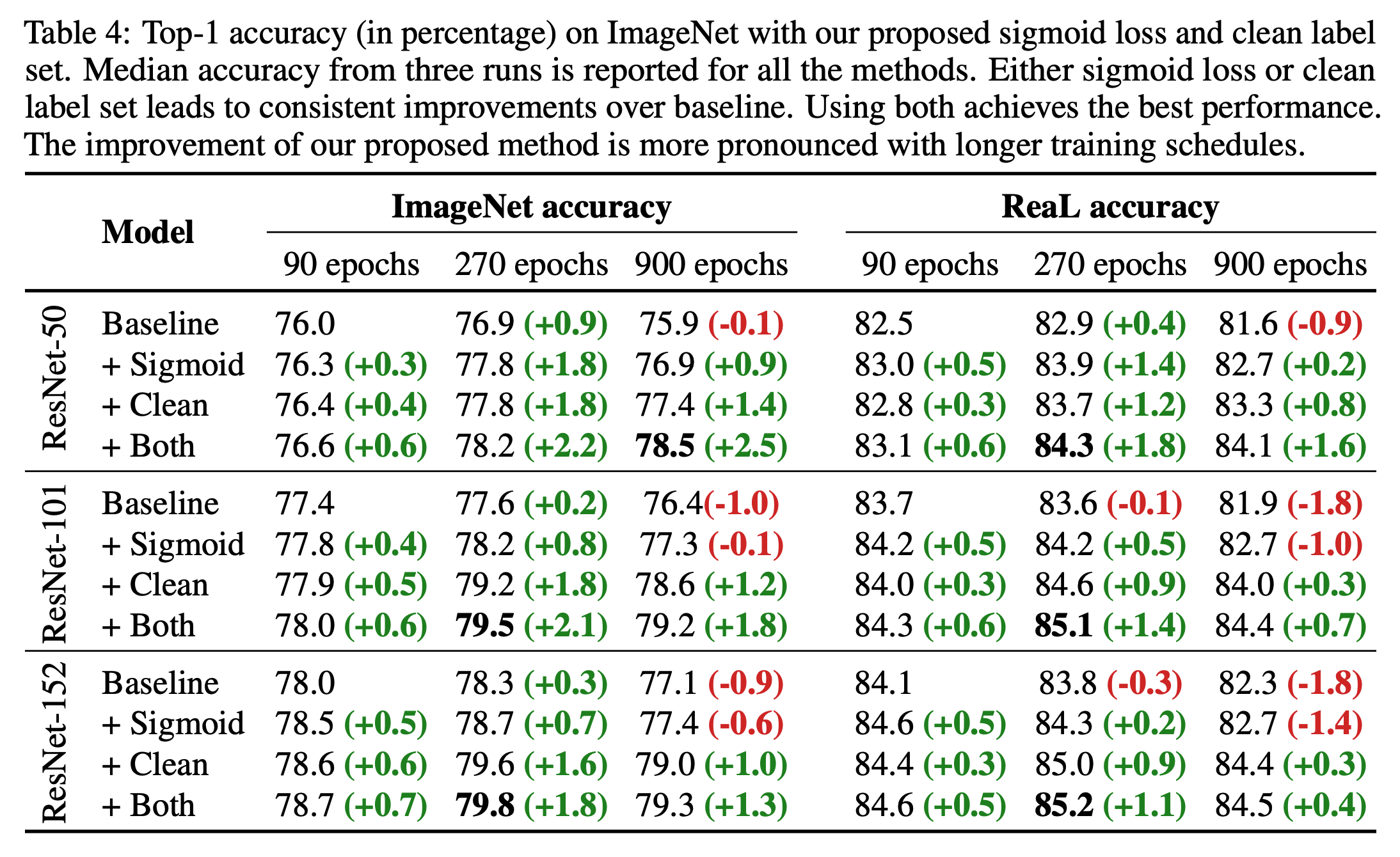
- ResNet 모델에 대해 학습시 개선점을 적용했을 때의 정확도
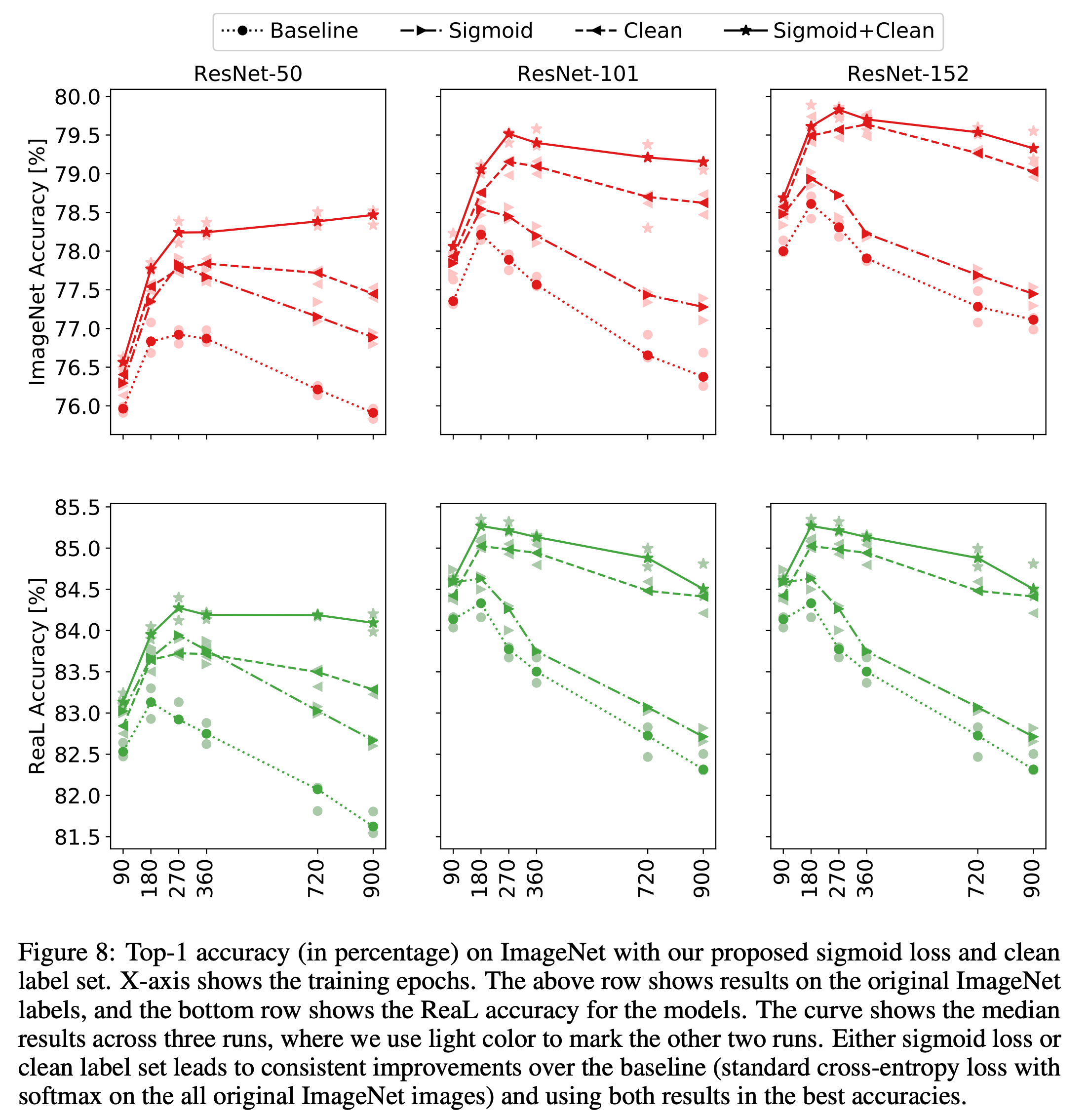
- 각 모델의 정확도